{kind=link}

Organizations usually battle to unify their information ecosystems throughout a number of platforms and companies. The connectivity between Amazon SageMaker and Snowflake’s AI Information Cloud affords a robust resolution to this problem, so companies can make the most of the strengths of each environments whereas sustaining a cohesive information technique.
On this submit, we show how one can break down information silos and improve your analytical capabilities by querying Apache Iceberg tables within the lakehouse structure of SageMaker straight from Snowflake. With this functionality, you may entry and analyze information saved in Amazon Easy Storage Service (Amazon S3) by AWS Glue Information Catalog utilizing an AWS Glue Iceberg REST endpoint, all secured by AWS Lake Formation, with out the necessity for advanced extract, remodel, and cargo (ETL) processes or information duplication. It’s also possible to automate desk discovery and refresh utilizing Snowflake catalog-linked databases for Iceberg. Within the following sections, we present learn how to arrange this integration so Snowflake customers can seamlessly question and analyze information saved in AWS, thereby enhancing information accessibility, lowering redundancy, and enabling extra complete analytics throughout your complete information ecosystem.
Enterprise use circumstances and key advantages
The aptitude to question Iceberg tables in SageMaker from Snowflake delivers vital worth throughout a number of industries:
- Monetary companies – Improve fraud detection by unified evaluation of transaction information and buyer habits patterns
- Healthcare – Enhance affected person outcomes by built-in entry to scientific, claims, and analysis information
- Retail – Enhance buyer retention charges by connecting gross sales, stock, and buyer habits information for customized experiences
- Manufacturing – Increase manufacturing effectivity by unified sensor and operational information analytics
- Telecommunications – Scale back buyer churn with complete evaluation of community efficiency and buyer utilization information
Key advantages of this functionality embody:
- Accelerated decision-making – Scale back time to perception by built-in information entry throughout platforms
- Value optimization – Speed up time to perception by querying information straight in storage with out the necessity for ingestion
- Improved information constancy – Scale back information inconsistencies by establishing a single supply of reality
