

{kind=link}
Introduction
In today’s rapidly evolving software development environment, ensuring optimal application performance is crucial. By tracking real-time metrics that encompass response times, error rates, and resource utilisation, you can effectively maintain high availability and deliver a seamless user experience. Apache Pinot, an open-source OLAP data store, offers the flexibility to handle real-time knowledge ingestion and low-latency querying, making it a suitable solution for monitoring utility efficiency at scale. This article will explore how to implement a real-time monitoring system using Apache Pinot, focusing on setting up for data streaming, defining Pinot schemas and tables, querying efficiency metrics with Pinot, and visualizing metrics with tools like Grafana?

Studying Targets
- Can Apache Pinot enable the development of a real-time monitoring system for tracking utility efficiency metrics within a decentralized environment by leveraging its capabilities for handling large-scale, fast-moving data sets and providing low-latency queries?
- Querying Apache Pinot for real-time efficiency metrics with Python?
- Master hands-on skills for designing schemas, setting up tables, and processing utility metric data in real-time by leveraging Apache Pinot’s capabilities to ingest and store information directly from Kafka.
- Discover how to seamlessly integrate Apache Pinot with popular visualization tools such as Grafana or Apache Superset, unlocking the power of data storytelling and exploration.
What drives software efficiency monitoring in real-time?
Let’s examine the situation where we’re overseeing a distributed utility serving tens of thousands of customers across multiple regions. To maintain peak performance, it’s essential to track a multitude of key performance indicators.
- Response OccasionsWhat speed with which our utility responds to customer inquiries.
- Error ChargesThe error frequency in your utility’s performance.
- CPU and Reminiscence UtilizationThe resources your utility is utilizing.
Deploy Apache Pinot as a real-time monitoring system, harnessing its capabilities to ingest, store, and query vast amounts of data, thereby empowering swift identification and reaction to critical events?
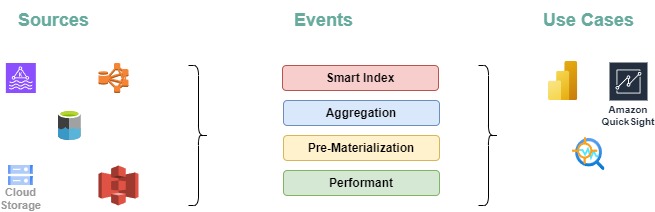
System Structure
- Information Sources:
- Data on metrics and logs is gathered from a diverse range of utility providers.
- Logs are streamed in real-time to Apache Kafka for ingestion.
- Information Ingestion:
- Apache Pinot rapidly consumes and processes knowledge from Kafka topics in real-time, minimizing latency.
- Pinning data in a columnar format optimizes query speed and eco-friendly storage for seamless retrieval.
- Querying:
- Pinot enables users to execute complex queries against real-time data, empowering them to gain valuable insights into utility efficiency.
- With its distributed architecture, Pinot enables fast query execution even as data volumes expand exponentially.
- Visualization:
- Outcomes from Pinot queries will be visualized in real-time using tools such as Grafana or Apache Superset, enabling the creation of dynamic dashboards that monitor key performance indicators (KPIs) in real-time.
- Effective visualization enables users to make data actionable by facilitating the monitoring of key performance indicators, triggering timely alerts, and responding to insights in real-time.
Real-time data processing has become increasingly crucial in today’s fast-paced business environment.
We begin by configuring Apache Kafka to handle the real-time processing of our utility’s logs and metrics in a scalable and reliable manner. Kafka is a distributed streaming platform that enables real-time publishing and subscribing to streams of information. Every microservice within our utility can generate log messages or metrics that are written to Kafka topics, subsequently consumed by Pinot.
Set up Java
To successfully run Kafka, you’ll likely need to install Java on your system.
I'm skipping this one.
Confirm the Java Model
java –model
Downloading Kafka
wget https://downloads.apache.org/kafka/3.4.0/kafka_2.13-3.4.0.tgzThe instructions are simplified and concise: `sudo mkdir -p /usr/native/kafka-server && sudo tar xfz kafka_2.13-3.4.0.tgz`The transferred extracted records will be moved to the designated folder below.
sudo mv kafka_2.13-3.4.0/* /usr/native/kafka-server 
Reset configuration records data by command prompt.
sudo systemctl daemon-reloadBeginning Kafka
Assuming Kafka and ZooKeeper are already installed, Kafka will be configured using the following steps:
#!/bin/bash Start zookeeper: ./zookeeper-server-start.sh config/zookeeper.properties Start Kafka server: ./kafka-server-start.sh config/server.properties 
Creating Kafka Subjects
Creation of a Kafka subject subsequently for our utility metrics will facilitate seamless data processing and analysis. Knowledge flows through subjects in Kafka, acting as conduits for information dissemination. Specifically, we have established a subject called “app-metrics” featuring three partitions and a replication factor of one. The partitioning strategy in Kafka disperses data across a cluster of brokers, ensuring that no single point of failure exists. Conversely, the replication factor determines the level of data durability, specifying how many copies of each message are maintained to guarantee its persistence and availability.
