{kind=link}


TL;DR
- What’s federated studying? A privacy-first AI approach the place a number of events collaboratively prepare a shared mannequin with out sharing uncooked knowledge – perfect for domains like healthcare, finance, and IoT.
- In federated studying, a central AI mannequin is shipped to native gadgets or servers, skilled on native knowledge, and solely updates (not knowledge) are returned. These updates will be encrypted utilizing safe aggregation or different privacy-preserving methods.
- Key implementation challenges embody knowledge heterogeneity, communication overhead, mannequin convergence points, and governance complexities
Synthetic intelligence (AI) guarantees sharper insights, quicker selections, and leaner operations. Each group desires in.
However AI thrives on knowledge. But most of that knowledge is delicate, and world rules like GDPR, HIPAA, and CCPA are tightening the foundations on the way it’s dealt with.
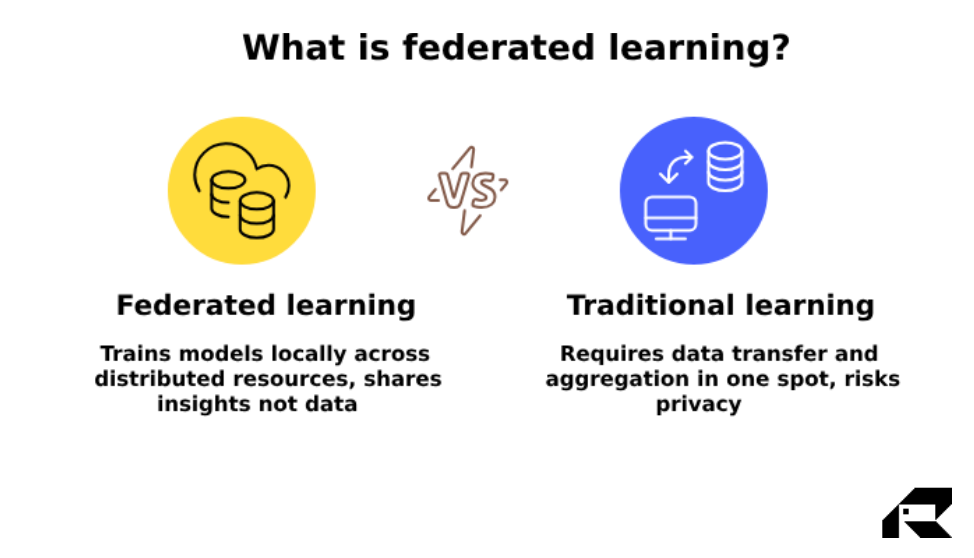
Conventional AI programs require all knowledge to be pulled into one place. That’s dangerous. It creates privateness publicity, compliance complications, and severe reputational threats. For enterprise leaders, it’s a troublesome alternative: unlock the total energy of AI or play it protected with knowledge.
Federated studying presents a brand new path – one which protects knowledge privateness with out slowing innovation.
On this article, our AI consultants clarify what federated studying is, the way it will help your enterprise, and which challenges to count on throughout implementation.
The way forward for data-driven progress is non-public. And it’s already right here.
What’s federated studying, and the way does it work?
With federated studying, it’s AI that travels – your knowledge stays safely the place it’s.
Historically, coaching an AI mannequin meant gathering all of your knowledge in a single central place – typically a cloud server – earlier than the training may start. That strategy creates important privateness dangers, regulatory challenges, and operational bottlenecks.
Federated studying flips this script.
As an alternative of shifting your knowledge, it strikes the mannequin.
Federated studying definition
So, what’s federated studying in AI?
Federated studying is a privacy-preserving machine studying strategy that allows a number of events to collaboratively prepare a shared AI mannequin with out transferring or exposing their underlying knowledge.
The AI mannequin is shipped out to the place the info already lives – on servers, edge gadgets, or inside completely different departments or enterprise models. Every participant trains the mannequin regionally. Solely the discovered insights (mannequin updates, not the precise knowledge) are then despatched again to the central server, the place they’re mixed into a better, extra correct mannequin.
Your knowledge stays precisely the place it’s, considerably decreasing privateness dangers. In a analysis venture analyzing over 3,000 federated studying deployments throughout completely different sectors, the contributors reported an 87.2% enchancment in GDPR compliance.
