{kind=link}

- Have you ever ever stopped and questioned what the key sauce is behind DeepSeek?
- What systemic modifications are answerable for the spectacular enchancment in GPT 5?
- How precisely did Google handle to make Gemma, its compact mannequin, carry out fabulously regardless of its small measurement?
We stay in an AI-saturated world. You open Twitter (sorry, X) and there’s a brand new mannequin each week. Identical to folks as soon as waited in anticipation for the following iPhone launch, we now watch for the following iteration of an LLM. Most of the people is happy simply speaking to those fashions, however for folks like me, that’s not sufficient. The AI scientist in me at all times needs to peek inside. I wish to see what’s really occurring beneath the hood.
And right here’s the reality: the LLM race is now not nearly throwing extra GPUs on the wall and scaling parameters. It’s about structure. The small, intelligent design methods that make a contemporary LLM extra memory-efficient, extra steady, and sure, extra highly effective.
This weblog is about these design methods for a contemporary LLM. I went down the rabbit gap of mannequin papers and engineering write-ups, and I discovered 10 architectural optimisations that specify why fashions like DeepSeek V3, Gemma 3, and GPT 5 punch above their weight.
Why must you learn this weblog?
In the event you’re simply inquisitive about AI, you may skip to the cool diagrams and metaphors. In the event you’re constructing or fine-tuning fashions, you’ll choose up concepts that may really save your GPU invoice. And should you’re like me, somebody who finds magnificence in elegant techniques, you then’ll respect the creativity right here.
Additionally, honest warning – This can be a lengthy put up. I’m aiming for breadth. Seize some espresso or chai. Or each. You’ll want it.
The recipe for cooking up successful LLM (one which makes cash and other people really use) appears one thing like this:
Superior LLM = Tremendous-sized mannequin + Tremendous-sized and high-quality information + Additional toppings (RLHF, RLAIF, post-training, Constitutional AI, no matter’s trending this week)
The super-sized mannequin is normally constructed on a variant of the Transformer structure launched by Vaswani et. al in 2017.

Nevertheless, now we have noticed over time that the bottom model itself shouldn’t be sufficient. Totally different labs, analysis teams, and tech firms have come out with completely different interpretations of the identical design for a contemporary LLM.
Let’s have a look at a few of these architectures on this weblog.
10 Architectural optimisation methods
Multi-Head Latent Consideration (MLA)
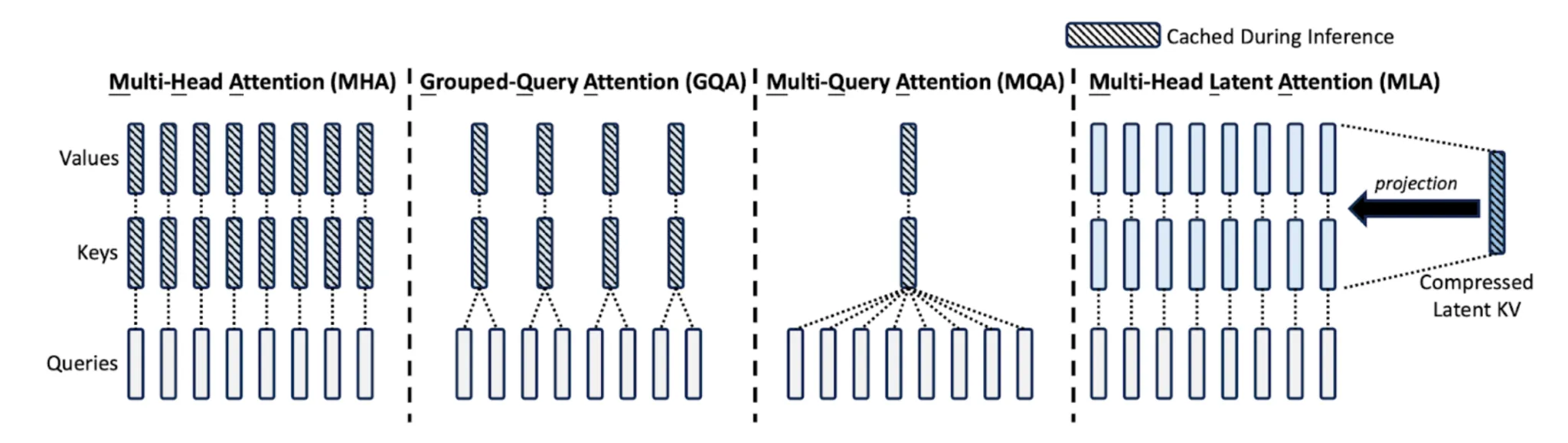
Let’s break it down phrase by phrase: Multi-head is similar as traditional Transformers, having a number of heads. Latent means to shrink stuff right into a smaller house. Consideration remains to be consideration.