`kafka-topics.sh --create --topic app-metrics --bootstrap-server localhost:9092 --partitions 3 --replication-factor 1 --config value.max.bytes=1048576 --config cleanup.policy=compact --config retention.bytes=1073741824 --config retention.ms=43200000 --config flush.messages=10240 --config min.insync.replicas=1`Publishing Information to Kafka
Our utility enables real-time publishing of metrics to a Kafka topic. This script simulates the transmission of utility metrics to the designated Kafka subject every second. Here is the rewritten text:
The metrics encompass specific details such as service identifier, endpoint, status code, response time, CPU usage, memory usage, and timestamp.
while True: What is Pinot Schema?
The Pinot schema defines a set of rules for organizing and structuring data in a way that makes it easily accessible to users. This schema provides a foundation for building databases and applications that can effectively manage complex data relationships.
How does the Pinot schema work?
In traditional database management systems, data is typically stored as tables with fixed column names and row values. The Pinot schema takes a different approach by using a graph-based data model, where data is represented as nodes connected by edges. This allows for more flexible data structures and enables users to define their own relationships between data entities.
What are the benefits of using the Pinot schema?
One key benefit of the Pinot schema is its ability to handle complex relationships between different pieces of data. By allowing users to define custom graph structures, it provides a powerful tool for modeling real-world scenarios that involve multiple interconnected data entities.
SKIP
With a solid understanding of Kafka and stream processing, the next logical step is to set up Apache Pinot to process and store this data. Defining a schema and creating a dashboard in Pinterest requires a clear understanding of the platform’s capabilities and best practices for data visualization.
Schema Definition
The schema outlines the precise structure of the data that Pinot will process and utilize. The schema defines the size and metrics that will likely be persisted, along with information varieties for each field:
{ "schemaName": "AppPerformanceMS", "dimensionFieldSpecs": [ {"name": "Service", "dataType": "string"}, {"name": "Endpoint", "dataType": "string"}, {"name": "StatusCode", "dataType": "integer"} ], "metricFieldSpecs": [ {"name": "ResponseTime", "dataType": "double"}, {"name": "CPUUsage", "dataType": "double"}, {"name": "MemoryUsage", "dataType": "double"} ], "dateTimeFieldSpecs": [ { "name": "Timestamp", "dataType": "long", "format": "1:milliseconds:epoch", "granularity": "1:milliseconds" } ] }Desk Configuration
The desk configuration file instructs Pinot on how to process data, along with specifics regarding knowledge intake from Kafka, indexing strategies, and data retention policies.
CREATE ONE OTHER JSON FILE NAMED “app_performance_metrics_table.json” WITH THE FOLLOWING CONTENT:
[
{
“Metric”: “Average Response Time”,
“Description”: “The average time it takes for your app to respond to user input.”,
“Target Value”: “less than 500ms”
},
{
“Metric”: “Crash Rate”,
“Description”: “The percentage of times your app crashes or freezes.”,
“Target Value”: “less than 1%”
},
{
“Metric”: “User Engagement”,
“Description”: “A measure of how users interact with your app, including time spent and frequency of use.”,
“Target Value”: “average user engagement score”
},
{
“Metric”: “App Store Rating”,
“Description”: “The average rating given to your app by users in the app store.”,
“Target Value”: “4.5 stars or higher”
},
{
“Metric”: “Installation Rate”,
“Description”: “The percentage of users who install and launch your app after clicking on it in the app store.”,
“Target Value”: “10% or higher”
}
]
{ "tableName": "AppPerformanceMetrics", "tableType": "Realtime", "segmentsConfig": { "timeColumnName": "Timestamp", "schemaName": "AppMetrics", "replication": "1" }, "tableIndexConfig": { "loadMode": "MMAP", "streamConfigs": { "streamType": "Kafka", "stream.kafka.subject.identify": "app_performance_metrics", "stream.kafka.dealer.record": "localhost:9092", "stream.kafka.shopper.sort": "low-level" } }The configuration enables the desk to consume knowledge in real-time from the app_performance_metrics Kafka topic. The query utilizes the timestamp column as its primary time reference, while concurrently optimizing data retrieval through strategic indexing, thereby fostering a more sustainable querying experience.
The schema and desk configuration need to be deployed efficiently to ensure seamless operations.
To achieve this, we will utilize a combination of automated tools and manual verification techniques. The process begins with creating a detailed design document outlining the desired schema and desk layout. This document serves as a reference point for all stakeholders involved in the deployment process.
