

{kind=link}
Amazon OpenSearch Serverless simplifies the deployment and administration of OpenSearch workloads by routinely scaling based mostly in your utilization patterns. The service considers key metrics similar to shard utilization, storage consumption, and CPU utilization whereas sustaining millisecond-level response instances, with the simplicity of a serverless setting.
Whereas OpenSearch Serverless handles scaling routinely, implementing sturdy monitoring stays essential for understanding utilization patterns, optimizing prices, serving to to make sure efficiency, and sustaining reliability. Proactive monitoring helps organizations detect important points with the functions or infrastructure in actual time and determine root causes shortly.
This put up is a part of our Amazon OpenSearch service monitoring sequence, specializing in OpenSearch Serverless workloads and deployments. On this put up, we discover generally used Amazon CloudWatch metrics and alarms for OpenSearch Serverless, strolling by the method of choosing related metrics, setting applicable thresholds, and configuring alerts. This information will give you a complete monitoring technique that enhances the serverless nature of your OpenSearch deployment whereas sustaining full operational visibility.
Key advantages of CloudWatch monitoring for OpenSearch Serverless
Implementing CloudWatch monitoring in your OpenSearch Serverless collections gives a number of key benefits:
- Close to real-time efficiency monitoring – CloudWatch supplies close to real-time monitoring, enabling you to trace your OpenSearch Serverless collections’ efficiency as they function. This speedy visibility permits for swift detection of anomalies or efficiency points, enabling immediate response to potential issues.
- Environment friendly error prognosis – You may shortly determine and handle widespread errors with out in depth log evaluation. For example, by monitoring ingestion request errors, you possibly can preemptively mitigate bulk indexing request failures.
- Proactive alerting system – Use the CloudWatch alarm performance along with Amazon Easy Notification Service (SNS) to arrange customized alerts. By defining particular thresholds for important metrics, you possibly can obtain instantaneous notifications by electronic mail or SMS when your OpenSearch Serverless collections method or exceed these limits.
- Complete historic evaluation – The information retention capabilities of CloudWatch enable for in-depth historic evaluation. This lets you determine long-term efficiency developments, acknowledge recurring patterns in useful resource utilization and optimize workload distribution based mostly on historic insights.
Resolution overview
Understanding which metrics to observe in OpenSearch Serverless helps optimize your system’s efficiency and reliability. This information explains the important thing metrics to observe, their significance, the best way to decide applicable thresholds, and the step-by-step course of for establishing alarms. Understanding these fundamentals will assist you to set up efficient monitoring in your OpenSearch Serverless collections and assist preserve optimum efficiency and reliability.
Conditions
Earlier than getting began, you have to have the next conditions:
CloudWatch metrics and advisable alarms for OpenSearch Serverless
The next desk summarizes key CloudWatch metrics for OpenSearch Serverless, together with advisable alarm thresholds, metric descriptions, and relevant workload varieties.