- Enhanced collaboration – Enhance cross-functional productiveness by simplified information sharing between information scientists and analysts
Through the use of the lakehouse structure of SageMaker with Snowflake’s serverless and zero-tuning computational energy, you may break down information silos, enabling complete analytics and democratizing information entry. This integration helps a contemporary information structure that prioritizes flexibility, safety, and analytical efficiency, in the end driving sooner, extra knowledgeable decision-making throughout the enterprise.
Resolution overview
The next diagram exhibits the structure for catalog integration between Snowflake and Iceberg tables within the lakehouse.
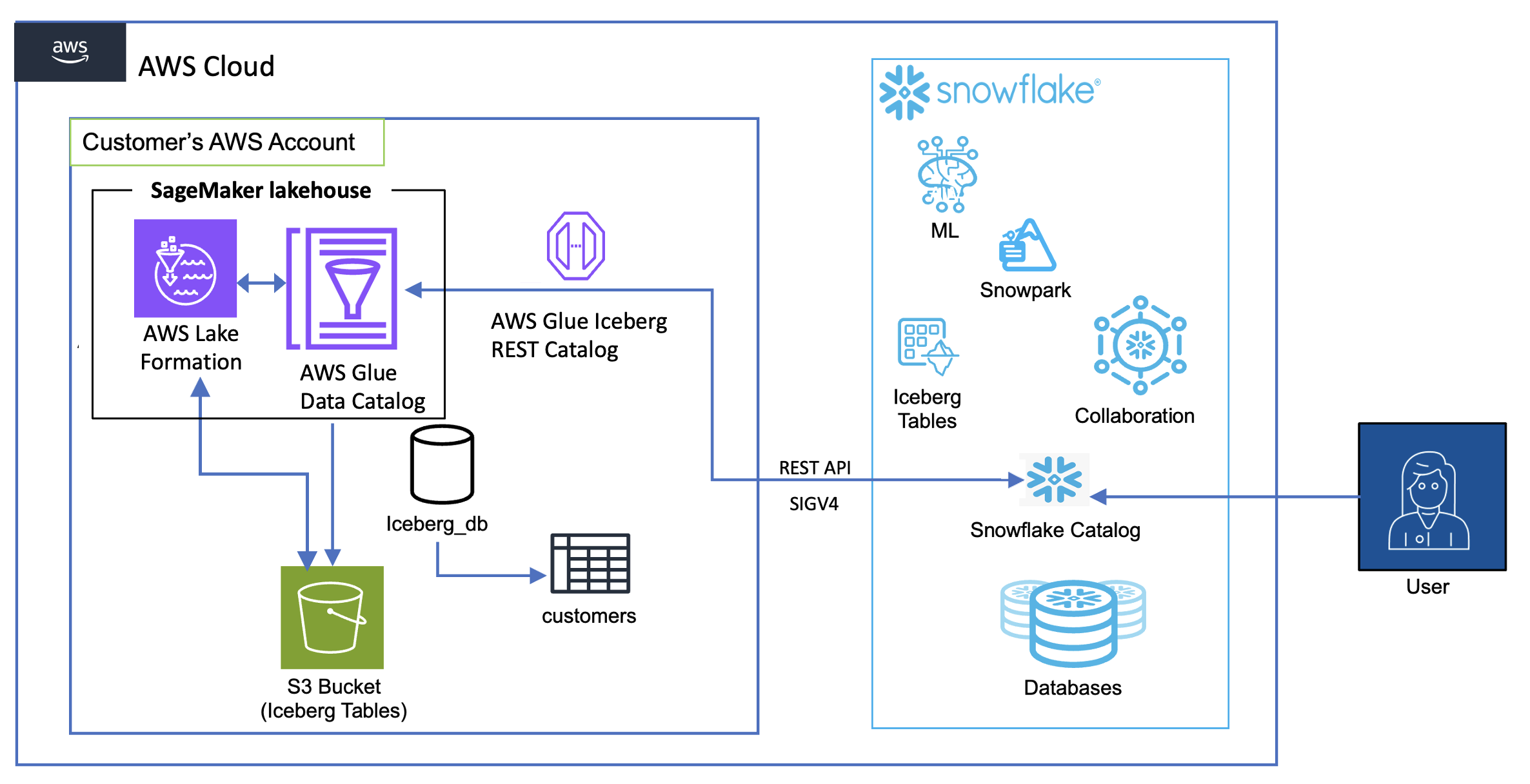
The workflow consists of the next elements:
- Information storage and administration:
- Amazon S3 serves as the first storage layer, internet hosting the Iceberg desk information
- The Information Catalog maintains the metadata for these tables
- Lake Formation supplies credential merchandising
- Authentication stream:
- Snowflake initiates queries utilizing a catalog integration configuration
- Lake Formation vends momentary credentials by AWS Safety Token Service (AWS STS)
- These credentials are routinely refreshed based mostly on the configured refresh interval
- Question stream:
- Snowflake customers submit queries towards the mounted Iceberg tables
- The AWS Glue Iceberg REST endpoint processes these requests
- Question execution makes use of Snowflake’s compute assets whereas studying straight from Amazon S3
- Outcomes are returned to Snowflake customers whereas sustaining all safety controls
There are 4 patterns to question Iceberg tables in SageMaker from Snowflake:
- Iceberg tables in an S3 bucket utilizing an AWS Glue Iceberg REST endpoint and Snowflake Iceberg REST catalog integration, with credential merchandising from Lake Formation
- Iceberg tables in an S3 bucket utilizing an AWS Glue Iceberg REST endpoint and Snowflake Iceberg REST catalog integration, utilizing Snowflake exterior volumes to Amazon S3 information storage
- Iceberg tables in an S3 bucket utilizing AWS Glue API catalog integration, additionally utilizing Snowflake exterior volumes to Amazon S3
- Amazon S3 Tables utilizing Iceberg REST catalog integration with credential merchandising from Lake Formation
On this submit, we implement the primary of those 4 entry patterns utilizing catalog integration for the AWS Glue Iceberg REST endpoint with Signature Model 4 (SigV4) authentication in Snowflake.