The difficulty: in regular consideration, we challenge Q/Ok/V and retailer a KV cache that grows linearly with sequence size. At 128k tokens, it’s monstrous.
The trick: MLA compresses keys and values earlier than storing, then decompresses later. Like zipping information earlier than importing to Dropbox.
DeepSeek makes use of this to avoid wasting tons of reminiscence. The small additional compute is nothing in comparison with shopping for one other big GPU. You’ll be able to learn extra about it within the DeepSeek V2 paper.
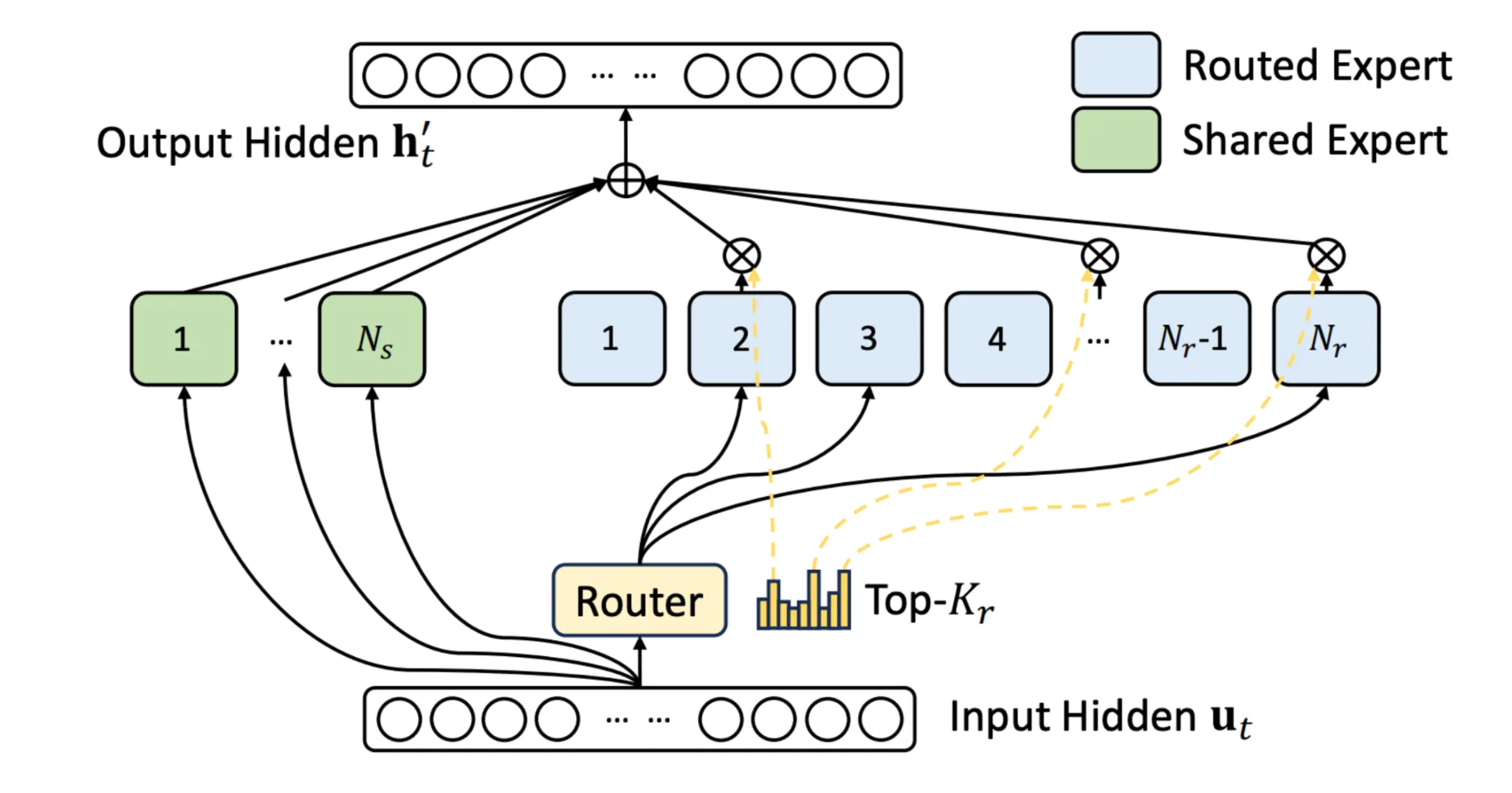
Sparse Combination-of-Consultants (MoE) + Shared Knowledgeable
MoE layers are one of many coolest hacks in recent times. As an alternative of 1 big feed-forward layer, you’ve gotten many consultants. A router decides which consultants get activated per token. This implies you may have a trillion parameters however solely use 10% per token.