Next, our team will use specialized software to create a digital representation of the schema and desk configuration. This allows us to simulate various scenarios and identify potential issues before actual deployment.
Once satisfied with the design, we will deploy the schema and desk configuration using automated tools whenever possible. Manual verification and testing will be conducted to ensure that the deployed schema and desk meet all the required specifications.
Throughout this process, our team will maintain open communication channels to ensure that all stakeholders are informed and aligned. This collaborative approach enables us to quickly address any issues that may arise during deployment.
Upon successful completion of the deployment, we will conduct a thorough review of the schema and desk configuration to verify its accuracy and efficiency. This final step ensures that the deployed schema and desk meet the required standards and are ready for use.
Once the schema and desk configuration are prepared, we will deploy them to Pinot by following these steps:
Pinot administrative scripts are executed as follows: `pinot-admin.sh` adds a schema using `AddSchema`, specifying the JSON file `app_performance_ms_schema.json` and executing the command. Additionally, it adds a table configuration using `AddTable`, providing the JSON files `app_performance_metrics_table.json` and `app_performance_ms_schema.json`, and executing the operation. After deployment, Apache Pinot will start ingesting data from the Kafka topic “app-metrics”, making it readily available for querying.
Querying Information to Monitor KPIs
As Pinot absorbs knowledge, you can now initiate queries to monitor and track essential performance metrics? Pinot enables rapid retrieval and analysis of data by supporting SQL-like queries. Here’s the revised text in a different style:
This Python script retrieves real-time performance metrics, including average response times and error rates, for each service over a five-minute window.
import requests import json # Pinot dealer URL pinot_broker_url = "http://localhost:8099/question/sql" # SQL question to get common response time and error price question = """ SELECT service_name, AVG(response_time_ms) AS avg_response_time, SUM(CASE WHEN status_code >= 400 THEN 1 ELSE 0 END) / COUNT(*) AS error_rate FROM appPerformanceMetrics WHERE timestamp >= in the past('PT5M') GROUP BY service_name """ # Execute the question response = requests.submit(pinot_broker_url, knowledge=question, headers={"Content material-Kind": "utility/json"}) if response.status_code == 200: consequence = response.json() print(json.dumps(consequence, indent=4)) else: print("Question failed with standing code:", response.status_code) 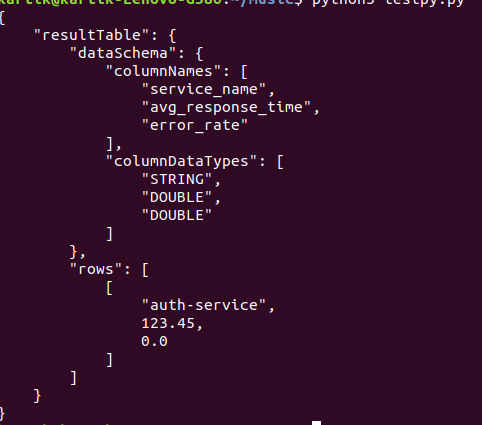
The Pinot script calculates average response times and error rates across all services, focusing on the last five minutes of activity. These key performance indicators provide crucial insights into the operational effectiveness of our utility in real-time.
Understanding the Question Outcomes
- Common Response TimeProvides insights into how quickly each service responds to requests. May increased values signal hidden inefficiencies?
- Error Charge: Reveals the proportion of requests that resulted in errors (standing codes >= 400). An excessive error rate may signal issues with the service.
What’s your take on leveraging Pinot for data visualization in Grafana? By integrating these two powerful tools, you’re poised to unlock insights like never before.
Grafana is a widely used and highly regarded open-source data visualization platform that facilitates seamless integration with Apache Pinot. By integrating Grafana with Pinot, we will craft seamless real-time dashboards showcasing vital metrics such as response times, error rates, and resource utilisation. The instance dashboard can effectively consolidate a variety of key metrics and insights to provide a comprehensive overview of individual instances.
- Response Occasions frequency: The real-time dashboard displays a comprehensive line graph illustrating the average response time across all services for the past 24 hours, providing valuable insights into system performance and identifying potential bottlenecks.
- Error Charges: A stacked bar chart effectively visualizes companies with excessive error charges, enabling swift identification of troublesome sectors.
- Classes Utilization: A real-time graphical display illustrating CPU and memory usage trends across various organizations.
With this advanced visualization setup, we can gain a comprehensive understanding of our utility’s performance and efficiency, allowing for repeated observation of key performance indicators (KPIs) and swift intervention whenever issues arise.
Superior Concerns
As our real-time monitoring system powered by Apache Pinot continues to scale, several key considerations come into play to ensure its ongoing efficacy.