| Alarm | Metric Stage | Metric Description | Alarm Description | Use case |
| IndexingOCU most is >= 10 for five minutes, three consecutive instances | Account Stage | Serverless compute capability is measured in OpenSearch Compute Models (OCUs). Every OCU is a mix of 6 GiB of reminiscence and corresponding digital CPU (vCPU), along with knowledge switch to Amazon Easy Storage Service (Amazon S3). The IndexingOCU metric stories the variety of OCUs used for knowledge ingestion throughout all collections. | This alarm will warn you when Indexing OCUs scale upto / past 10 for greater than quarter-hour. | Monitor and Optimize Prices |
| SearchOCU most is >= 10 for five minutes, three consecutive instances | Account Stage | Serverless compute capability is measured in OCUs. Every OCU is a mix of 6 GiB of reminiscence and corresponding digital CPU (vCPU), along with knowledge switch to Amazon S3. The SearchOCU metric stories the variety of OCUs used to look assortment knowledge throughout all collections. | This alarm will warn you when Search OCUs scale upto / past 10 for greater than quarter-hour. | Monitor and Optimize Prices |
| IngestionRequestLatency most is >= 3 secs for 1 minutes, 5 consecutive instances. | Assortment Stage | The IngestionRequestLatency metric stories the latency, in seconds, for bulk write operations to a set. | This alarm screens the utmost latency of bulk write operations to a set. It triggers when the utmost IngestionRequestLatency exceeds 3 seconds for 5 consecutive 1-minute intervals (for a complete of 5 minutes). This means a sustained efficiency degradation in knowledge ingestion operations, which may affect software efficiency and knowledge availability. | This metric is likely to be essential to observe for log-based workloads, the place indexing time is important. |
| SearchRequestLatency most is >= 2 secs for 1 minutes, 5 consecutive instances. | Assortment Stage | The SearchRequestLatency metric stories the latency, in seconds, that it takes to finish a search operation towards a set. | This alarm screens the utmost latency of search operations towards a set. It triggers when the utmost SearchRequestLatency exceeds 2 seconds for 5 consecutive 1-minute intervals (for a complete of 5 minutes). Persistently excessive search latency signifies efficiency points that would degrade person expertise and software responsiveness. | This metric is likely to be essential to observe for vector and search-based workloads, the place search time is important. |
| IngestionRequestErrors sum is >= 100 errors for 1 minute, 5 consecutive instances | Assortment Stage | The IngestionRequestErrors metric stories the whole variety of bulk indexing request errors to a set. OpenSearch Serverless emits this metric when there are bulk indexing request failures, similar to an authentication or availability concern. | This alarm screens the whole depend of failed bulk indexing operations to a set. It triggers when the variety of IngestionRequestErrors equals or exceeds 100 errors for 5 consecutive 1-minute intervals (for a complete of 5 minutes). | Persistent ingestion errors point out systemic points that would result in knowledge loss or inconsistency. |
| SearchRequestErrors sum is >= 50 errors for 1 minute, 5 consecutive instances | Assortment Stage | The SearchRequestErrors metric stories the whole variety of question errors per minute for a set. | This alarm screens the whole depend of failed search question operations in a set. It triggers when the variety of SearchRequestErrors equals or exceeds 50 errors for 5 consecutive 1-minute intervals (for a complete of 5 minutes). | Persistent search errors point out potential points that would affect software performance and person expertise. |
| ActiveCollection minimal is 0 for 1 minutes, three consecutive instances. | Assortment Stage | This metric signifies whether or not a set is energetic. A price of 1 signifies that the gathering is in an ACTIVE state. This worth is emitted upon profitable creation of a set and stays 1 till you delete the gathering. The metric can’t have a worth of 0. | The alarm triggers when the metric is lacking for 3 consecutive 1-minute intervals (for a complete of three minutes). As a result of an energetic assortment all the time emits a worth of 1, lacking knowledge signifies the gathering has been deleted or is experiencing critical points. Notice: Make sure that to setup the CloudWatch alarm so that it’ll deal with lacking knowledge as breaching. | Monitor Availability of Assortment |
The particular threshold values talked about are examples. Nonetheless, chances are you’ll want to regulate these thresholds based mostly on the distinctive necessities and SLAs of your individual functions and workloads operating on OpenSearch Serverless.
To resolve when to boost the worldwide OCU limits, you need to frequently evaluation the IndexingOCU and SearchOCU metrics on the account degree. In case you discover the metrics persistently approaching the set threshold, it’s an excellent indication that you need to think about growing the general account limits to accommodate your rising utilization.
Moreover, monitor the collection-level metrics like IngestionRequestLatency and SearchRequestLatency. In case you discover sure collections have persistently excessive latency, it is likely to be an indication that the OCU allocation for these particular collections is inadequate. In such circumstances, you possibly can think about growing the OCU limits for these high-usage collections, reasonably than elevating the worldwide account limits.
By intently monitoring each the account-level and collection-level metrics, you can also make knowledgeable choices about when and the best way to modify your OCU limits to take care of optimum efficiency and value effectivity in your OpenSearch Serverless deployment.
Steps to create a CloudWatch alarm
CloudWatch Alarms could be created utilizing any of the next strategies:
Detailed steps and a / pattern code snippet for every methodology are offered within the following sections.