However early MoE fashions have been unstable. Enter the shared professional. It’s like a default professional that each token at all times goes via, making certain some consistency throughout tokens. The shared professional acts like the protection internet at a circus: you may nonetheless do wild flips, however you gained’t die should you miss.
Right here’s an illustration of this method from the DeepSeek V3 paper.
What’s extra, even LLAMA 4 makes use of this setup:
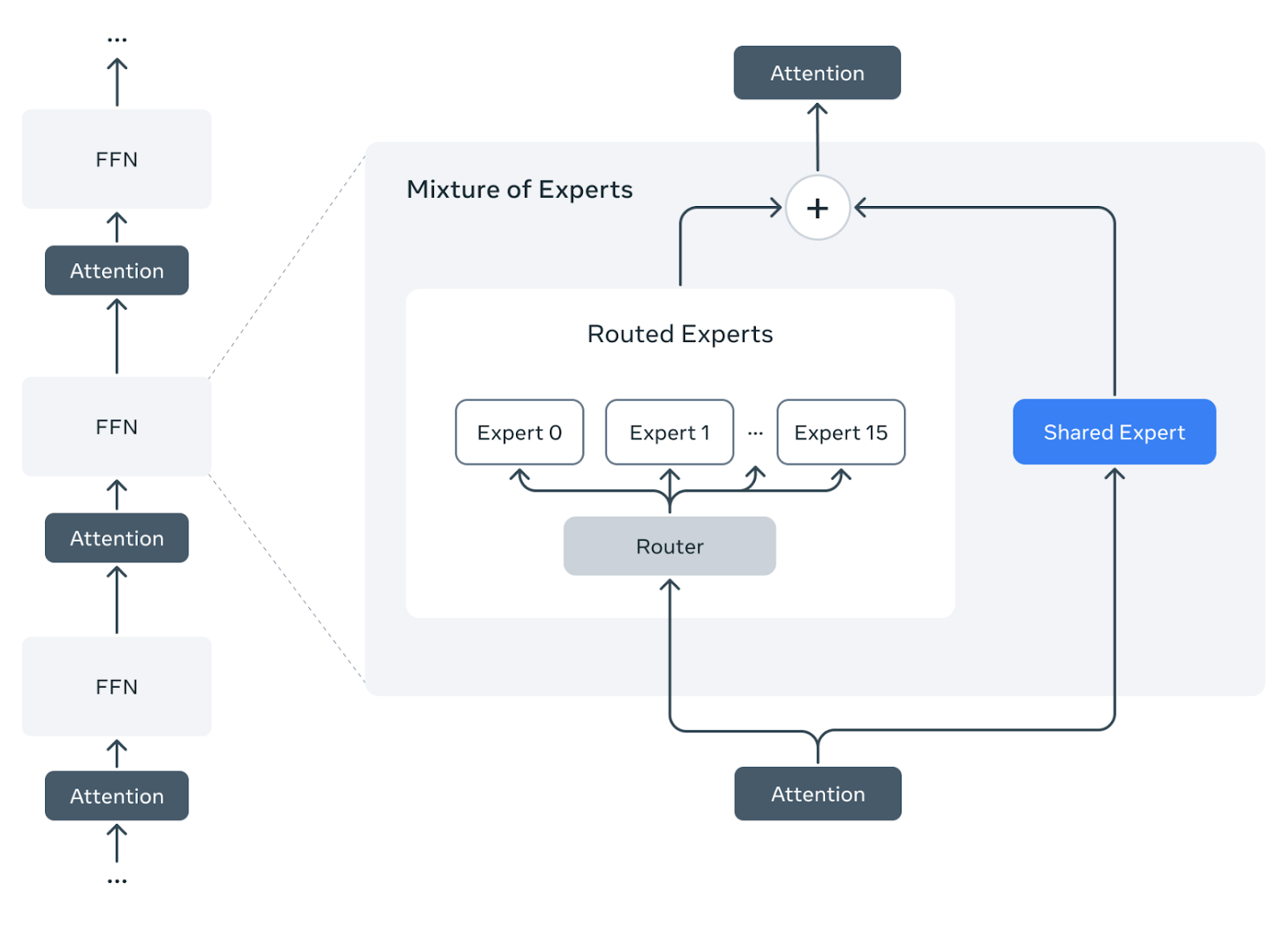
Meta has written a really insightful weblog on Llama 4 the place they focus on it intimately.
