{kind=link}

Amazon Redshift is a quick, petabyte-scale cloud knowledge warehouse that makes it easy and cost-effective to investigate your knowledge utilizing normal SQL and your present enterprise intelligence (BI) instruments. Tens of 1000’s of consumers depend on Amazon Redshift to investigate exabytes of knowledge and run complicated analytical queries, delivering the most effective price-performance.
With a completely managed, AI-powered, massively parallel processing (MPP) structure, Amazon Redshift drives enterprise decision-making shortly and cost-effectively. Beforehand, Amazon Redshift supplied DC2 (Dense Compute) node varieties optimized for compute-intensive workloads. Nevertheless, they lacked the pliability to scale compute and storage independently and didn’t assist lots of the trendy options now out there. As analytical calls for develop, many purchasers are upgrading from DC2 to RA3 or Amazon Redshift Serverless, which provide unbiased compute and storage scaling, together with superior capabilities resembling knowledge sharing, zero-ETL integration, and built-in synthetic intelligence and machine studying (AI/ML) assist with Amazon Redshift ML.
This publish gives a sensible information to plan your goal structure and migration technique, masking improve choices, key concerns, and finest practices to facilitate a profitable and seamless transition.
Improve course of from DC2 nodes to RA3 and Redshift Serverless
Step one in the direction of improve is to grasp how the brand new structure needs to be sized; for this, AWS gives a suggestion desk for provisioned clusters. When figuring out the configuration for Redshift Serverless endpoints, you may assess compute capability particulars by inspecting the connection between RPUs and reminiscence. Every RPU allocates 16 GiB of RAM. To estimate the bottom RPU requirement, divide your DC2 nodes cluster’s whole RAM by 16. These suggestions present steering in sizing the preliminary goal structure however depend upon the computing necessities of your workload. To higher estimate your necessities, think about conducting a proof of idea that makes use of Redshift Check Drive to run potential configurations. To be taught extra, see Discover the most effective Amazon Redshift configuration to your workload utilizing Redshift Check Drive and Efficiently conduct a proof of idea in Amazon Redshift. After you determine on the goal configuration and structure, you may construct the technique for upgrading.

Structure patterns
Step one is to outline the goal structure to your answer. You may select the primary structure sample that finest aligns together with your use case from the choices introduced in Structure patterns to optimize Amazon Redshift efficiency at scale. There are two most important situations, as illustrated within the following diagram.
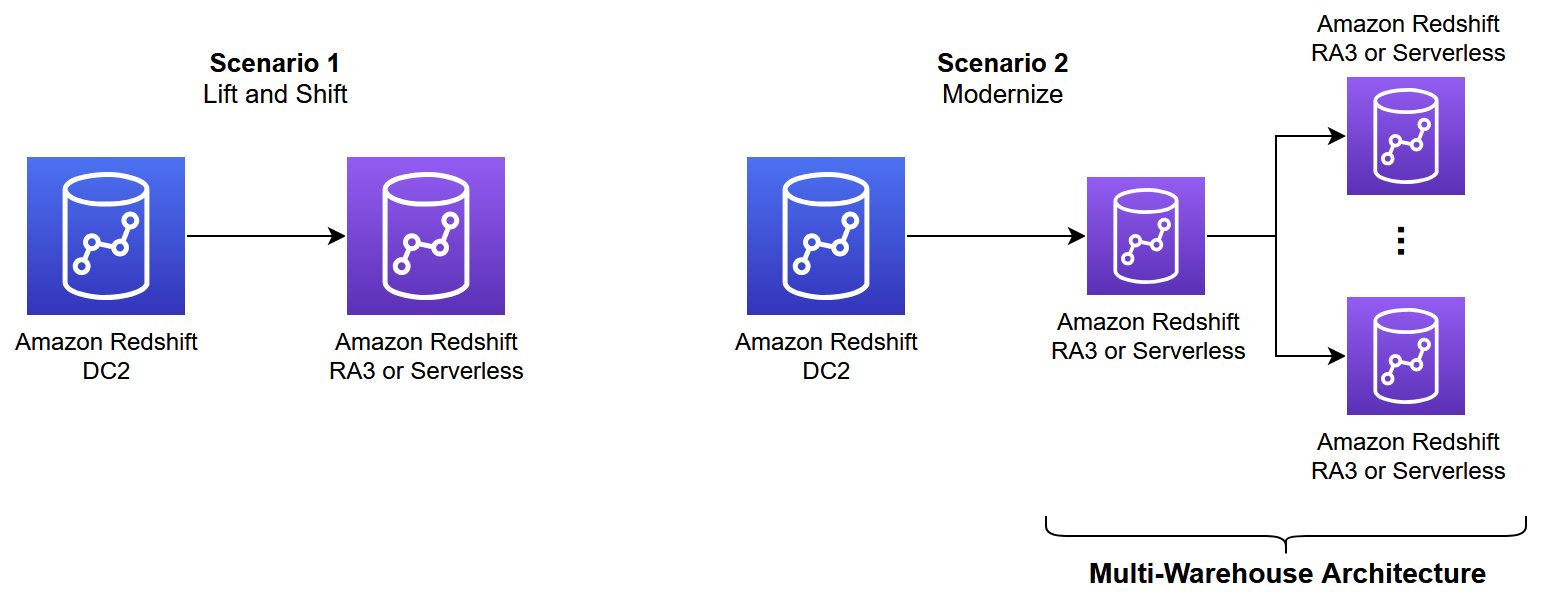
On the time of writing, Redshift Serverless doesn’t have handbook workload administration; every thing runs with computerized workload administration. Take into account isolating your workload into a number of endpoints primarily based on use case to allow unbiased scaling and higher efficiency. For extra data, discuss with Structure patterns to optimize Amazon Redshift efficiency at scale.
