

{kind=link}
Despite accumulating a trove of data from buyer help calls, extracting valuable insights from these recordings proves to be a laborious and time-consuming task. Consider distilling complex audio transcripts into concise overviews, noting how sentiment evolves throughout the conversation, and extracting tailored insights according to your desired analysis approach. Sounds helpful?
Here is the rewritten text:
In this article, we’ll explore building a practical tool I created, SnapSynapse, designed to achieve that exact purpose. By leveraging cutting-edge tools such as speaker diarization technologies to identify unique voices, advanced transcription software to capture spoken content, and AI-powered summarization platforms to distill key findings, I will demonstrate a straightforward approach to automating the process of converting help desk audio recordings into valuable insights that inform decision-making. Throughout this process, users will discover techniques for streamlining and refining transcriptions, creating tailored summaries based on user input, and analyzing sentiment patterns – all accompanied by straightforward, actionable code examples. Here’s the improved text:
This practical guide equips you with the skills to build a device that surpasses traditional transcription, empowering you to refine and elevate your customer service capabilities.
Studying Targets
- Utilize pyannote.audio’s SpeakerDiarization module to efficiently extract and isolate distinct voices from customer support recordings, thereby enhancing audio analysis capabilities.
- Develop algorithms to accurately transcribe audio files using Whisper, and then refine the output by removing filler words and extraneous text.
- Discover ways to craft bespoke summaries leveraging Gemini-1.5 Professional, boasting adjustable prompts tailored to various assessment requirements?
- Uncover techniques for analyzing conversational patterns and visualizing sentiment characteristics across a single identity.
- Develop hands-on proficiency in building an automated pipeline that extracts meaningful insights from audio data, streamlining the analysis of customer support conversations.
What’s SnapSynapse?
SnapSynapse enables businesses to transform customer support interactions into actionable intelligence, empowering data-driven decision making. The platform efficiently dissects conversations by speaker, meticulously transcribing each utterance while capturing the underlying tone and crucial factors, thereby enabling groups to swiftly grasp clients’ needs. Leveraging cutting-edge tools like Pyannote for diarization, Whisper for transcription, and Gemini for summaries, SnapSynapse provides lucid overviews and sentiment insights with ease. Designed to bridge the gap between client-facing teams and enhance overall service delivery, this innovative solution fosters meaningful connections through seamless dialogue.
Key Options
SnapSynapse’s core features include:
- Speaker diarization/identification
- Dialog transcript era
- Time Stamps era dialogue sensible
- How do we bridge the gap between user needs and technical requirements?
- Sentiment Evaluation scores
- As a crucial component in Natural Language Processing (NLP), sentiment evaluation plays a pivotal role in gauging the emotional tone of unstructured text data. By leveraging the power of visualization, we can effectively illustrate the nuances of sentiment across various datasets.
One popular approach is to utilize word clouds that display the most frequently occurring words and phrases in relation to their corresponding sentiment scores. This visual representation enables analysts to quickly identify patterns and trends, facilitating a more accurate understanding of the overall sentiment landscape.
Another innovative method involves creating heat maps that illustrate the sentiment distribution across different segments or categories. This visualization technique empowers users to pinpoint areas with high positivity or negativity, allowing for targeted analysis and decision-making.
Furthermore, Sankey diagrams can be employed to visualize the sentiment flow between different entities, such as products, services, or topics. By tracing the sentiment trajectory, analysts can uncover underlying patterns and correlations that may not be immediately apparent through traditional statistical methods.
In conclusion, visualization is a potent tool in sentiment evaluation, offering a range of innovative techniques for extracting valuable insights from unstructured text data.
What drives the development of innovative neural networks? The answer lies in the intricacies of SnapSynapse’s core options and performance.
To create a comprehensive framework for building and optimizing deep learning models, it is essential to carefully consider the fundamental components that make up the SnapSynapse architecture.
Discovering the fundamental features that propel SnapSynapse as a comprehensive tool for customer support analysis. By transforming mechanical call logging and transcription processes into interactive summary generation tools, we can significantly enhance the productivity of support teams. By harnessing the power to identify sentiment patterns and provide data-driven recommendations, SnapSynapse streamlines the process of grasping customer feedback.
If you want to attempt the full supply code, consult the records and data available in the repository.