Grouped-Question Consideration (GQA)
Full multi-head consideration is pricey. Each question head will get its personal key/worth projections. GQA says let’s share keys and values throughout teams of queries. Abruptly, your reminiscence and compute invoice drop with out killing efficiency.
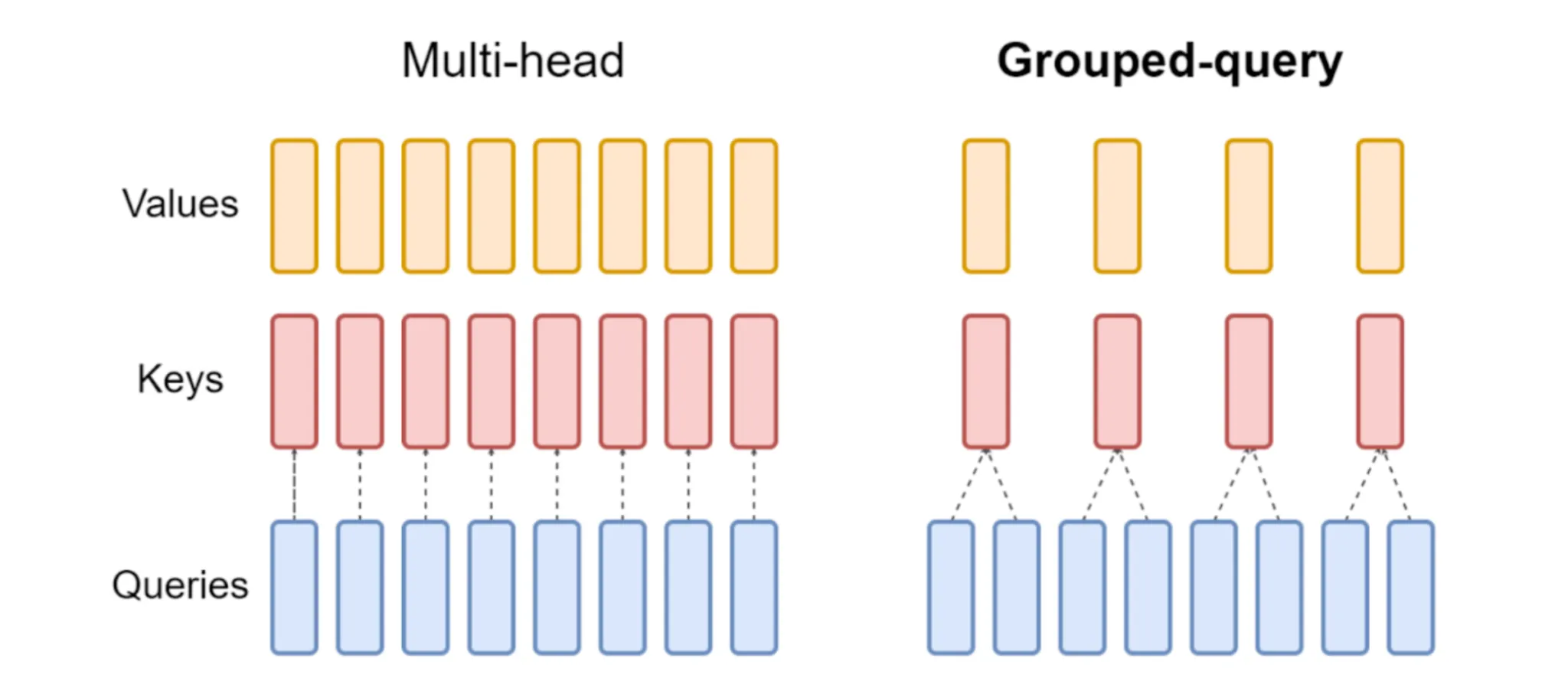
It’s like ordering meals at a restaurant as a gaggle as an alternative of everybody putting separate orders. Much less chaos, sooner service, and higher expertise for everyone.
Take a look at the GQA paper if you wish to learn additional.
Sliding Window + International Consideration Hybrids
Do we actually want each token to see each different token? Nope. Most tokens solely care about their neighbors. Some uncommon ones, like a title, a abstract sentence, or a particular marker, may very well want the massive image.
