
 quantization enables deployment of AI-powered models on resource-constrained devices. Key benefits include reduced computational complexity and memory usage, allowing for faster inference times. Practical applications: • Edge AI: Enables real-time processing of sensory data on IoT devices or smartphones. • Mobile apps: Enhances user experience by reducing latency and conserving battery life. • Embedded systems: Optimizes performance in resource-limited environments, such as autonomous vehicles. Popular quantization techniques: 1. **Weight-based**: Maps model weights to smaller precision integers (e.g., 8-bit or 16-bit) while maintaining accuracy. 2. **Activation-based**: Quantizes activations (model outputs) using techniques like Huffman coding or entropy coding. 3. **Hybrid**: Combines weight and activation quantization for improved performance. Use instances: • **Google BERT**: Successfully quantized to run on mobile devices with minimal accuracy loss. • **Transformer models**: Applied to speech recognition, natural language processing, and computer vision tasks. By leveraging LLM quantization, developers can now deploy AI-driven applications across diverse environments.")
{kind=link}
Introduction
While Large Language Models have showcased exceptional language processing prowess, their massive scale and computational demands limit their practical application. Quantization, a method to reduce model dimensionality and computational costs, has emerged as a crucial solution.
This comprehensive report provides an in-depth examination of large language model (LLM) quantization techniques, exploring diverse approaches, their effects on model efficiency, and their practical applications across multiple domains. We have further discovered the challenges and alternatives in LLM quantization, thereby gaining valuable insights that will inform future analytical endeavors.
 quantization enables deployment of AI-powered models on resource-constrained devices. Key benefits include reduced computational complexity and memory usage, allowing for faster inference times. Practical applications: • Edge AI: Enables real-time processing of sensory data on IoT devices or smartphones. • Mobile apps: Enhances user experience by reducing latency and conserving battery life. • Embedded systems: Optimizes performance in resource-limited environments, such as autonomous vehicles. Popular quantization techniques: 1. **Weight-based**: Maps model weights to smaller precision integers (e.g., 8-bit or 16-bit) while maintaining accuracy. 2. **Activation-based**: Quantizes activations (model outputs) using techniques like Huffman coding or entropy coding. 3. **Hybrid**: Combines weight and activation quantization for improved performance. Use instances: • **Google BERT**: Successfully quantized to run on mobile devices with minimal accuracy loss. • **Transformer models**: Applied to speech recognition, natural language processing, and computer vision tasks. By leveraging LLM quantization, developers can now deploy AI-driven applications across diverse environments.")
Overview
-
“A comprehensive investigation into the efficacy of quantization in significantly reducing the computational requirements of Giant Language Models (LLMs), without compromising their performance.”
- As LLMs undergo rapid advancements, they pose significant challenges due to their massive scale and resource-intensive nature?
- Quantization of Steady Values: A Software-Driven Approach to Simplifying Large Language Models
- A thorough examination of various quantization methodologies, including post-training quantization and quantization-aware training, and their effects on model efficacy?
- Unlocking the transformative power of quantized large language models (LLMs) across a wide range of domains, including cellular functions and autonomous technologies?
- Examining the trade-offs between hardware constraints and the ongoing need for rigorous analysis to guarantee the efficacy and practicality of low-precision Large Language Models (LLM) quantization strategies?
Creation of Giant Language Mannequin
The advent of Large Language Models (LLMs) has marked a significant milestone, empowering pioneering capabilities across diverse disciplines. Despite the massive size and complexity of these models, the challenge of running them efficiently on limited resources remains daunting. Quantization, a potential game-changer for addressing the limitation of complex models, offers a scalable solution that balances simplicity with efficiency.
Here is the improved/revised text:
Comprehensively examining large language model (LLM) quantization, this exploration delves into its theoretical foundations, practical implementation strategies, and tangible applications in real-world scenarios. We aim to provide a comprehensive comprehension of the intricacies surrounding quantization techniques, including their impact on model performance, and the obstacles associated with their implementation, thereby offering a unified perspective on this pivotal methodology.
LLM Quantization: A Deep Dive
Understanding Quantization
Quantization is the process of mapping continuous values to discrete representations, often involving a reduction in bit width. Within the context of Large Language Models (LLMs), this concept involves reducing the precision of weights and activations by converting them from floating-point representation to lower-bit integer or fixed-point encodings. This optimization yields smaller model sizes, faster inference times, and a reduced memory footprint.
Quantization Strategies
-
- Maps floating-point values into predefined quantization bins, ensuring consistency across various range scenarios.
- Quantizes a consistent range of floating-point values into a predetermined set of distinct intervals.