Press enter or click on to view picture in full dimension
Think about this analogy
To grasp federated studying higher, take into account an analogy of a touring professor. A world-class professor is instructing college students in several cities. As an alternative of flying all the scholars to at least one college (centralizing the info), the professor travels to every location, provides lectures, and learns from every group. She then compiles the findings from every metropolis to enhance her total course.
Nobody needed to depart their hometown, and nobody shared their private story past the classroom. That’s federated studying in motion.
Forms of federated studying
Members can construction federated studying in several methods relying on how the info is distributed and the way coordination is managed. Understanding these approaches is essential to deciding on the appropriate mannequin on your group or ecosystem.
1. Centralized federated studying
On this structure, a number of contributors prepare a shared mannequin regionally on their knowledge and ship updates to a central coordinating server. The server aggregates the insights and updates the worldwide mannequin.
Finest for organizations with a hub-and-spoke construction or clear central authority, akin to company headquarters coordinating throughout branches or subsidiaries.
2. Decentralized federated studying
This strategy doesn’t depend on a central server. Members share mannequin updates straight with one another in a peer-to-peer style. This setup will increase robustness and reduces single factors of failure.
Finest for consortiums or partnerships the place no single social gathering desires – or is allowed – to function the central coordinator.
3. Cross-silo federated studying
This federated studying sort is perfect when a number of trusted, long-term contributors, like departments inside an organization or enterprise companions, collaborate. The information stays siloed for authorized, moral, or operational causes, however the organizations nonetheless profit from a joint mannequin.
Finest for enterprises collaborating throughout enterprise models or organizations with aligned objectives (e.g., banks combating fraud collectively).
How federated studying works: a cycle of steady intelligence
Federated studying operates by means of an iterative, privacy-first coaching cycle, permitting organizations to construct highly effective AI fashions with out ever exchanging delicate knowledge.
Right here’s how federated studying operates, step-by-step:
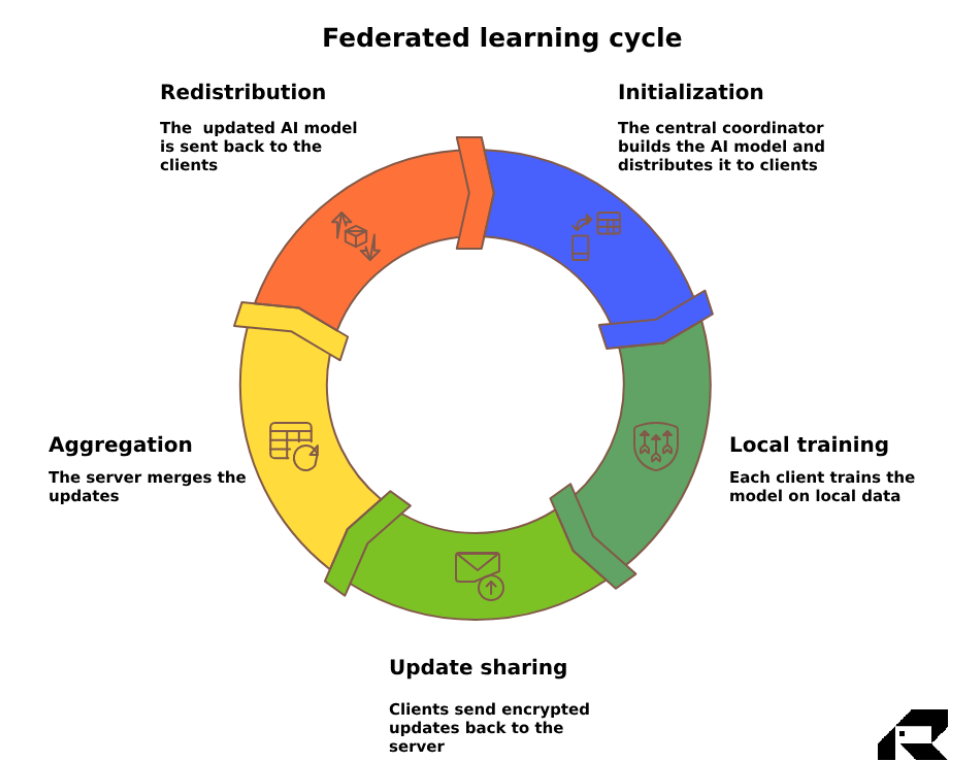
Step 1: Initialization. Distributing the blueprint
Federated studying begins with a central coordinator creating an preliminary model of the AI mannequin. This mannequin is shipped out to a gaggle of collaborating entities, referred to as contributors. These may be inner enterprise models, accomplice organizations, department places of work, and even edge gadgets like smartphones or IoT sensors.