So the trick is easy: combine each worlds. Use sliding window consideration for the majority (low cost and environment friendly), and drop in international consideration from time to time to sew the entire story collectively. Gemma 3 does this neatly: 5 native layers, then one international, repeat. At all times begin native.
Consider it like gossip. More often than not, you’re tuned into what your neighbors are whispering. However on occasion, you want that one loud announcement from throughout the room to make sense of the entire story.
This isn’t new-new since papers like Longformer (Beltagy et al., 2020) first confirmed how sliding home windows may scale consideration. It even tried completely different settings of the sliding window:
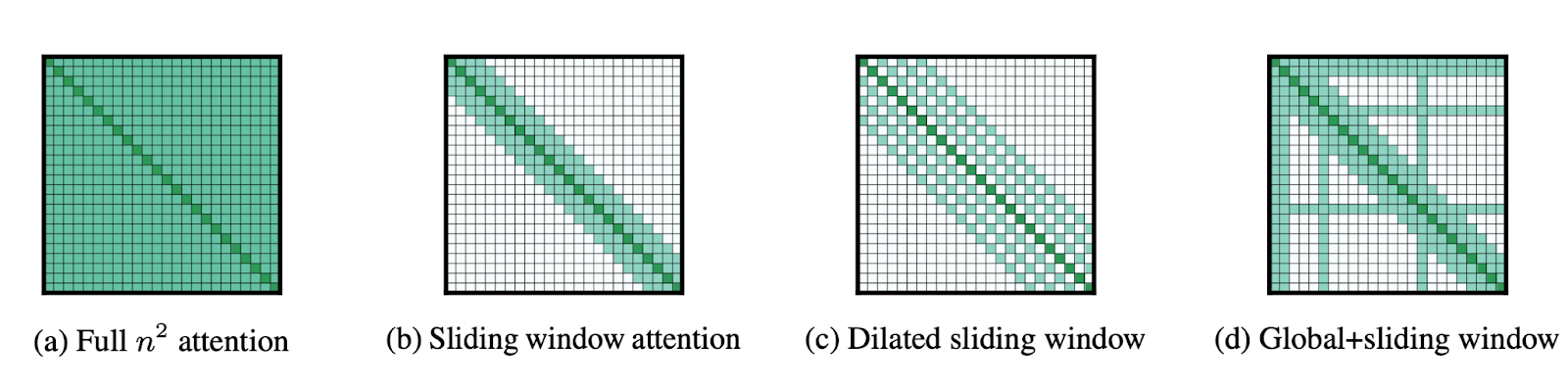
And Luong et al., 2015 explored international consideration. Right here is an illustration from the paper of the way it’s computed in apply:
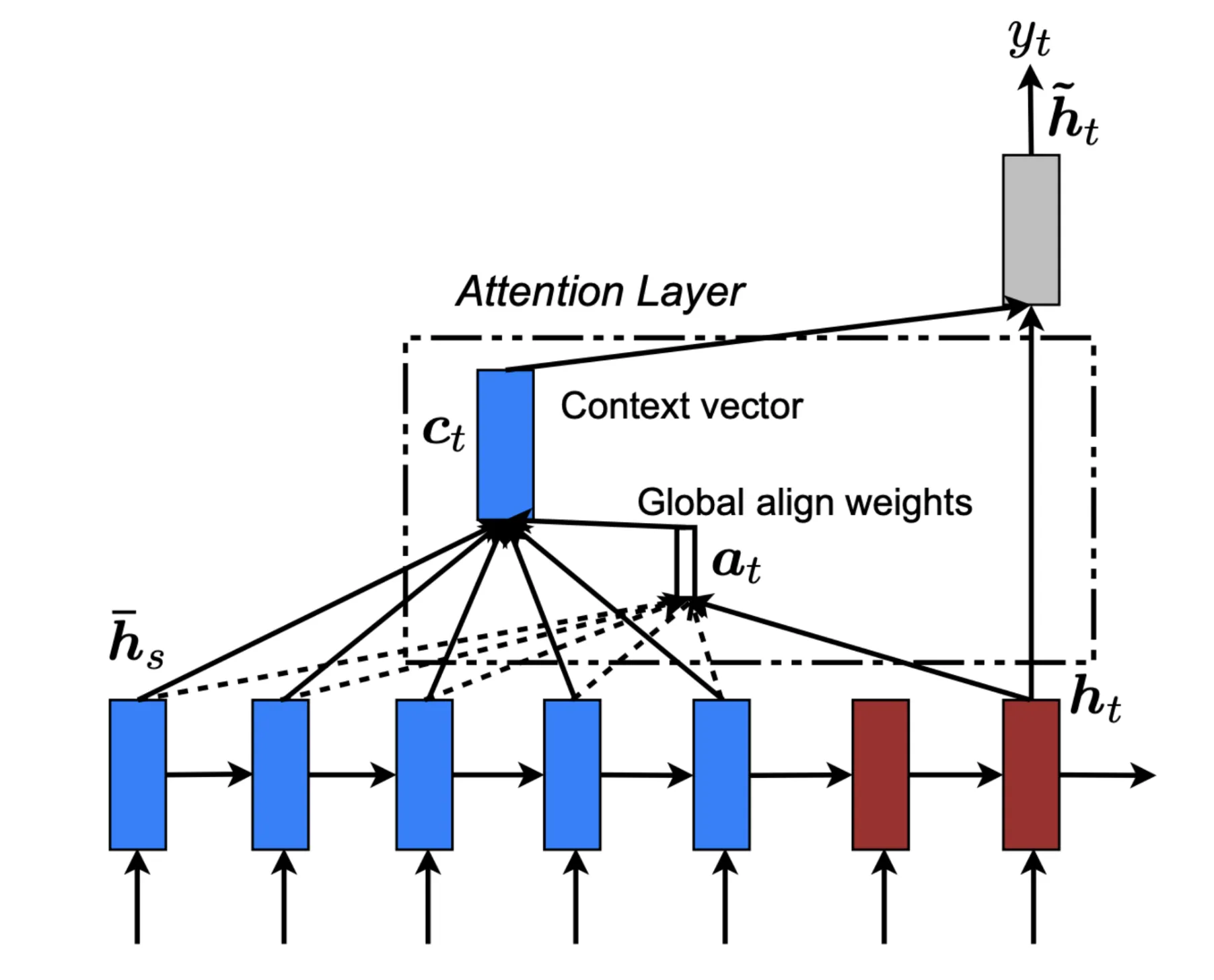
What’s cool is how a contemporary LLM remixes these design concepts in production-ready methods. I positively suggest studying the Gemma paper on how they make the most of the mixture of those two methods.
Sensible Normalization Methods
LayerNorm, RMSNorm, Pre-Norm, Put up-Norm, QK-Norm… seems like a shampoo aisle, proper? However these tiny tweaks really make an enormous distinction.
Pre-Norm stabilizes gradients in deep networks. With out it, your loss can explode midway via coaching, and also you’ll be crying over hours of wasted compute. (Sure, I’ve been there.)
RMSNorm is cheaper, less complicated, and sometimes simply pretty much as good. No imply subtraction, simply scales by variance. Saves reminiscence, speeds issues up.
QK-Norm normalizes queries and keys inside consideration. Retains values sane, prevents them from going wild like a toddler on sugar.