Visible Illustration
Map floating-point values into fixed-size intervals, then assign each value to the precise midpoint of its respective category. The number of bins available in a system directly impacts the level of quantization, as exemplified by an 8-bit quantization process that encompasses 256 distinct ranges. While this methodology may seem straightforward, it is susceptible to quantization errors, especially when dealing with distributions featuring prolonged tails.

Stable quantity lines featuring even-tempered, finely graded quantization intervals below. Arrows are used to highlight the mapping of floating-point values to their closest quantization levels.
Rationalization:
- The continuous variation of floating-point values is divided into uniform intervals.
- A single quantization degree accounts for each interval uniformly.
- Quantized values within a given interval are rounded to their nearest quantization level.
- Accommodates dynamic quantization settings during inference by leveraging input statistical profiles.
- Optimize quantization settings dynamically by leveraging statistical insights gathered during inference processes.

Unlike traditional uniform quantization, dynamic quantization adaptively adjusts the quantization threshold to accommodate varying input values during inference, leveraging this flexibility to optimize precision and efficiency. While this approach may improve precision, it necessitates additional processing power, potentially offsetting any benefits.
- Teams weigh in collectively, coalescing into distinct clusters that are then epitomized by a representative centroid value.
- Teams are grouped into clusters, each represented by a central value that symbolizes the collective worth.

Weights are predominantly grouped according to their numerical values. A centroid represents each cluster, with its distinct weights adjusted according to the corresponding cluster centroids. By condensing the diverse weight options within the model, we achieve memory cost reductions and potentially unlock computational efficiency gains.
-
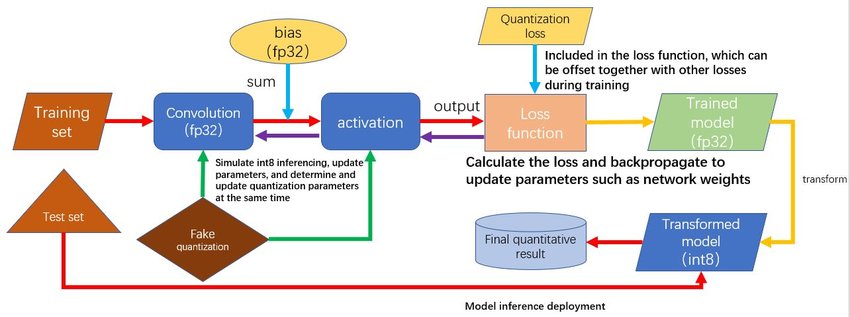
- Enables seamless integration of quantization techniques within the coaching program, thereby enhancing overall efficiency and productivity.
- Strategies harness the power of simulated quantization, leveraging straight-through estimators (STEs) and differentiable quantization to optimize performance.
Additionally learn:
Quantization’s impact on mannequin efficiency remains a topic of considerable intrigue, with researchers continuing to scrutinize the nuances of this phenomenon. The notion that quantization can significantly influence the efficacy of mannequins is substantiated by empirical evidence, which suggests that even minor adjustments in the quantization process can yield substantial gains in terms of efficiency.
While quantization does streamline data transmission, it inherently incurs some efficiency penalties. Despite the complexity of this degradation process, its magnitude is ultimately defined by multiple interconnected factors.
- While deeper and wider fashions may exhibit added robustness against quantization.
- Larger and even more complex datasets can effectively offset diminishing returns in terms of efficiency.
- Reducing bitwidths typically results in significant efficiency losses.
- The choice of quantization approach has a substantial influence on performance efficacy.
Analysis Metrics
Numerous metrics are employed to evaluate the impression of quantization.
- Evaluates the efficacy of the mannequin in achieving specific performance metrics, such as classification accuracy or BLEU ratings, on a designated task.
- Determines the magnitude of the discount in tangible units.
- Assesses the magnitude of acceleration garnered through quantization techniques.
- Evaluates the efficacy of a quantized model in determining its effectiveness.
Additionally learn:
Use Instances of Quantized LLMs
Quantized large language models have the potential to revolutionise numerous processes.
- Deploying Large Language Models (LLMs) on resource-constrained units to support real-time functionalities.
- Optimizing the performance and impact of mobile applications to drive enhanced user experiences and business outcomes.
- Empowering intelligent functionalities within interconnected devices.
- Fostering reduced computational costs to facilitate expedient and informed decision-making in real-time scenarios.
- Enhancing Natural Language Understanding capabilities across diverse sectors.