Utilizing the console
The AWS Administration Console supplies a user-friendly, visible interface for creating CloudWatch alarms. Comply with these step-by-step directions to arrange your alarm by the console.
- Navigate to the CloudWatch console
- Within the navigation pane, select Alarms after which, All alarms.
- Select Create alarm.
- Select Choose Metric.
- Choose the namespace AOSS
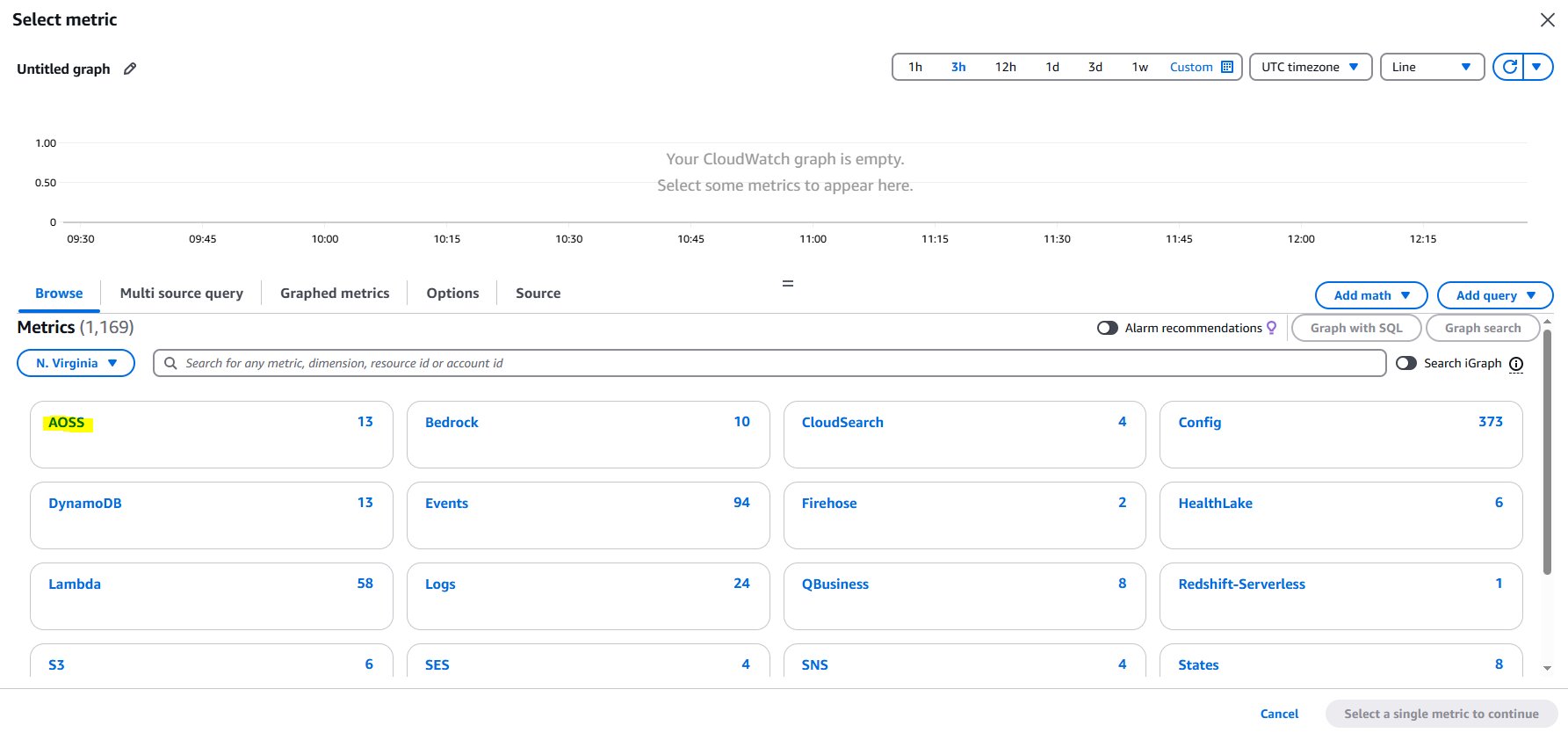
- To setup alerting on IndexingOCU throughout all collections, navigate to ClientId and choose the metric.