The OLMo 2 paper confirmed how a lot stability these small tweaks add. Truthfully, normalization is like seasoning salt whereas cooking: a pinch in the correct amount could make it scrumptious. Nevertheless, too little or an excessive amount of, and your entire coaching “dish” collapses right into a salty/bitter mess.
No Positional Embeddings (NoPE)
This one truthfully shocked me. Some fashions simply ditch positional embeddings fully. No absolute, no relative, nothing. They simply depend on causal masking to determine the order.
And weirdly? It really works. Fashions really generalize higher to longer sequences than they noticed throughout coaching. It’s like instructing a dancer rhythm by really feel as an alternative of counting “1, 2, 3, 4.” They simply get it.
SmolLM3 makes use of NoPE in some layers, proving you don’t at all times want fancy positional hacks. The paper Rope to Nope and Again Once more: A New Hybrid Consideration Technique dives into this extra in order for you the geeky particulars.
Not mainstream but, however positively one thing to keep watch over as it would simply be the key sauce for dealing with ultra-long contexts.
Enjoying with Depth vs Width
Do you construct deep and slim or shallow and extensive? There’s no silver bullet right here. It’s all about what your {hardware} can deal with and how briskly you want solutions.
- Deep has extra layers. Nice for constructing a wealthy representational hierarchy, however will be slower to coach.
- Large has fewer layers. Higher parallelism, sooner inference, simpler on sure {hardware}.
Case research: GPT-OSS goes extensive, Qwen3 goes deep. Each crush it.
Consider it like athletes: sprinters vs marathon runners. Totally different builds, completely different strengths, similar elite outcomes.
Consideration Biases & Sinks
Consideration layers typically drop bias phrases to avoid wasting parameters. However some fashions are bringing them again. Biases act like tiny steering wheels by serving to consideration lock onto necessary alerts.