- Information Retention and Archiving:
- ProblemAs data volumes continue to surge, optimizing storage management becomes crucial to mitigate spiraling costs and maintain system performance.
- AnswerImplementing knowledge retention insurance policies enables organizations to manage their knowledge assets effectively by strategically archiving or deleting outdated information that is no longer relevant, thereby freeing up resources for more critical evaluations. Apache Pinot streamlines these processes through its advanced section administration and intelligent knowledge retention features.
- Scaling Pinot:
- ProblemAs the cumulative volume of knowledge and inquiry demands grows, a solitary Pinot Noir event or cluster configuration may become strained under the pressure.
- AnswerApache Pinot facilitates seamless horizontal scaling, allowing for effortless expansion of clusters through the addition of new nodes. The system effectively handles increased learning capacity and processes hundreds of questions efficiently, maintaining performance as its capabilities expand.
- Alerting :
- ProblemDetecting and responding to efficiency points without automated alerts will undoubtedly delay down-side decisions.
- AnswerNotify stakeholders with a multi-pronged approach, integrating various alerting methods to trigger notifications when key performance indicators (KPIs) surpass predetermined thresholds? To ensure seamless operation and quick issue resolution, consider leveraging monitoring tools such as Grafana or Prometheus to configure and manage alerts effectively, thereby keeping you informed of any deviations or performance bottlenecks in your application’s functionality.
- Efficiency Optimization:
- ProblemAs datasets continue to grow in size and complexity, ensuring environmentally sustainable query performance becomes increasingly challenging?
- AnswerOptimize your schema design, indexing methods, and question patterns continually. Leverage Apache Pinot’s arsenal of tools to scrutinize and address potential performance roadblocks with precision. Utilize partitioning and sharding techniques to effectively disperse data and queries across the cluster, promoting efficient information retrieval and query processing.
Conclusion
Effective real-time monitoring is essential for ensuring the reliability and efficiency of modern applications. Apache Pinot offers a robust solution for real-time data processing and querying, rendering it an excellent choice for comprehensive monitoring approaches. By integrating these strategies and exploring advanced concepts such as scalability and security, you’ll be able to build a robust and adaptable monitoring system that enables proactive identification of potential performance issues, thereby delivering a seamless experience for your users.
Key Takeaways
- Apache Pinot excels in processing vast amounts of data in real-time, providing lightning-fast query performance that enables swift insights into utility efficiency metrics. The solution seamlessly integrates with popular streaming platforms such as Kafka, allowing for real-time assessment of key performance indicators including response times, error rates, and resource utilisation.
- Apache Kafka’s Streams API provides utility logs and metrics, which are subsequently consumed by Apache Pinot for processing and analysis. Here is the rewritten text:
By configuring Kafka topics and linking them to Pinot permissions, you enable seamless processing and querying of performance data, ensuring real-time access to actionable insights.
- Defining schemas and configuring tables in Apache Pinot is crucial for establishing a robust and efficient data management infrastructure, ultimately promoting a sustainable and environmentally conscious approach to data administration. The schema defines the information architecture and types, while the desk setup governs knowledge processing and indexing, enabling swift and accurate real-time analysis.
- Apache Pinot enables users to execute SQL-like queries for in-depth knowledge evaluation. When leveraged with visualization tools like Grafana or Apache Superset, this feature enables the construction of interactive dashboards that provide real-time insights into utility performance, facilitating rapid identification and resolution of issues.
Continuously Requested Questions
A. Apache Pinot is optimised for low-latency querying, making it a prime choice for scenarios where real-time insights are crucial. With its ability to consume knowledge streams from sources like Kafka, this technology can seamlessly process vast amounts of high-throughput data, providing real-time analytics that accurately track utility efficiency metrics and inform strategic decisions.
A. Apache Pinot is engineered to rapidly ingest real-time data by instantaneously consuming messages from Kafka topics. Pinot streamlines the processing and storage of data for both novice and advanced Kafka users, enabling fast and efficient querying capabilities with minimal latency.
A. To set up a live monitoring platform with Apache Pinot, one typically aims to:
Sources of Information: Real-time software logs and key performance metrics streaming into Kafka for seamless analysis.
Apache Pinot: A high-performance platform for real-time knowledge ingestion and querying, empowering organizations to extract insights from vast amounts of data with unprecedented speed and accuracy.
Definitions of schema and desk configuration in Pinot for storing and indexing metrics knowledge.
Visualization Instruments: Real-time dashboard creators such as Grafana and Apache Superset offer a range of tools to help you visualize your data effectively.
A. Apache Pinot facilitates seamless integration with various knowledge streaming platforms, including Apache Pulsar and AWS Kinesis. While principles surrounding Kafka remain applicable across various streaming platforms, configurations inevitably differ.