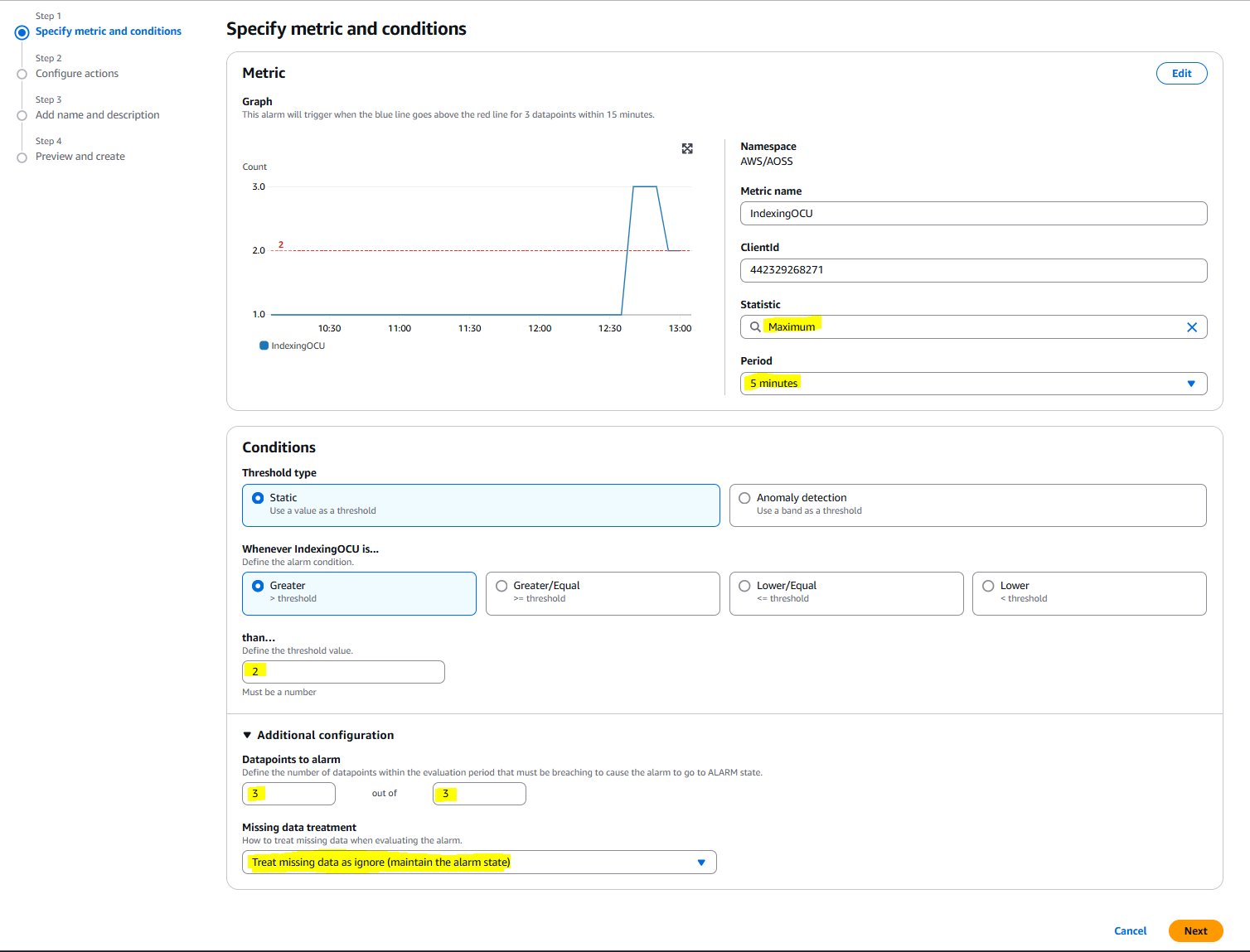
- Beneath Circumstances:
- For Statistic: Choose Most.