To successfully execute this project, we’ll require access to both the OpenAI API and Gemini API. APIs will be provided directly here.
speaker diarization -> transcription -> time stamps -> cleansing -> summarization -> sentiment evaluation
Speaker Diarization and Transcription Revolutionizes Era of Communication
To initiate the process, a solitary script is employed, utilizing its capabilities to dissect an audio file into three distinct components: diarizing the audio stream, generating a precise transcription of spoken content, and accurately assigning timestamps to each utterance. Here’s the function and main capabilities:
Overview of the Script
This script accomplishes three primary tasks simultaneously:
- The audio processing software successfully detects distinct audio streams within the audio file, accurately isolating and extracting separate tracks of dialogue for further analysis or manipulation as needed.
- Transforms disparate spoken audio recordings into written transcripts.
- Timestamped conversation:
0:00
What do you think about our current marketing strategy?1:45
Honestly, I’m not sure what the goal is. Can we clarify that?2:10
Exactly! The objective should be well-defined. Maybe we can discuss the target audience and the key performance indicators.3:20
I agree. What are some potential issues with our existing approach?4:15
Well, for one thing, I think we’re relying too heavily on social media without measuring its impact effectively.
Imports and Setup
- We start by importing essential libraries such as pyannote.audio for speaker diarization, openai for transcription, and pydub to deal with audio segments.
- Using dotenv for setting variables allows us to securely store our OpenAI API key.
Major Performance: Automated Speech-to-Text with Time Stamps – Advanced Diarization and Transcription Capabilities.
The core operate, transcribe_with_diarization()Comprises a single unified process that integrates all necessary actions.
- Calls perform_diarization() to get speaker segments.
- Makes use of pydub To segment an audio file into manageable portions by leveraging each phase’s start and end timestamps.
- The Whisper mannequin is invoked with each block. OpenAI’s API to get textual content transcriptions.
- Timestamp and Speaker Information: Each transcription is preserved with its associated start time, end time, and designated speaker label.
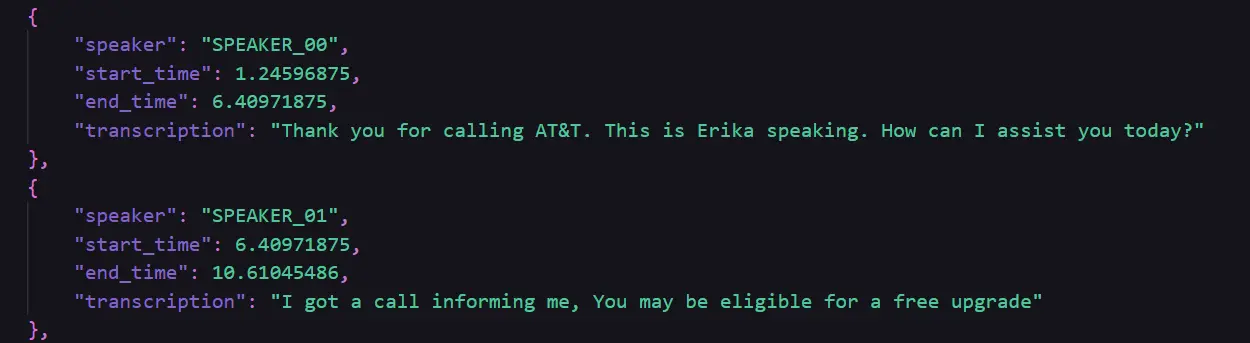
def transcribe_with_diarization(file_path): diarization_result = perform_diarization(file_path) audio = AudioSegment.from_file(file_path) transcriptions = [] for phase, _, speaker in diarization_result.itertracks(yield_label=True): start_time_ms = int(phase.begin * 1000) end_time_ms = int(phase.finish * 1000) chunk = audio[start_time_ms:end_time_ms] chunk_filename = f"{speaker}_segment_{int(phase.begin)}.wav" chunk.export(chunk_filename, format="wav") transcription = consumer.audio.transcriptions.create( mannequin="whisper-1", file=open(chunk_filename, "rb"), response_format="json" ) transcriptions.append({ "speaker": speaker, "start_time": phase.begin, "end_time": phase.finish, "transcription": transcription["text"] }) print(f"Transcription for {chunk_filename} by {speaker} complete.") Saving the Output
- The comprehensive transcriptions, accurately attributed to their respective speakers, along with precise timestamp information, are stored in diarized_transcriptions.jsonCreating a formatted file for the conversation.