Step 2: Native coaching. Intelligence on the supply
Every participant receives the mannequin and trains it independently utilizing solely their very own native knowledge. Throughout this stage, the AI mannequin learns from the distinctive patterns inside every dataset – whether or not it’s buyer conduct, transaction historical past, or operational metrics – creating localized intelligence with out danger of information publicity.
Step 3: Replace sharing. Sharing insights, not info
After native coaching, the contributors don’t ship their knowledge to the coordinator. They ship solely the mannequin updates – the refined parameters that replicate what the mannequin has discovered. These updates are sometimes smaller than uncooked knowledge and will be encrypted and compressed utilizing extra methods, defending each privateness and bandwidth.
Step 4: Aggregation. Combining intelligence securely
The central coordinator collects all these encrypted updates and intelligently combines them into an improved world mannequin. The coordinator goals to stability enter from all shoppers pretty, utilizing devoted methods, akin to federated averaging. To strengthen privateness even additional, superior strategies, akin to safe aggregation, make sure that even throughout this step, nobody can reverse-engineer particular person contributions.
Step 5: Redistribution. Smarter mannequin again within the subject
The improved world mannequin is redistributed to all contributors. With every cycle, the mannequin turns into extra correct, extra adaptive, and extra useful. This steady loop permits your AI programs to evolve in real-time, studying from reside knowledge with out ever centralizing it.
Press enter or click on to view picture in full dimension
Federated studying frameworks
Federated studying requires extra than simply a good suggestion – it calls for the appropriate instruments to coordinate distributed mannequin coaching, guarantee knowledge privateness, and scale throughout advanced environments. That’s the place federated studying frameworks are available in. Listed below are three main frameworks enabling sensible, privacy-first AI in the present day:
TensorFlow Federated (TFF)
Developed by Google, this open-source framework is constructed for large-scale, cross-device federated studying, particularly in cellular and edge environments. It gives a typical framework for each analysis and manufacturing, providing a high-level federated studying API for researchers and practitioners, in addition to a lower-level federated core API for extra granular management.
TFF integrates with the broader TensorFlow ecosystem and helps simulation, differential privateness, and safe aggregation. TFF additionally contains sturdy simulation capabilities for testing algorithms in managed environments and helps customizable aggregation algorithms like federated averaging.
Best for enterprises already utilizing TensorFlow, particularly for consumer-facing apps, cellular options, or edge AI.
PySyft
This federated studying framework is an open-source Python library created by OpenMined. PySyft is targeted on privacy-preserving machine studying. It helps federated studying, safe multiparty computation, and differential privateness and integrates with each PyTorch and TensorFlow.
Best for extremely delicate sectors that want robust privateness ensures, like healthcare and finance, and for integrating with present PyTorch or TensorFlow workflows.
Flower (FLwr)
Flower is a light-weight, open-source federated studying framework designed for optimum flexibility. Its key benefit is supporting a number of ML libraries (PyTorch, TensorFlow, and scikit-learn). Flower scales nicely throughout various environments and works throughout cellular, embedded, and cloud-based programs. It’s language- and ML framework-agnostic, which allows engineers to port present workloads with minimal overhead and gives researchers with the pliability to experiment with novel approaches.
Best for fast prototyping, analysis, and scalable manufacturing throughout various ML frameworks.