- For Interval: Choose 5 minutes.
- For Threshold sort: Select Static and Larger.
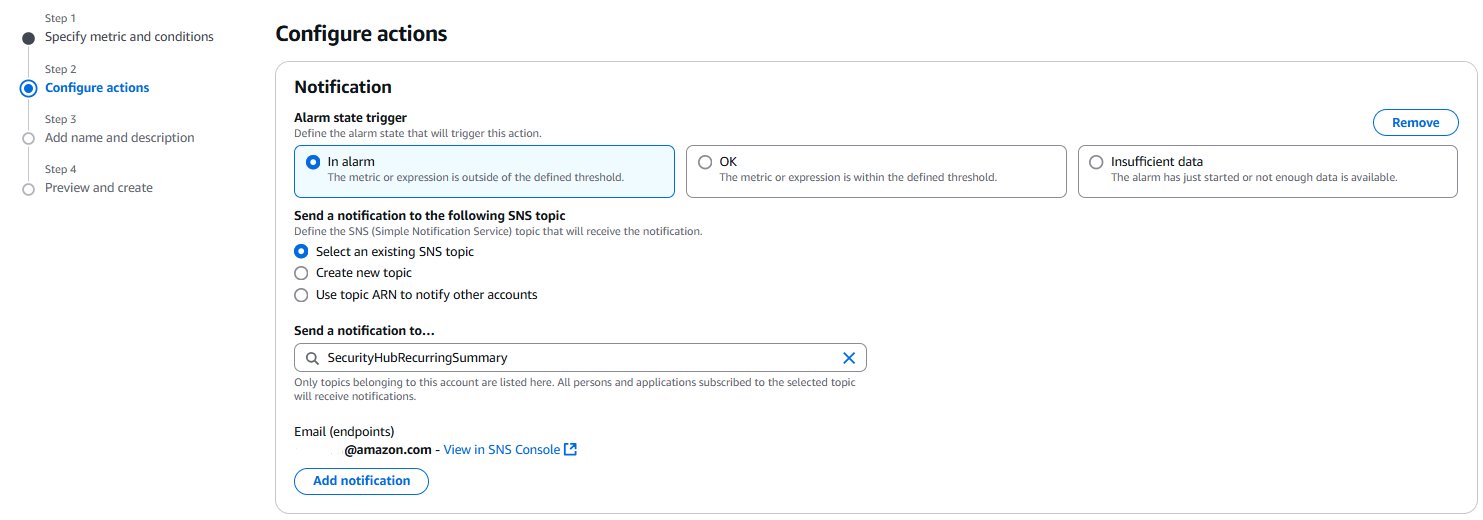
- Select Subsequent. Beneath Notification, choose an SNS subject to inform when the alarm is in
ALARMstate,OKstate, orINSUFFICIENT_DATAstate.
- When completed, select Subsequent. Enter a reputation and outline for the alarm. The identify should include solely UTF-8 characters, and might’t include ASCII management characters. The outline can embody markdown formatting, which is displayed solely within the alarm Particulars tab within the CloudWatch console. The markdown could be helpful so as to add hyperlinks to runbooks or different inner sources. Then select Subsequent.
- Beneath Preview and create, affirm that the data and situations are what you need, then select Create alarm.
For detailed documentation, check with Create a CloudWatch alarm based mostly on a static threshold.
Utilizing the AWS CLI
For many who desire command-line interfaces or must automate alarm creation, the AWS CLI gives an environment friendly various. This part demonstrates the best way to create a CloudWatch alarm utilizing a single CLI command.
To arrange a CloudWatch alarm utilizing the AWS CLI, you need to use the put-metric-alarm command. The next instance demonstrates the best way to create an alarm that sends an Amazon SNS electronic mail when the IndexingOCU exceeds 2 for quarter-hour on the account degree. Exchange [region] and [account-id] together with your AWS Area and account ID.
CloudFormation JSON
Infrastructure as Code (IaC) allows version-controlled, repeatable deployments. This JSON template reveals the best way to outline a CloudWatch alarm utilizing AWS CloudFormation, appropriate for individuals who desire JSON syntax for his or her IaC implementations.