Python code snippet that accelerates real-time decision-making for autonomous systems via PyTorch’s optimization capabilities:
import torch
from torch import nn, optim
class AutonomyModel(nn.Module):
def __init__(self):
super(AutonomyModel, self).__init__()
self.fc1 = nn.Linear(128, 64)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(64, 32)
self.dropout = nn.Dropout(0.2)
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
device = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)
model = AutonomyModel()
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.MSELoss()
# Your real-time data processing code here
input_data = …
output = model(input_data)
torch.nn.Module): def __init__(self, num_classes=10): super().__init__() self.model = torchvision.models.mobilenet_v2(pretrained=True) self.fc = nn.Linear(self.model.fc.in_features, num_classes) def forward(self, x): return self.model(x).squeeze() # Add squeeze to match the expected output shape torch.utils.data.DataLoader): dataset = torchvision.datasets.FashionMNIST(root='./data', download=True, transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])) data_loader = DataLoader(dataset, batch_size=32, shuffle=True) torch.nn.CrossEntropyLoss()): criterion = nn.CrossEntropyLoss() torch.optim.Adam(mannequin.parameters(), lr=0.001)): optimizer = optim.Adam(man_nequin.parameters(), lr=0.001) torch.quantization.get_default_qconfig('fbgemm'))): mannequin.qconfig = torch.quantization.get_default_qconfig('fbgemm') torch.quantization.put_together(mannequin, inplace=True)): torch.quantization.put_together(man_nequin, inplace=True) mannequin.eval()): mannequin.eval() torch.no_grad()): with torch.no_grad(): output = mannequin(example_input) determination = torch.argmax(output, dim=1) print(f"Determination: {determination.item()}") torch.save(mannequin.state_dict(), 'quantized_autonomous_model.pth')]: torch.save(man_nequin.state_dict(), 'quantized_autonomous_model.pth') torch.randn(1, 3, 224, 224))]: example_input = torch.randn(1, 3, 224, 224)Rationalization:
- :
- We employ a pre-trained MobileNetV2, an environmentally conscious and resource-efficient architecture well-suited for edge-based implementations and real-time applications.
- The final layer adapts to accommodate the diverse range of lessons tailored to the specific activity.
- :
- Transform the entire knowledge into a structure suitable for the model, encompassing resizing and normalization processes that enable seamless integration and effective learning.
- :
- Layers such as Conv2d, BatchNorm2d, and ReLU are consolidated to reduce computational requirements.
- We select a quantization setting tailored to x86-based processors that utilizes fbgemm optimization.
- :
- Once the model is prepared, we transform it into its quantized form, significantly compressing its size and accelerating inference speed.
- :
- Quantified mannequins enable real-time selection capabilities. Inferences are made by analyzing patterns entered, yielding outputs that inform decision-making processes.
- :
- The quantized mannequin is now ready for deployment, ensuring seamless functionality in real-time scenarios.
Additionally learn:
Challenges of LLM Quantization
Despite its promise, quantization encounters several hurdles:
- Evaluating the trade-off between dimensional reductions in mannequins and their impact on operational effectiveness.
- Developing customized hardware infrastructure that optimizes environmentally conscious quantization processes.
- Optimizing Quantization Techniques Across Varying Applications and Industries.
- Harnessing advancements in novel quantization techniques to minimize efficiency degradation.
- Optimizing Quantization Through Hardware-Software Co-Design.
- What impact does quantization have on seemingly unrelated phenomena?
- The energy savings from Large Language Model (LLM) quantization can be substantial, potentially reducing carbon emissions by up to 90% per inference. By compressing model weights and activations using techniques like integer quantization or knowledge distillation, LLMs can require significantly fewer computations, leading to a notable decrease in energy consumption.
Conclusion
LLM (Large Language Model) quantization is crucial for effectively deploying large-scale language models on resource-constrained platforms, enabling efficient and scalable processing of complex natural language tasks. Practitioners who thoroughly deliberate on quantization approaches, analytical measures, and software requirements are well-positioned to achieve maximum efficiency and effectiveness by leveraging this methodology. As analysis of this space continues to progress, we will increasingly expect substantial breakthroughs in LLM quantization, which will unlock a wide range of new opportunities across multiple domains.
Regularly Requested Questions
Ans. LLM quantization enables compression of model weights and activations into lower-bit representations, thereby shrinking models, accelerating their processing, and enhancing memory utilization.
Ans. The initial strategies are Publish-Coaching Quantization (both uniform and dynamic) and Quantization-Aware Coaching (QAT).
Ans. Challenges arise from striking a balance between efficiency and accuracy, necessitating specialized hardware, as well as task-specific quantization strategies that require careful consideration.
Ans. While quantization may compromise efficiency to some extent, its impact on performance is actually dependent on several factors, including the specific neural network architecture, the complexity of the training data set, and the chosen bit width.