Federated studying: real-world strategic influence
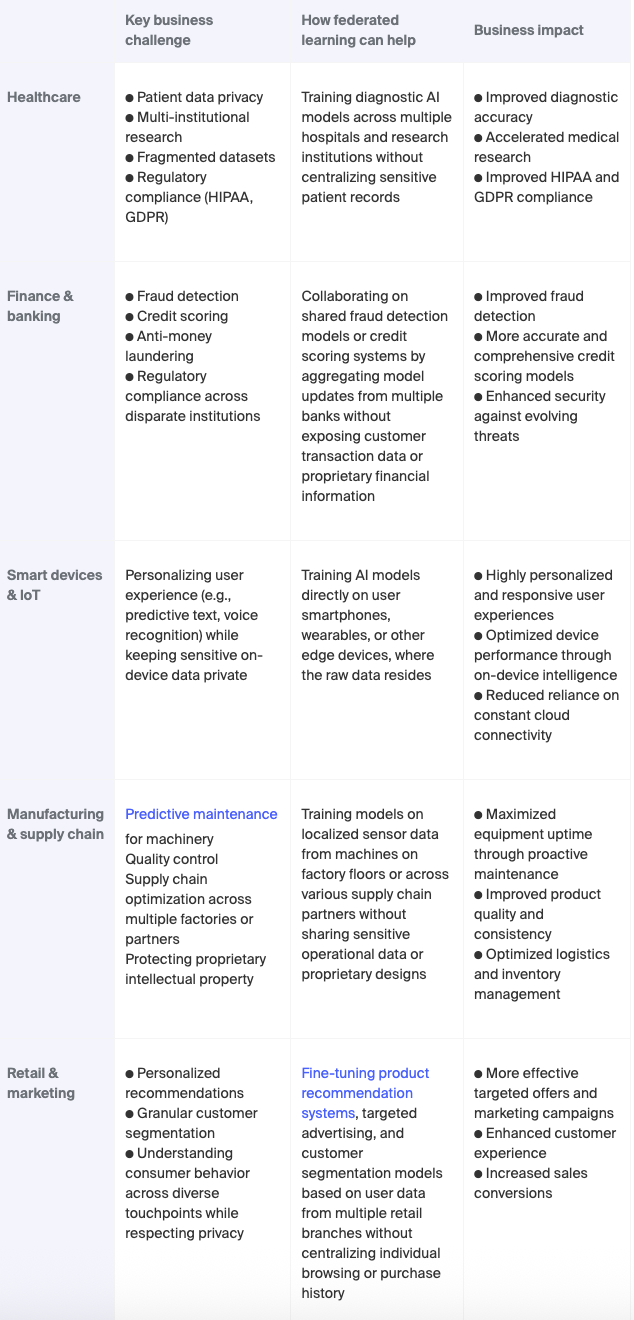
Federated studying just isn’t a theoretical idea; it’s a confirmed, actively deployed expertise that’s remodeling industries in the present day. Beneath are some strategic federated studying functions in several industries.
Federated studying examples
Johns Hopkins led the FLARE venture, the place 42 hospitals throughout 12 international locations participated in federated studying. They skilled AI fashions on a mixed dataset of 6.3 million medical photos with out ever exchanging uncooked affected person knowledge. The venture achieved a outstanding 94.2% diagnostic accuracy in detecting pulmonary embolism.
When examined in real-life settings, a federated learning-enabled AI mannequin demonstrated a 28.7% enchancment in fraud detection accuracy and a 93.7% discount in non-public knowledge publicity in comparison with conventional strategies. In one other experiment, an AI mannequin skilled by means of federated studying may detect fraud with a 15%-30% greater accuracy.
Google makes use of federated studying to enhance autocorrect performance on its Gboard keyboard. To preserve energy and bandwidth, coaching solely happens when a tool is idle – charging and related to Wi-Fi. Apple additionally applies this expertise to refine Siri’s voice recognition, guaranteeing consumer knowledge like voice instructions and search historical past stay on the gadget.
Siemens remodeled its printed circuit board (PCB) manufacturing high quality management utilizing federated studying. Going through strict knowledge privateness necessities throughout its world manufacturing community, the corporate carried out a collaborative AI resolution that allowed a number of services to collectively prepare anomaly detection fashions with out ever sharing delicate manufacturing knowledge. The corporate deployed the ensuing mannequin at two manufacturing websites and witnessed an accuracy of 98% in anomaly detection, in comparison with 84% for a similar mannequin earlier than retraining.
