{kind=link}

From information overload to enhanced digital resilience. Cisco IT unified telemetry information throughout its huge community, enabling automation to deal with 99.998% of alerts and attaining zero main incidents – empowering engineers to proactively handle community well being at scale.
The info drawback: overload, restricted perception, and silos
Cisco IT manages an unlimited, complicated setting with tons of of hundreds of belongings – together with computer systems, switches, entry factors, house units, and a wide selection of purposes and companies – in addition to exterior techniques like web service and cloud suppliers. Every of those belongings generates telemetry, presenting a problem to successfully monitor and make sense of excessive volumes of numerous information throughout the environment.
In our earlier community operations mannequin, we outsourced a perform accountable for community observability monitoring, second-level help for triage, and technical experience. This outsourced perform relied on conventional monitoring strategies involving guide processes and siloed dashboards.
In consequence, we lacked management to tailor how telemetry was processed, routed, and actioned – resulting in generic metrics and restricted perception into important areas like person expertise and utility efficiency. For instance, whereas we may see that the community was operational, we had restricted visibility into important areas like person expertise and utility efficiency.
Recognizing this information drawback, we determined to carry the outsourced community operations perform in-house. This gave us full management to design and implement a modernized community observability technique, enabling us to higher leverage our wealth of telemetry and finally strengthen Cisco’s digital resilience.
Nonetheless, this shift wasn’t nearly altering group obligations. It additionally meant dropping our current community observability system and requiring our smaller group to handle the large quantity of telemetry information.
So as to add to the stress, attributable to contractual obligations, we got simply 40 days to make this transition and construct a totally new community observability system.
Contained in the blueprint: Constructing a contemporary observability system
The duty at hand wasn’t simply to exchange and mirror the outsourced community operations and legacy observability system, however to construct one thing higher. We needed to construct a system that might deal with large volumes of information, ship deeper, actionable, and proactive insights, and allow a leaner group to be extra productive.
To attain this, we designed a community observability mannequin centered on three key areas:
- Acquire: Gathers telemetry and metrics from hundreds of units, purposes, and platforms – each inside owned and unowned, exterior environments
- Monitor: Makes use of instruments and algorithms to course of and analyze the collected information, serving to to establish patterns, anomalies, and potential points inside the community
- Act: Initiates human or automated responses when recognized issues meet predefined rule standards, enabling well timed remediation.

Determine 1: Cisco IT’s community observability mannequin
Whereas this method is run by a centralized networking group, information and rule creation are democratized – permitting engineers and repair homeowners throughout IT to outline and customise their very own alert guidelines through GitOps. This ensures the system adapts to distinctive and evolving enterprise wants.
To function this community administration technique, we use a mix of Cisco options:
- Cisco’s community administration options, together with Catalyst Middle, SD-WAN Supervisor, Meraki Dashboard, and Nexus Dashboard, accumulate and monitor detailed telemetry, efficiency metrics, and safety standing information on their respective belongings. This gives complete visibility and assurance, along with their different core capabilities for managing community units.
- ThousandEyes gives real-time, end-to-end visibility into community and utility efficiency. It additionally extends this visibility into exterior, unowned environments similar to public web and cloud companies. These granular insights feed into the observability system, giving us an entire view of person expertise and connectivity – irrespective of the place workers are working.
- Splunk Cloud Platform acts as a unified operations dashboard – aggregating and visualizing telemetry information from the above options that have been beforehand siloed. It allows real-time monitoring, enabling engineers to shortly give attention to probably the most important alerts.
Collectively, Splunk and ThousandEyes enable us in Cisco IT to proactively monitor, analyze, and act on tens of millions of occasions day by day.
