
{kind=link}
In a brand new examine co-authored by Apple researchers, an open-source giant language mannequin (LLM) noticed large efficiency enhancements after being instructed to test its personal work through the use of one easy productiveness trick. Listed here are the small print.
A little bit of context
After an LLM is educated, its high quality is normally refined additional by way of a post-training step often known as reinforcement studying from human suggestions (RLHF).
With RLHF, each time a mannequin offers a solution, human labelers can both give it a thumbs up, which rewards it, or a thumbs down, which penalizes it. Over time, the mannequin learns which solutions are likely to render essentially the most thumbs up, and its total usefulness improves because of this.
A part of this post-training part is tied to a broader subject referred to as “alignment”, which explores strategies for making LLMs behave in methods which are each useful and protected.
A misaligned mannequin might, for example, learn to trick people into giving it a thumbs-up by producing outputs that look right on the floor however that don’t really remedy the duty.
There are, after all, a number of strategies to enhance a mannequin’s reliability and alignment throughout the pre-training, coaching, and post-training steps. However for the needs of this examine, let’s follow RLHF.
Apple’s examine
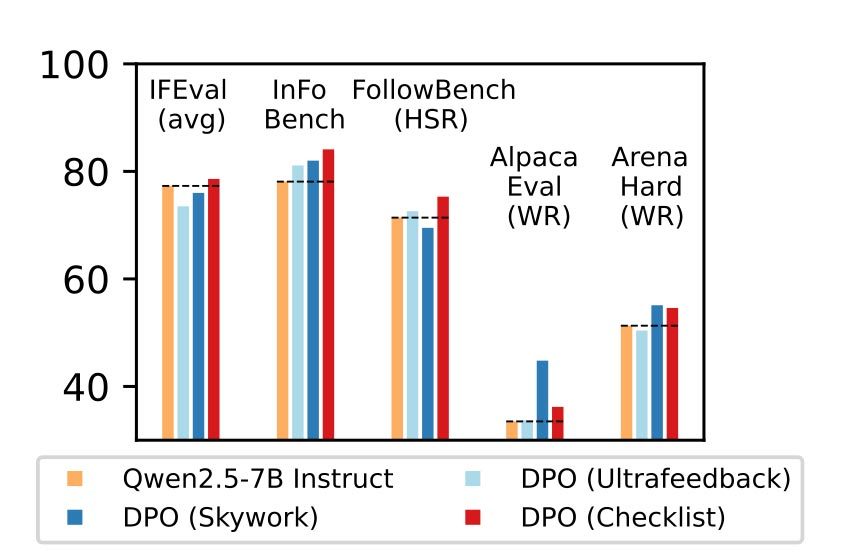
Within the examine aptly entitled Checklists Are Higher Than Reward Fashions For Aligning Language Fashions, Apple proposes a checklist-based reinforcement studying scheme, referred to as Reinforcement Studying from Guidelines Suggestions (RLCF).

RLCF scores responses on a 0–100 scale for the way properly they fulfill every merchandise within the guidelines, and the preliminary outcomes are fairly promising. Because the researchers clarify it:
“We evaluate RLCF with different alignment strategies utilized to a powerful instruction following mannequin (Qwen2.5-7B-Instruct) on 5 widely-studied benchmarks – RLCF is the one technique to enhance efficiency on each benchmark, together with a 4-point increase in laborious satisfaction fee on FollowBench, a 6-point enhance on InFoBench, and a 3-point rise in win fee on Enviornment-Arduous. These outcomes set up guidelines suggestions as a key instrument for enhancing language fashions’ help of queries that specific a large number of wants.”
That final bit is especially fascinating relating to AI-powered assistants, that are certain to change into the usual underlying interface by way of which tens of millions of customers will work together with their gadgets going ahead.
From the researchers, once more:
Language fashions should comply with person directions to be helpful. As most people integrates language model-based assistants into their completion of every day duties, there may be an expectation that language fashions can faithfully comply with the customers’ requests. As customers develop extra confidence in fashions’ skill to meet complicated requests, these fashions are more and more given wealthy, multi-step directions that require cautious consideration to specs.
Producing the precise guidelines
One other significantly fascinating side of the examine is how every guidelines is created, and the way the significance weights are assigned between every merchandise.
That’s completed, after all, with the assistance of an LLM. Based mostly on work by earlier research, Apple’s researchers generated “checklists for 130,000 directions (…) to create a brand new dataset, WildChecklists. To generate candidate responses for our technique, we use Qwen2.5-0.5B, Qwen2.5-1.5B, Qwen2.5-3B, and Qwen2.5-7B. Qwen2.5-72B-Instruct is the guidelines generator mannequin (…).”
Principally, the researchers robotically complement every instruction given by the person with a small guidelines of concrete sure/no necessities (for example: “Is that this translated into Spanish?”). Then, a bigger trainer mannequin scores candidate responses in opposition to every guidelines merchandise, and people weighted scores change into the reward sign used to fine-tune the scholar mannequin.
Outcomes and limitations
With the precise techniques in place to create the most effective guidelines doable for every immediate, the researchers noticed as much as an 8.2% achieve in one of many benchmarks it examined its technique. Not solely that, however this resolution additionally led in a number of different benchmarks, when in comparison with different strategies.

The researchers level out that their examine centered on “complicated instruction following”, and that RLCF will not be the most effective reinforcement studying method for different use circumstances. Additionally they point out that their technique employs a extra highly effective mannequin to behave as a choose for tuning a smaller mannequin, in order that’s additionally an vital limitation. And maybe most significantly, they clearly state that “RLCF improves complicated instruction following, however shouldn’t be designed for security alignment.”
Nonetheless, the examine presents an fascinating novel (however easy) manner to enhance reliability in what is going to most likely be probably the most essential points of the interplay between people and LLM-based assistants going ahead.
That turns into much more crucial contemplating these assistants will more and more get agentic capabilities, the place instruction following (and alignment) shall be key.
Restricted time Apple Watch offers on Amazon
FTC: We use revenue incomes auto affiliate hyperlinks. Extra.