A serious style model confronted a expensive problem: decreasing excessive clothes return charges brought on by inaccurate dimension suggestions. To resolve this challenge with out compromising buyer privateness, they adopted federated studying, enabling their AI mannequin to study from regional match preferences and particular person buy histories whereas protecting all knowledge decentralized. In pilot testing, the mannequin delivered a 35% enchancment in dimension advice accuracy, serving to clients discover their excellent match.
Federated studying implementation challenges: what to be careful for
Whereas federated studying presents highly effective advantages, implementing it at scale isn’t with out hurdles. Most of the similar qualities that make this strategy interesting, akin to knowledge decentralization, privateness preservation, and cross-organization collaboration, additionally introduce distinctive complexities.
So, what are the challenges of federated studying implementation?
Half 1: Technical challenges in federated studying
Implementing federated studying at scale introduces a variety of technical complexities that differ considerably from conventional AI workflows.
Problem 1: Knowledge & system heterogeneity
In federated studying, every collaborating gadget or group typically has distinctive datasets and system environments. This implies knowledge isn’t distributed evenly or persistently. It’s typically non-independent and identically distributed (non-IID). For instance, one automotive plant may gather steady, real-time engine efficiency metrics, whereas one other solely captures threshold-based fault codes throughout routine upkeep.
On the similar time, the gadgets themselves – whether or not smartphones, edge sensors, or enterprise servers – have extensively various computing energy, reminiscence, community connectivity, and uptime. Some are always-on, high-performance machines. Others could also be battery-powered gadgets with restricted connectivity. This variation in computing energy, reminiscence, and community reliability results in important variations in how rapidly and reliably shoppers can full native coaching duties.
How ITRex will help
We design adaptive aggregation methods, fine-tune native replace schedules, and apply superior methods like personalised federated studying and area adaptation. Our engineers additionally optimize runtime environments to accommodate diverse gadget capabilities, guaranteeing inclusivity with out sacrificing efficiency.
Problem 2: Communication overhead & infrastructure constraints
Federated studying requires fixed communication between a central coordinator and numerous distributed shoppers. In follow, this implies mannequin updates (even when small) are exchanged throughout hundreds, and even hundreds of thousands, of gadgets in each coaching spherical. In cellular and IoT environments, this will create terabytes of information site visitors, leading to severe bandwidth pressure, excessive latency, and unsustainable operational prices.
Furthermore, communication protocols typically depend on synchronous updates. Which means all chosen shoppers should report again earlier than aggregation can happen. However in real-world deployments, shoppers could also be offline, underpowered, or on unstable networks. This will halt coaching solely or introduce unacceptable delays.
How ITRex will help
We deploy communication-efficient protocols akin to mannequin replace compression, quantization, and asynchronous coaching workflows that remove bottlenecks and cut back bandwidth dependency. Our crew additionally helps architect hybrid edge-cloud infrastructures to optimize knowledge circulate even in low-connectivity environments.
Problem 3: Mannequin convergence & high quality management
In federated studying, attaining secure, high-quality mannequin convergence is much harder than in centralized machine studying. This is because of each knowledge and programs heterogeneity, which trigger native fashions to “drift” in several instructions. When these native updates are aggregated, the ensuing world mannequin might converge slowly or in no way. There’s additionally the chance of “catastrophic forgetting,” the place a mannequin loses beforehand discovered data because it adapts to new knowledge.
One other challenge is validation. Since uncooked knowledge stays on consumer gadgets, it’s troublesome to determine a single floor reality to watch studying progress.
How ITRex will help
We implement sturdy aggregation strategies (e.g., FedProx, adaptive weighting), develop good participant choice insurance policies, and design simulation environments that approximate convergence below real-world situations. To deal with validation blind spots, we apply privacy-preserving analysis methods that provide you with visibility into mannequin efficiency with out violating compliance.
Half 2: Enterprise & organizational hurdles in federated studying
Past the technical structure, federated studying introduces advanced enterprise, authorized, and operational dynamics.