- Ultimately, we execute an operation on a reference audio file, test_audio_1.wav, to verify the combined functionality of diarization and transcription in real-time.
The transcription data was successfully processed and stored in the `diarized_transcription.py` file.
The transcription cleaning process ensures that generated transcripts are free from errors and ready for downstream analysis. This stage typically involves correcting punctuation marks, removing unnecessary whitespace, and handling inconsistencies in capitalization.
- The file aims to purify transcriptions derived from a diarization and transcription program.
- The software processes diarized transcriptions from a JSON file, eliminating common filler phrases (“um,” “uh,” “”) to improve readability.
- Furthermore, this process removes excessive whitespace and refines the text’s clarity, ultimately producing a more streamlined and refined transcript.
- After cleansing, the system saves the newly generated transcriptions to a JSON file called cleaned_transcriptions.py, ensuring that the data is accurately prepared for further analysis or machine learning applications.
def clean_transcription(text): filler_words = ["um", "uh", "like", "you know", "actually", "basically", "I mean", "sort of", "kind of", "right", "okay", "so", "well", "just"] filler_pattern = re.compile('|'.join(map(re.escape, filler_words)), re.IGNORECASE) cleaned_text = filler_pattern.sub('', text) return ' '.join(cleaned_text.split())The abstract will be concise and clear?
Summary of findings will be accurately presented?
Subsequent steps involve leveraging the Gemini API to generate structured insights and summaries by processing the cleaned transcriptions in a manner that yields actionable information. Using our advanced Gemini 1.5 professional mannequin, we leverage pure language processing capabilities to analyze buyer help calls and generate insightful summaries with tangible takeaways.
Here’s a summary of the performance:
- Mannequin Setup: The Gemini mannequin is implemented using Google’s Generative AI library, with its API key securely integrated. The tool enables generating insights largely driven by distinct, real-time formats.
- Prompts for Evaluation: Predefined prompts are crafted to investigate various aspects of the support name, encompassing typical summary formats, speaker interactions, customer complaints, resolution outcomes, escalation requirements, and technical issue troubleshooting approaches.
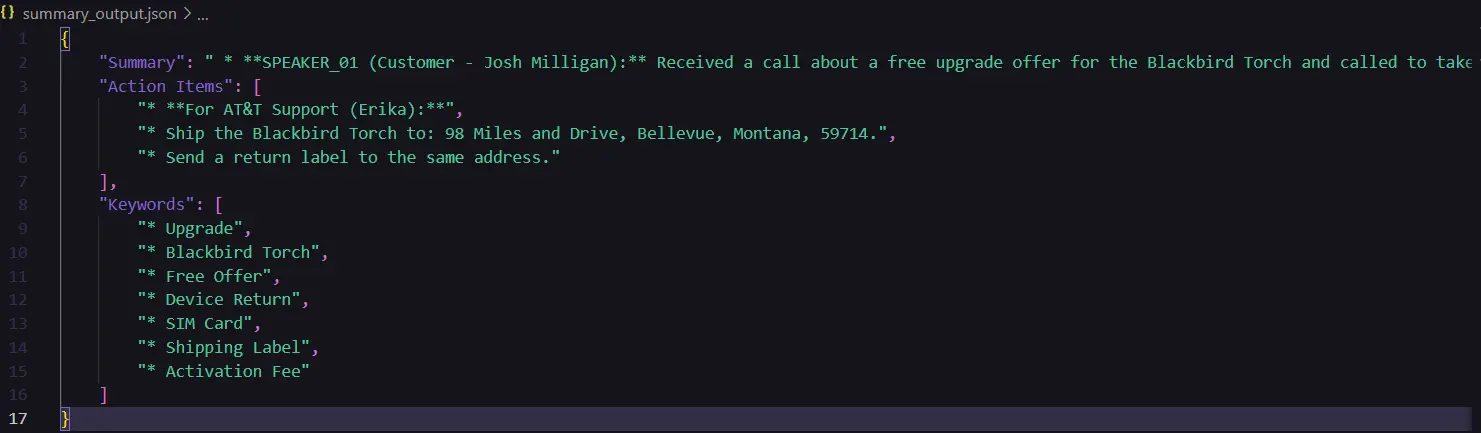
- Generate Structured Content material: The operate generate_analysis() Processes the cleaned transcription to generate coherent and accurate textual content based on predefined prompts. The report distils its findings into three distinct categories: Abstract, Technical Capabilities, and Core Concepts.