Improve methods
You may select from two doable improve choices when upgrading from DC2 nodes to RA3 nodes or Redshift Serverless:
- Full re-architecture – Step one is to judge and assess the workloads to find out whether or not you may benefit from a contemporary knowledge structure, then re-architect the prevailing platform through the improve course of from DC2 nodes.
- Phased method– It is a two-stage technique. The primary stage includes a simple migration to the goal RA3 or Serverless configuration. Within the second stage, you may modernize the goal structure by benefiting from cutting-edge Redshift options.
We normally advocate a phased method, which permits for a smoother transition whereas enabling future optimization. The primary stage of a phased method consists of the next steps:
- Consider an equal RA3 nodes or Redshift Serverless configuration to your present DC2 cluster, utilizing the sizing pointers for provisioned clusters or the compute capability choices for serverless endpoints.
- Totally validate the chosen goal configuration in a non-production atmosphere utilizing Redshift Check Drive. This automated device simplifies the method of simulating your manufacturing workloads on numerous potential goal configurations, enabling a complete what-if evaluation. This step is strongly really useful.
- Proceed to the improve course of if you find yourself glad with the price-performance ratio of a specific goal configuration, utilizing one of many strategies detailed within the following part.
Redshift RA3 cases and Redshift Serverless present entry to highly effective new capabilities, together with zero-ETL, Amazon Redshift Streaming Ingestion, knowledge sharing writes, and unbiased compute and storage scaling. To maximise these advantages, we advocate conducting a complete assessment of your present structure (the second stage of a phased method) to establish alternatives for modernization utilizing Amazon Redshift’s newest options. For instance:
Improve choices
You may select from 3 ways to resize or improve a Redshift cluster from DC2 to RA3 or Redshift Serverless: snapshot restore, basic resize, and elastic resize.
Snapshot restore
The snapshot restore technique follows a sequential course of that begins with capturing a snapshot of your present (supply) cluster. This snapshot is then used to create a brand new goal cluster together with your desired specs. After creation, it’s important to confirm knowledge integrity by confirming that knowledge has been appropriately transferred to the goal cluster. An essential consideration is that any knowledge written to the supply cluster after the preliminary snapshot should be manually transferred to keep up synchronization.
This technique affords the next benefits:
- Permits for the validation of the brand new RA3 or Serverless setup with out affecting the prevailing DC2 cluster
- Supplies the pliability to revive to totally different AWS Areas or Availability Zones
- Minimizes cluster downtime for write operations through the transition
Be mindful the next concerns:
- Setup and knowledge restore may take longer than elastic resize.
- You may encounter knowledge synchronization challenges. Any new knowledge written to the supply cluster after snapshot creation requires handbook copying to the goal. This course of may want a number of iterations to realize full synchronization and require downtime earlier than cutoff.
- A brand new Redshift endpoint is generated, necessitating connection updates. Take into account renaming each clusters so as to preserve the unique endpoint (be certain that the brand new goal cluster adopts the unique supply cluster’s identify)
Traditional resize
Amazon Redshift creates a goal cluster and migrates your knowledge and metadata to it from the supply cluster utilizing a backup and restore operation. All of your knowledge, together with database schemas and person configurations, is precisely transferred to the brand new cluster. The supply cluster restarts initially and is unavailable for a couple of minutes, inflicting minimal downtime. It shortly resumes, permitting each learn and write operations because the resize continues within the background.
Traditional resize is a two-stage course of:
- Stage 1 (important path) – Throughout this stage, metadata migration happens between the supply and goal configurations, quickly putting the supply cluster in read-only mode. This preliminary part is often transient. When this part is full, the cluster is made out there for learn and write queries. Though tables initially configured with
KEYdistribution fashion are quickly saved utilizingEVENdistribution, they are going to be redistributed to their authenticKEYdistribution throughout Stage 2 of the method. - Stage 2 (background operations) – This stage focuses on restoring knowledge to its authentic distribution patterns. This operation runs within the background with low precedence with out interfering with the first migration course of. The length of this stage varies primarily based on a number of elements, together with the quantity of knowledge being redistributed, ongoing cluster workload, and the goal configuration getting used.
The general resize length is primarily decided by the info quantity being processed. You may monitor progress on the Amazon Redshift console or through the use of the SYS_RESTORE_STATE system view, which shows the share accomplished for the desk being transformed (accessing this view requires superuser privileges).