Then there are consideration sinks: particular tokens that every little thing attends to. Consider them like “anchor factors” within the sequence. They stabilize long-context conduct.
GPT-OSS makes use of each. Typically old-school concepts come again in vogue!
Hybrid Blocks & Gated Variants
Not all blocks in trendy LLMs need to be boring, similar Transformer layers. Some fashions combine consideration layers with gated blocks, state-space layers, or different light-weight modules.
Why? Energy + effectivity. It’s like a relay race crew, some runners are sprinters and a few are endurance champs, however collectively they crush it.
Working example: Qwen3-Subsequent mixes Gated Consideration and DeltaNet-style blocks. Completely experimental, however tremendous thrilling.
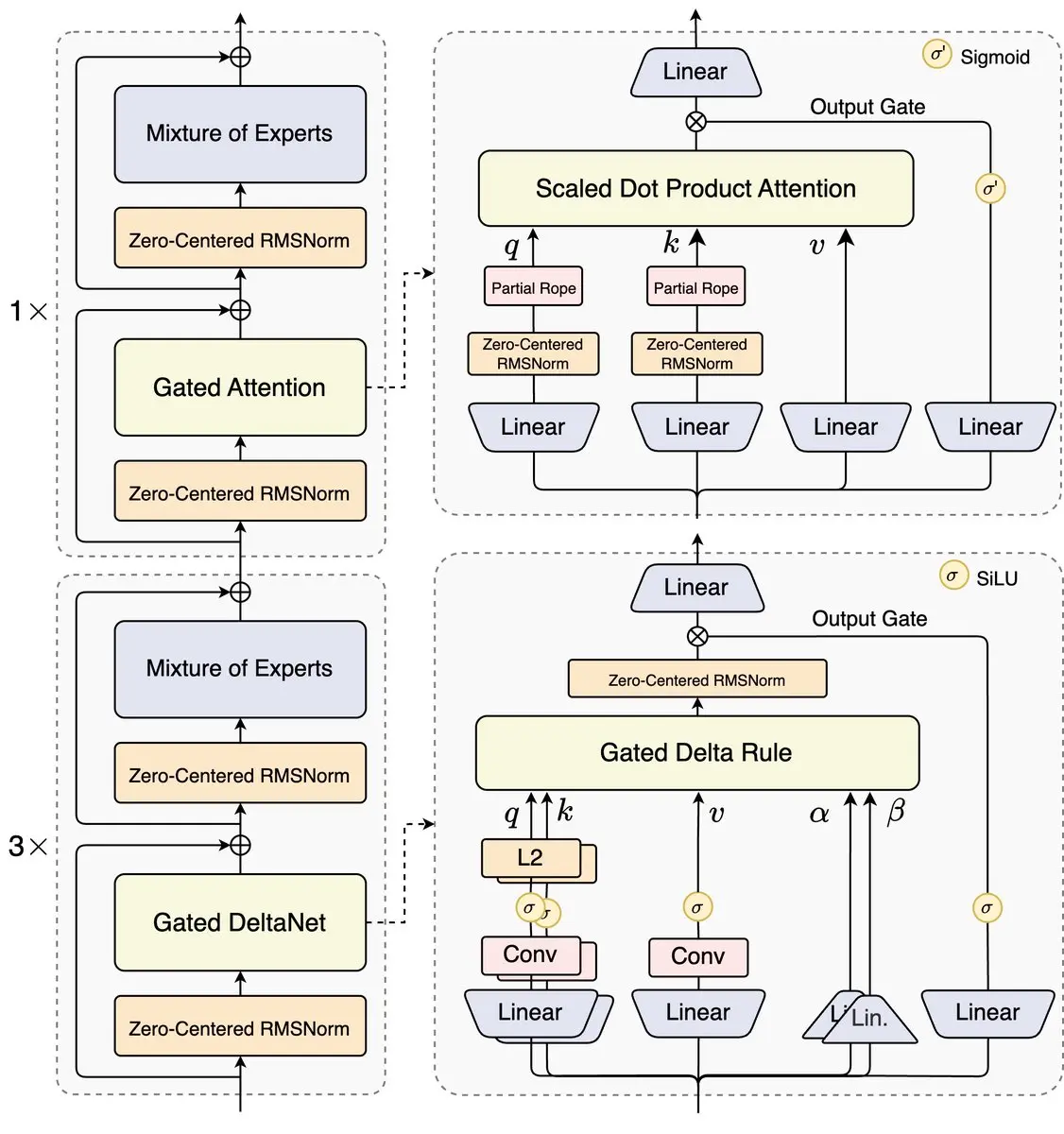
Truthfully, this hits a bit nostalgia for me as I grew up in an period of gates in NLP. LSTMs, GRUs have been the good architectures on the block.