- Person Interplay: The script allows consumers to choose from a variety of abstract codecs for selection. The consumer’s preferred alternative dictates which interpreter is utilized to derive valuable insights from the transcription.
- Output EraAfter processing the transcription, the resulting insights are then formatted into a structured JSON file for easy access and analysis. This structured information simplifies data extraction for help groups by facilitating easy retrieval of key details from the decision.
Here are a few examples of various prompts that might be used:
? Creative writing exercises, such as describing a sunrise, could include vivid sensory details like the warmth on your skin or the sweet scent of blooming flowers.
? A list of common idioms and phrases with their meanings would provide a helpful reference for language learners.

What drives innovation in technological advancements?
Step 4: Sentiment Evaluation
We conduct sentiment analysis on customer support call transcriptions to assess the emotional tone throughout the conversation. Utilizing NLTK’s sentiment evaluation device, this text determines sentiment scores for each phase of dialogue.
The following is a detailed outline of the approach:
- Sentiment Evaluation Utilizing VADERThe script leverages SentimentIntensityAnalyzer from the VADER (Valence-Conscious Dictionary and Sentiment Reasoner?) lexicon. assigns a sentiment rating to each phase, comprising a compound rating that captures the overall sentiment.optimistic, impartial, or detrimental).
- Processing Transcription: The cleaned transcription is accurately imported from a JSON-formatted data source. Each entry in the transcription is meticulously assessed for sentiment, and the results are stored along with the speaker’s identifier and associated sentiment metrics. The script calculates the comprehensive sentiment rating, the representative sentiment for both the shopper and the help agent, and classifies the overall sentiment as either Optimistic, Neutral, or Unfavorable.
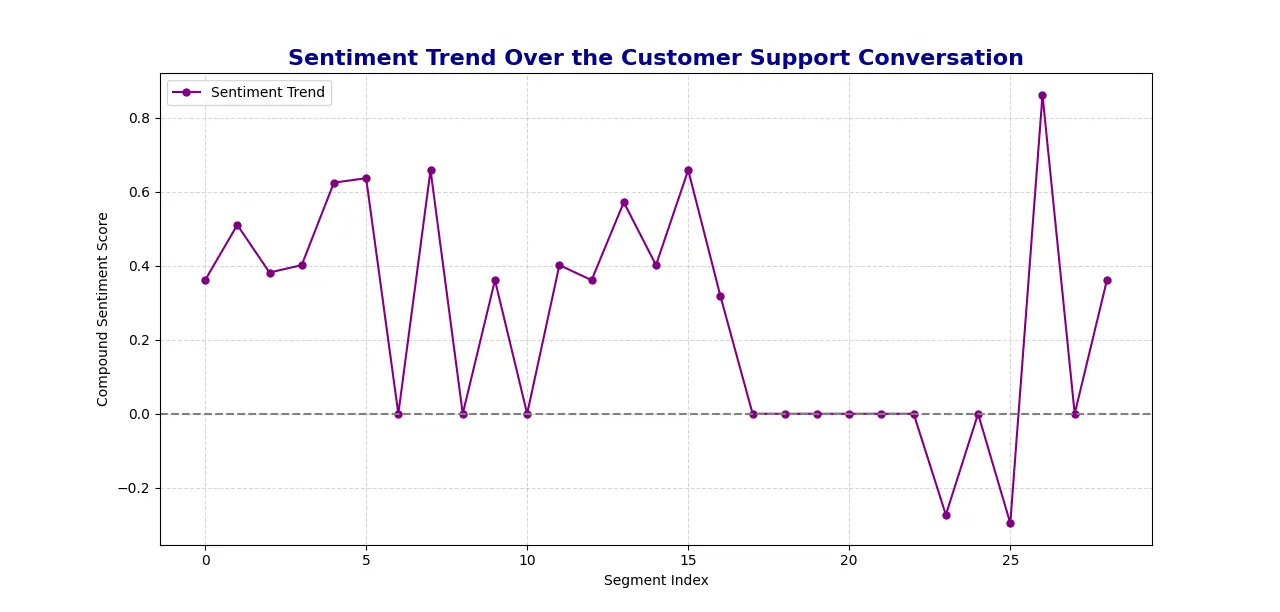
- Sentiment Development VisualizationUsing Matplotlib, the script produces a line graph illustrating the evolution of sentiment over time, featuring the dialogue segments along the x-axis and the corresponding sentiment ratings on the y-axis.