The basic resize method affords the next benefits:
- All doable goal node configurations are supported
- A complete reconfiguration of the supply cluster rebalances the info slices to default per node, resulting in even knowledge distribution throughout the nodes
Nevertheless, take into accout the next:
- Stage 2 redistributes the info for optimum efficiency. Nevertheless, Stage 2 runs at a decrease precedence, and in busy clusters, it could actually take a very long time to finish. To hurry up the method, you may manually run the
ALTER TABLE DISTSTYLEcommand in your tables havingKEY DISTSTYLE. By executing this command, you may prioritize the info redistribution to occur sooner, mitigating any potential efficiency degradation as a result of ongoing Stage 2 course of. - As a result of Stage 2 background redistribution course of, queries can take longer to finish through the resize operation. Take into account enabling concurrency scaling as a mitigation technique.
- Drop pointless and unused tables earlier than initiating a resize to hurry up knowledge distribution.
- The snapshot used for the resize operation turns into devoted to this operation solely. Due to this fact, it could actually’t be used for a desk restore or different goal.
- The cluster should function inside a digital non-public cloud (VPC).
- This method requires a brand new or a latest handbook snapshot taken earlier than initiating a basic resize.
- We advocate scheduling the operation throughout off-peak hours or upkeep home windows for minimal enterprise influence.
Elastic resize
When utilizing elastic resize to vary the node kind, Amazon Redshift follows a sequential course of. It begins by making a snapshot of your present cluster, then provisions a brand new goal cluster utilizing the newest knowledge from that snapshot. Whereas knowledge transfers to the brand new cluster within the background, the system stays in read-only mode. Because the resize operation approaches completion, Amazon Redshift mechanically redirects the endpoint to the brand new cluster and stops all connections to the unique one. If any points come up throughout this course of, the system sometimes performs an computerized rollback with out requiring handbook intervention, although such failures are uncommon.
Elastic resize affords a number of benefits:
- It’s a fast course of that takes 10–quarter-hour on common
- Customers preserve learn entry to their knowledge through the course of, experiencing solely minimal interruption
- The cluster endpoint stays unchanged all through and after the operation
When contemplating this method, take into accout the next:
- Elastic resize operations can solely be carried out on clusters utilizing the EC2-VPC platform. Due to this fact, it’s not out there for Redshift Serverless.
- The goal node configuration should present enough storage capability for present knowledge.
- Not all goal cluster configurations assist elastic resize. In such instances, think about using basic resize or snapshot restore.
- After the method is began, elastic resize can’t be stopped.
- Knowledge slices stay unchanged; this will doubtlessly trigger some knowledge or CPU skew.
Improve suggestions
The next flowchart visually guides the decision-making course of for selecting the suitable Amazon Redshift improve technique.
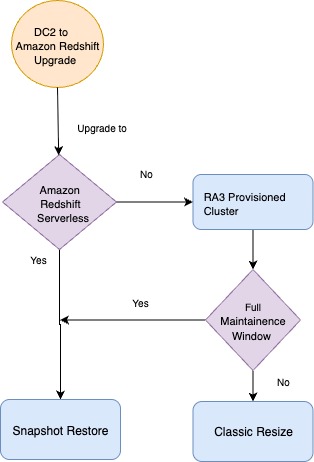
When upgrading Amazon Redshift, the tactic will depend on the goal configuration and operational constraints. For Redshift Serverless, at all times use the snapshot restore technique. If upgrading to an RA3 provisioned cluster, you may select from two choices: use snapshot restore if a full upkeep window with downtime is appropriate, or select basic resize for minimal downtime, as a result of it rebalances the info slices to default per node, resulting in even knowledge distribution throughout the nodes. Though you should use elastic resize for sure node kind adjustments (for instance, DC2 to RA3) inside particular ranges, it’s not really useful as a result of elastic resize doesn’t change the variety of slices, doubtlessly resulting in knowledge or CPU skew, which might later influence the efficiency of the Redshift cluster. Nevertheless, elastic resize stays the first suggestion when it is advisable add or cut back nodes in an present cluster.
Finest practices for migration
When planning your migration, think about the next finest practices:
- Conduct a pre-migration evaluation utilizing Amazon Redshift Advisor or Amazon CloudWatch.
- Select the fitting goal structure primarily based in your use instances and workloads. You should use Redshift Check Drive to find out the fitting goal structure.
- Backup utilizing handbook snapshots, and allow automated rollback.
- Talk timelines, downtime, and adjustments to stakeholders.
- Replace runbooks with new structure particulars and endpoints.
- Validate workloads utilizing benchmarks and knowledge checksum.
- Use upkeep home windows for remaining syncs and cutovers.
By following these practices, you may obtain a managed, low-risk migration that balances efficiency, value, and operational continuity.
Conclusion
Migrating from Redshift DC2 nodes to RA3 nodes or Redshift Serverless requires a structured method to assist efficiency, cost-efficiency, and minimal disruption. By choosing the fitting structure to your workload, and validating knowledge and workloads post-migration, organizations can seamlessly modernize their knowledge platforms. This improve facilitates long-term success, serving to groups totally harness RA3’s scalable storage or Redshift Serverless auto scaling capabilities whereas optimizing prices and efficiency.
In regards to the authors