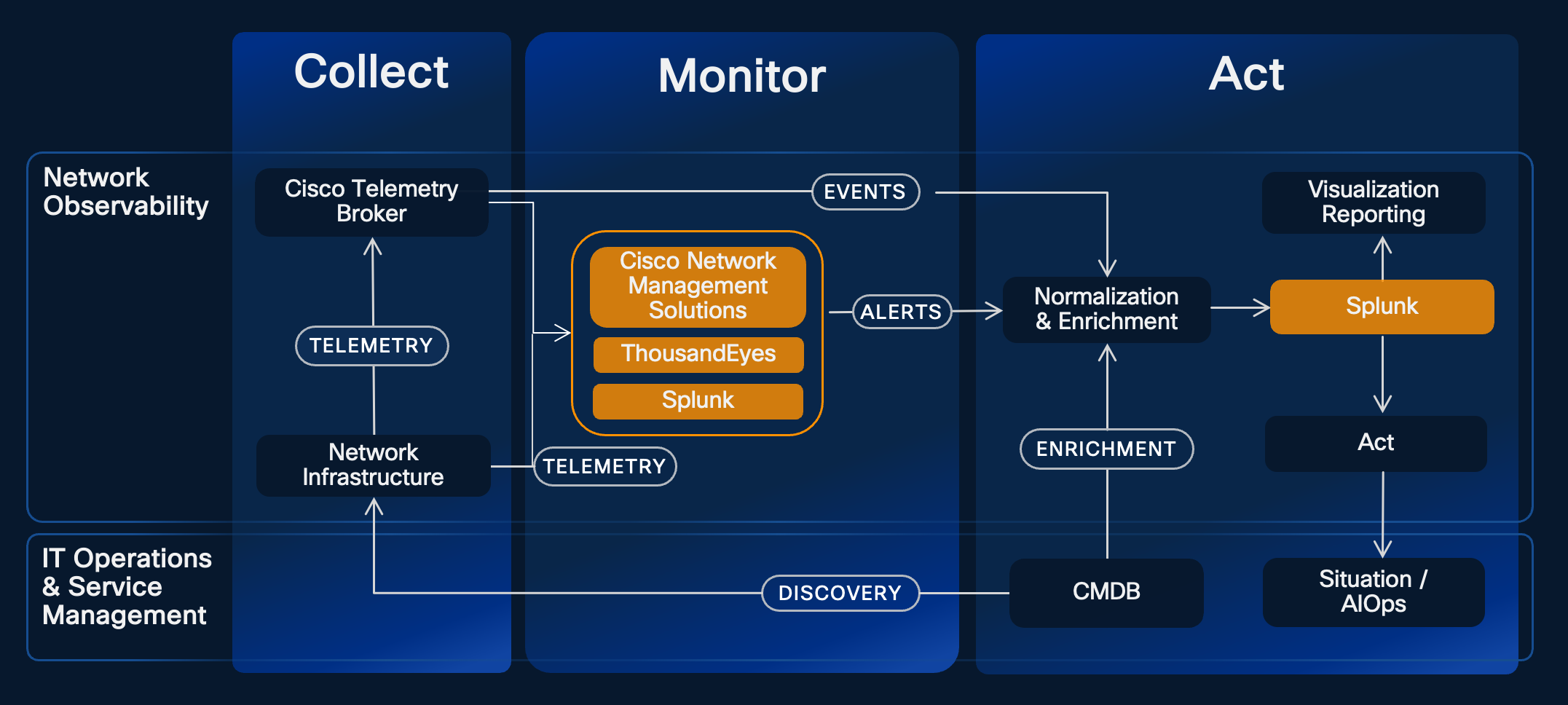
Determine 2: Cisco IT’s observability system instruments and integrations
Automation is a important element of our community observability technique. By feeding telemetry information and incident outcomes into our Massive Language Fashions (LLMs) and automation techniques, we are able to effectively course of and prioritize tens of millions of day by day alerts to cut back engineer workload and pace up response instances, bettering end-user expertise.
The payoff: Enhanced resilience, effectivity, and past
From the start, we acknowledged that this initiative would contain vital upfront work. Nonetheless, the outcomes have far exceeded our preliminary expectations.
Since deploying this new observability technique and system:
- 0 main incidents have occurred, down from 3-4 per quarter beforehand.
- 10x extra telemetry information is being monitored, enabling broader and deeper insights into community well being, utility efficiency and person expertise at a subsequent stage of element.
- 4x larger visibility, with day by day alert quantity rising from tons of of hundreds to 4 million, leading to earlier detection and proactive decision of potential points earlier than they escalate.
- Automation now handles 99.998% of 4 million day by day alerts generated, minimizing the necessity for guide intervention, and enabling sooner identification and determination of points by real-time, automated triage and response workflows.
Maybe most significantly, this effort laid a basis that permits us to repeatedly scale our AI-driven automation and lengthen AIOps capabilities throughout the broader Cisco IT setting.
Classes discovered: Methods that made the distinction
Modernizing our observability technique and system was a fast-paced journey, stuffed with priceless classes. Listed below are some key takeaways and techniques to assist different groups trying to do the identical:
- Collaborative possession: Herald material consultants from throughout the group, share data extensively, and construct a democratized tradition the place everybody has a stake in observability and operational success.
- Acquire telemetry from all over the place: Complete monitoring begins with capturing information throughout your whole setting.
- Information normalization and enrichment: Unifying numerous information sources is essential for holistic visibility. Spend money on a high-quality, well-maintained CMDB to maintain your stock and information correct. Use your CMDB to complement alerts with enterprise context, possession, and criticality.
- Rule experimentation: Encourage democratized groups to develop and refine alerting and automation guidelines to maintain alert volumes manageable and related.
- AI-driven automation: Feed enriched information into automation and LLMs to streamline remediation and take steps towards self-healing operations.
We’re thrilled and pleased with the work and outcomes that our groups have achieved, however our journey doesn’t finish right here. We’ll proceed to iterate, enhance, and advance our AI-driven automation capabilities.