- Output: The system stores the sentiment analysis results, including numerical scores and overall sentiment, in a JSON file for convenient access and review at a later time. The analysis effectively depicts the sentiment pattern through a graphical representation, providing insight into the emotional fluctuations associated with each name.
The following Python code calculates the overall sentiment of a given sentence:
“`python
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
nltk.download(‘vader_lexicon’)
def calculate_sentiment(sentence):
sia = SentimentIntensityAnalyzer()
sentiment_scores = sia.polarity_scores(sentence)
return sentiment_scores[‘compound’]
sentence = “I am very happy with this product.”
sentiment_rating = calculate_sentiment(sentence)
print(“The overall sentiment rating is: “, sentiment_rating)
“`
SKIP
# Calculate the general sentiment rating overall_sentiment_score = total_compound / len(sentiment_results) # Calculate common sentiment for Buyer and Agent average_customer_sentiment = customer_sentiment / customer_count if customer_count else 0 average_agent_sentiment = agent_sentiment / agent_count if agent_count else 0 # Decide the general sentiment as optimistic, impartial, or detrimental if overall_sentiment_score > 0.05: overall_sentiment = "Optimistic" elif overall_sentiment_score < -0.05: overall_sentiment = "Unfavourable" else: overall_sentiment = "Impartial"The original code snippet appears to be a Python script designed to generate a plot using the matplotlib library. The code includes several lines of code that import necessary modules, define functions, and create a plot with specific features such as title, labels, and gridlines.
Here’s an improved version:
“`python
import matplotlib.pyplot as plt
def plot_function(x_values):
y_values = [x**2 for x in x_values]
return y_values
x = range(-10, 11)
y = plot_function(x)
plt.plot(x, y)
plt.title(“Plot of X^2”)
plt.xlabel(“X-axis”)
plt.ylabel(“Y-axis”)
plt.grid(True)
plt.show()
“`
plt.figure(figsize=(12, 6)) plt.plot([entry['sentiment']['compound'] for entry in sentiment_results], color='purple', linewidth=1, marker='o', markersize=5, label='Sentiment Development') plt.axhline(y=0, color='gray', linestyle='--') plt.title('Buyer Help Dialog Sentiment Evolution', fontsize=16, fontweight='bold', color='darkblue') plt.xlabel('Phase Index') plt.ylabel('Compound Sentiment Score') plt.grid(True, linestyle='--', alpha=0.5) plt.legend() plt.show()Sentiment Evaluation Scores generated:

Sentiment Evaluation Plot generated:
What’s Your SnapSynapse Journey? Setting Up for Success
The code repository is readily available for your perusal, located right here.
Here are the steps to set up and run SnapSynapse on your local machine:
Step1: Clone the Repository
Clone the undertaking repository to your local machine to get started with SnapSynapse. The following provides access to the appliance’s supply code and all its vital components.
git clone https://github.com/Keerthanareddy95/SnapSynapse.git cd SnapSynapseStep2: Setup the Digital Setting
A well-designed digital environment enables seamless collaboration by isolating dependencies, thereby ensuring a smooth project execution. This step isolates a neutral environment for SnapSynapse to operate without interference from other applications.
For Windows: python -m venv myvenv For macOS and Linux: python3 -m venv myvenvStep3: Activate the Digital Setting
# For Windows: .\\Scripts\\activate # For macOS and Linux: source venv/bin/activateStep4: Set up Required Dependencies
With the digital atmosphere established, the next step is to incorporate essential libraries and tools. The following dependencies enable the core features of SnapSynapse, encompassing transcript generation, speaker diarization, timestamp creation, abstract summarization, sentiment analysis scoring, visualization, and additional capabilities.
pip set up -r necessities.txt Step5: Arrange the Setting Variables
To fully capitalize on AI-driven capabilities, including diarization, transcription, and summarization, you will need to set up API keys for both Google’s Gemini and OpenAI’s Whisper.
Create a .env File within the project’s root directory and add your API keys for Google’s AdWords (formerly Gemini) and OpenAI’s Whisper API.
GOOGLE_API_KEY="your_google_api_key" OPENAI_API_KEY="your_open_ai_api_key"Step6: Run the Software
- The file facilitates transcription of audio recordings, speaker identification, and timestamping of spoken segments. The output is saved in a JSON file named “diarized_transcriptions.json”.