Seeing gates make a comeback in trendy Transformers jogs my memory why foundations nonetheless matter. Trendy AI scientists shouldn’t simply chase the most recent traits since typically the previous methods come in useful in methods you by no means anticipate.
Multi-Token Prediction (MTP)
Historically, LLMs predict one token at a time. Gradual, painstaking, like pecking every letter on a typewriter.
MTP says: Why not predict a number of tokens directly? Practice the mannequin to see forward a bit, and mix it with speculative decoding. It results in sooner coaching, sooner inference, similar and even higher efficiency.
It’s like typing with autocomplete on steroids. You’re not pecking letter by letter anymore; you’re mainly sliding over entire phrases, typically phrases, in a single go. Qwen3-Subsequent loves this trick, and it’s one of many causes it feels snappy regardless of being an enormous mannequin.
Right here’s the unique MTP paper so that you can get extra context about this method.
Key Highlights
Alright, let’s zoom out and take inventory. We’ve talked about 10 design methods {that a} trendy LLM makes use of to punch method above its weight. What actually issues?
Reminiscence & Effectivity: MLA and GQA are lifesavers in case your KV cache is exploding. Compressing keys and values, sharing projections, results in reminiscence being saved with out killing efficiency. Sliding window + international hybrids? Identical thought. Most tokens don’t care about the entire context, so give them native consideration. Sprinkle in international layers when wanted, like Gemma 3 does.
Capability & Scaling: MoE with shared consultants, hybrid blocks, and depth vs width decisions show there’s no single proper reply. Want large capability with out slowing inference? Sparse MoE + shared professional. Choose parallelism and velocity? Go extensive. Have a look at Qwen3 (deep) vs GPT-OSS (extensive); they each work. Hybrid blocks give flexibility and effectivity. Gated layers, state-space blocks, attempt to combine and match.
Stability & Coaching: RMSNorm, Pre/Put up-Norm, QK-Norm, and dense layers earlier than MoE routing are the unsung heroes. They forestall exploding gradients, stabilize early coaching, and prevent from tearing your hair out. Tiny tweaks, large payoff.
Generalization & Context: NoPE, consideration sinks, sliding/international hybrids, all assist with lengthy sequences and make fashions generalize higher. Typically, throwing away positional embeddings really makes the mannequin stronger.
Enjoyable Takeaway: Numerous these methods are previous concepts reborn. Gates? Hey LSTMs and GRUs. MTP? Typing with autocomplete on steroids. Lesson: know your foundations. The previous stuff will save your life when the brand new stuff will get bizarre.
Suggestions (my take)
- Reminiscence tight? Begin with MLA, GQA, and sliding window consideration.
- Scale good? Sparse MoE + shared professional.
- Stabilize coaching? Don’t skip normalization methods and dense prep layers.
- Latency a priority? Select depth vs width properly.
- Lengthy-context wanted? Attempt NoPE, consideration sinks, and hybrid consideration.
Conclusion
Right here’s the underside line: a contemporary LLM design isn’t nearly “larger = higher.” It’s a mixture of effectivity hacks, scaling methods, stability tweaks, and generalization methods. Put them collectively thoughtfully, and also you get a mannequin that’s quick, highly effective, and truly usable.
Understanding why these methods work is extra necessary than simply copying them. The previous concepts, resembling gates, normalization, and cautious routing, hold coming again and saving your GPU, your sanity, or each.
On the finish of the day, constructing LLMs is an element engineering, half artwork, and half managed chaos. Nail the foundations, sprinkle in intelligent hacks, and also you’ve received a mannequin that doesn’t simply exist but additionally performs, scales, and impresses. And truthfully, that’s far more enjoyable than simply chasing the most recent hype.
Nonetheless inquisitive about these methods that assist design a contemporary LLM? Be happy to take a look at Sebastian Raschka’s Weblog, the place he covers these matters in additional element!
Sanad is a Senior AI Scientist at Analytics Vidhya, turning cutting-edge AI analysis into real-world Agentic AI merchandise. With an MS in Synthetic Intelligence from the College of Edinburgh, he’s labored at prime analysis labs tackling multilingual NLP and NLP for low-resource Indian languages. Keen about all issues AI, he loves bridging the hole between deep analysis and sensible, impactful merchandise.
Login to proceed studying and luxuriate in expert-curated content material.