Problem 4: Privateness & safety vulnerabilities
Whereas federated studying is widely known for preserving privateness by protecting uncooked knowledge native, it’s not resistant to exploitation. The alternate of mannequin updates (e.g., gradients or weights) between shoppers and the central server introduces a brand new assault floor. Refined adversaries can launch inference assaults to reverse-engineer delicate enter knowledge or determine collaborating customers. In additional extreme circumstances, attackers might inject malicious updates that distort the worldwide mannequin for private or aggressive acquire.
In contrast to conventional centralized programs, federated environments are uniquely weak to insider threats, the place compromised or malicious contributors submit dangerous updates. Concurrently, contributors should belief that the central server isn’t misusing their contributions.
How ITRex will help
We take a multi-layered safety strategy, combining differential privateness, safe aggregation protocols, and anomaly detection methods to watch for irregular consumer conduct. We additionally implement sturdy aggregation algorithms that neutralize malicious inputs and supply cryptographic protections.
Problem 5: Governance & stakeholder alignment
Federated studying turns AI right into a collaborative train, however collaboration with out governance results in friction. In cross-company or cross-department deployments, possession and accountability develop into a problem. Who holds mental property rights to the collectively skilled mannequin? Who’s liable if it produces biased or incorrect outcomes? What occurs if a participant decides to exit the federation and calls for their knowledge be faraway from the mannequin?
To complicate issues much more, AI rules, just like the EU AI Act, are evolving quickly, typically introducing strict obligations round transparency and equity. Additionally, merely deleting a accomplice’s knowledge doesn’t essentially take away their influence on the mannequin except the remaining shoppers retrain the mannequin from scratch, which is expensive and impractical.
How we assist
We assist you in establishing clear federated studying governance frameworks earlier than deployment begins. This contains defining IP possession, legal responsibility, mannequin contribution rights, and participant exit protocols. For superior use circumstances, we provide mannequin unwind methods to reverse the affect of eliminated knowledge, avoiding the necessity for expensive full retraining.
Accomplice with ITRex to implement federated studying with confidence
Whereas federated studying presents clear strategic benefits, placing it into follow takes extra than simply organising the expertise. Organizations have to handle advanced knowledge environments, put robust governance in place, and tackle the distinctive dangers that include working distributed AI programs. Many corporations don’t have these capabilities in-house and have to search for an exterior AI improvement accomplice.
Our experience in guiding your federated studying journey
ITRex makes a speciality of translating the profound promise of federated studying into tangible enterprise worth on your group. We provide:
- Sturdy AI governance and coverage improvement. Our knowledge technique consultants design robust governance fashions to make sure accountable, compliant AI use.
- Safe structure design and implementation. We construct scalable, safe federated studying programs tailor-made to your infrastructure, making use of superior privateness methods and our confirmed cross-industry AI and Gen AI experience.
- Threat mitigation and bias administration. Our crew proactively addresses threats like knowledge leakage, poisoning, and bias, constructing truthful, clear, and high-performing fashions.
- Pilot program technique and scaling. We lead federated studying pilot packages and AI proof-of-concept (PoC) tasks that show actual worth, then scale them throughout your enterprise. You will discover extra about our AI PoC providers right here.
FAQs
- How does federated studying enhance privateness in AI programs?
Federated studying enhances privateness by protecting uncooked knowledge on native gadgets or servers, sharing solely encrypted mannequin updates. This minimizes publicity dangers and helps compliance with rules like GDPR and HIPAA.
- How does federated studying differ from conventional centralized machine studying?
In contrast to centralized machine studying, which requires aggregating all knowledge in a single location, federated studying trains AI fashions throughout distributed sources. It brings the mannequin to the info – decreasing knowledge motion, enhancing safety, and enabling cross-organizational collaboration with out sharing proprietary info.
- How does federated studying deal with imbalanced or skewed knowledge distributions?
Federated studying can battle with uneven or biased knowledge throughout contributors. However there are superior aggregation methods and personalization methods to assist stability contributions and enhance total mannequin equity and efficiency. These methods embody federated averaging (combines mannequin updates from every participant, weighted by the quantity of native knowledge), federated proximal (provides a regularization time period to cut back the influence of outlier participant updates and stabilize coaching when knowledge throughout contributors may be very completely different), and clustering-based aggregation (teams contributors with related knowledge patterns and aggregates their updates individually earlier than merging).
Initially revealed at https://itrexgroup.com on July 10, 2025.
;