Exchange [region] and [account-id] together with your AWS Area and account ID.
CloudFormation YAML
For groups that desire YAML’s extra readable format, this part supplies the equal CloudFormation template in YAML. The template creates the identical CloudWatch alarm with an identical configurations because the JSON model.
Exchange [region] and [account-id] together with your AWS Area and account ID.
CloudWatch dashboards
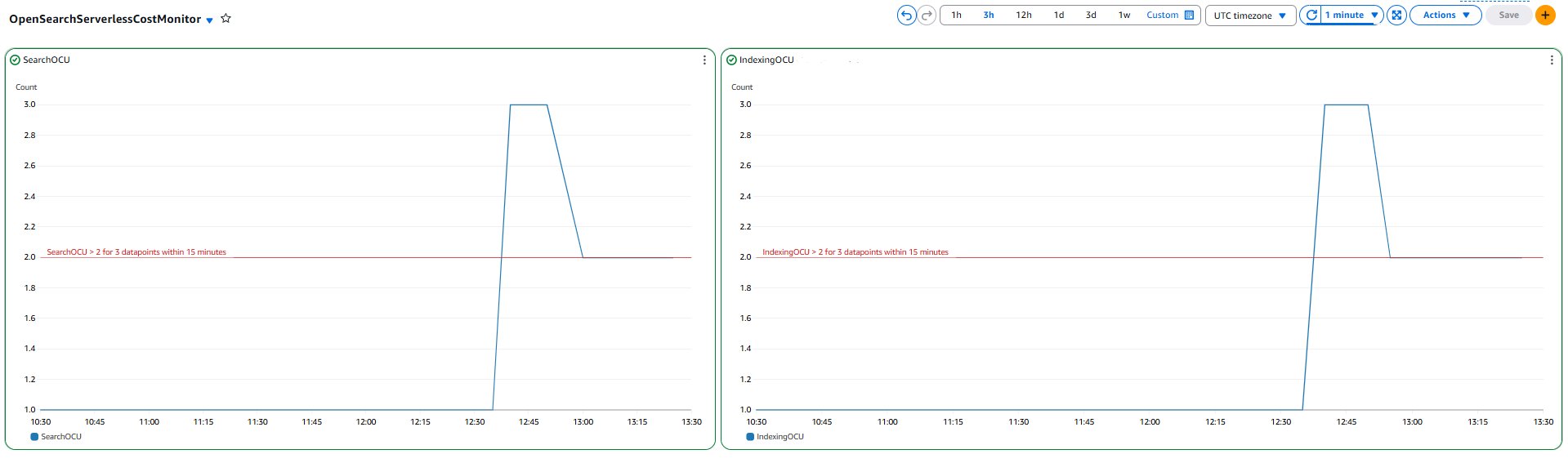
You should utilize Amazon CloudWatch dashboards to observe a number of sources in a unified view. For instance, the next dashboard supplies a consolidated view of OpenSearch Serverless OCU utilization, serving to you monitor and handle prices.
Clear up
To keep away from incurring unintended future prices, delete the next sources that have been created as a part of resolution walk-through of this put up:
- CloudWatch alarms
- CloudFormation stacks
- SNS subjects
Conclusion
Efficient monitoring helps preserve optimum efficiency and reliability of your OpenSearch Serverless collections. By implementing the CloudWatch alarms and monitoring methods outlined on this put up, you possibly can work in the direction of proactively figuring out and responding to efficiency points earlier than they affect your functions, optimize prices by monitoring OCU utilization patterns, help excessive availability goals by monitoring assortment well being and error charges, and assist preserve constant efficiency by latency monitoring. Keep in mind that the thresholds instructed on this information function a place to begin, you need to modify them based mostly in your particular use circumstances, efficiency necessities, and funds constraints. Common evaluation and refinement of those alarms will assist you to preserve an environment friendly and cost-effective OpenSearch Serverless deployment.
Associated hyperlinks
Monitoring Amazon OpenSearch Serverless
Create a CloudWatch alarm based mostly on a static threshold
Concerning the authors