- Run the cleansing.py file subsequently, the file takes diarized_transcriptions.py The transcription is processed to remove unnecessary formatting, and the resulting output is saved in a JSON file named cleaned_transcription.json.
- It’s unclear what you’re trying to improve. Please provide more context or clarify what you’d like me to do with the text. If I’m unable to improve the text based on the information provided, my answer would be “SKIP”. GEMINI API key. This file will take the cleaned_transcription.py The application files an abstract prompt for the user, prompting them to input the type of abstract they desire to create, dependent on their specific use case. Based on consumer input, the system promptly transmits the relevant information to GEMINI, thereby producing an abstract. The system stores the generated abstract in a JSON file named.
summary_output.json. - Last, execute the sentiment_analysis.py script: This file generates general sentiment scores and, in addition, produces a graphical representation of the sentiment evaluation scores as well as their progression over the audio file duration.
The instruments employed in fostering SnapSynapse’s development are as follows:
- Provides a Pipeline module that enables speaker diarization, allowing users to isolate distinct audio streams within an audio file.
- Utilized in conjunction with OpenAI’s API for transcription purposes via the Whisper model.
- Processes audio recordings, enabling segmentation and export of distinct audio segments by speaker.
-
A library of Google Gemini fashions is utilized here to produce structured summaries and insights from customer support transcripts.
-
The Pure Language Toolkit provides a library for pure language processing, which is leveraged in this instance to import the SentimentIntensityAnalyzer from the VADER toolkit and analyze sentiment within an audio file.
- A popular data visualization library, particularly paired with `plt`, is seamlessly integrated within this code to effectively visualize the sentiment throughout an audio file.
Conclusion
SnapSynapse pioneers the transformation of raw audio recordings from customers into tangible, data-driven insights for enhanced buying experiences. SnapSynapse simplifies the process of capturing buyer insights by seamlessly integrating speaker diarization and transcription with advanced analysis capabilities, ultimately delivering a comprehensive understanding of customer interactions through its structured abstracts and sentiment evaluations. With its tailored prompts and advanced sentiment analysis capabilities, the Gemini mannequin empowers customers to effortlessly access concise summaries and insightful reports highlighting crucial findings and actionable recommendations.
We would like to extend our sincerest gratitude to Google Gemini, Pyannote Audio, and Whisper for their groundbreaking technologies that made this project possible.
You’ll have the opportunity to explore the repository.
Key Takeaways
- SnapSynapse enables clients to streamline customer service interactions from start to finish by capturing details, transcribing conversations, and generating concise summaries.
- Customers can personalise summaries with five distinct immediate options, catering to specific needs by focusing on key aspects, motion graphics, or technical support. The innovative function empowers learners to uncover instant insights into engineering and experientially test the effects of varied inputs on AI-generated results.
- SnapSynapse monitors sentiment characteristics throughout conversations, providing a transparent visual representation of tone fluctuations to help customers better gauge customer satisfaction. By harnessing natural language processing techniques, students gain valuable experience in deciphering the nuances of sentiment analysis and applying these insights to practical applications.
- SnapSynapse streamlines the transcription process by cleaning up and evaluating audio recordings, providing buyers with instant access to actionable insights that inform swift, data-driven decisions. Students reap benefits by observing how automation simplifies information management, enabling them to focus on valuable inferences rather than mundane tasks.
Incessantly Requested Questions
A. SnapSynapse effectively processes audio files in both MP3 and WAV formats.
A. SnapSynapse leverages Whisper’s transcription capabilities, followed by a rigorous editing process that eliminates filler phrases, pauses, and extraneous content to produce high-quality output.
A. Sure! SnapSynapse offers five unique instant options, empowering users to select an abstract format tailored precisely to their specific needs. These entities encompass key domains such as kinematic objects, prioritized escalations, and technological considerations.
A. SnapSynapse’s advanced sentiment analysis technology evaluates the emotional tone of conversations, providing a comprehensive sentiment rating and intuitive pattern graph that reveals subtle nuances in human emotion.
A. The Buyer Name Evaluation platform leverages cutting-edge AI technology to accurately transcribe, scrutinize, and distill valuable data from customer conversations, empowering businesses to refine their services, identify key characteristics, and ultimately boost customer satisfaction rates.
A. Through buyer name evaluations, organisations can gain a profound comprehension of buyer sentiment, pinpoint widespread pain points, and assess agent effectiveness, ultimately leading to more informed decisions and enhanced customer service strategies.