Conditions
You have to have the next conditions:
The answer takes roughly 30–45 minutes to arrange. Value varies based mostly on information quantity and question frequency. Use the AWS Pricing Calculator for particular estimates.
Create an IAM position for Snowflake
To create an IAM position for Snowflake, you first create a coverage for the position:
- On the IAM console, select Insurance policies within the navigation pane.
- Select Create coverage.
- Select the JSON editor and enter the next coverage (present your AWS Area and account ID), then select Subsequent.
- Enter
iceberg-table-accessbecause the coverage title. - Select Create coverage.
Now you may create the position and connect the coverage you created.
- Select Roles within the navigation pane.
- Select Create position.
- Select AWS account.
- Beneath Choices, choose Require Exterior Id and enter an exterior ID of your selection.
- Select Subsequent.
- Select the coverage you created (
iceberg-table-access coverage). - Enter
snowflake_access_rolebecause the position title. - Select Create position.
Configure Lake Formation entry controls
To configure your Lake Formation entry controls, first arrange the appliance integration:
- Check in to the Lake Formation console as an information lake administrator.
- Select Administration within the navigation pane.
- Choose Utility integration settings.
- Allow Enable exterior engines to entry information in Amazon S3 areas with full desk entry.
- Select Save.
Now you may grant permissions to the IAM position.
- Select Information permissions within the navigation pane.
- Select Grant.
- Configure the next settings:
- For Principals, choose IAM customers and roles and select
snowflake_access_role. - For Sources, choose Named Information Catalog assets.
- For Catalog, select your AWS account ID.
- For Database, select
iceberg_db. - For Desk, select
buyer. - For Permissions, choose SUPER.
- For Principals, choose IAM customers and roles and select
- Select Grant.
SUPER entry is required for mounting the Iceberg desk in Amazon S3 as a Snowflake desk.
Register the S3 information lake location
Full the next steps to register the S3 information lake location:
- As information lake administrator on the Lake Formation console, select Information lake areas within the navigation pane.
- Select Register location.
- Configure the next:
- For S3 path, enter the S3 path to the bucket the place you’ll retailer your information.
- For IAM position, select
LakeFormationLocationRegistrationRole. - For Permission mode, select Lake Formation.
- Select Register location.
Arrange the Iceberg REST integration in Snowflake
Full the next steps to arrange the Iceberg REST integration in Snowflake:
- Log in to Snowflake as an admin consumer.
- Execute the next SQL command (present your Area, account ID, and exterior ID that you simply supplied throughout IAM position creation):
- Execute the next SQL command and retrieve the worth for
API_AWS_IAM_USER_ARN:
DESCRIBE CATALOG INTEGRATION glue_irc_catalog_int;
- On the IAM console, replace the belief relationship for
snowflake_access_rolewith the worth forAPI_AWS_IAM_USER_ARN:
- Confirm the catalog integration:
SELECT SYSTEM$VERIFY_CATALOG_INTEGRATION('glue_irc_catalog_int');
- Mount the S3 desk as a Snowflake desk:
Question the Iceberg desk from Snowflake
To check the configuration, log in to Snowflake as an admin consumer and run the next pattern question:SELECT * FROM s3iceberg_customer LIMIT 10;
Clear up
To scrub up your assets, full the next steps:
- Delete the database and desk in AWS Glue.
- Drop the Iceberg desk, catalog integration, and database in Snowflake:
Be sure that all assets are correctly cleaned as much as keep away from surprising fees.
Conclusion
On this submit, we demonstrated learn how to set up a safe and environment friendly connection between your Snowflake atmosphere and SageMaker to question Iceberg tables in Amazon S3. This functionality may also help your group keep a single supply of reality whereas additionally letting groups use their most popular analytics instruments, in the end breaking down information silos and enhancing collaborative evaluation capabilities.
To additional discover and implement this resolution in your atmosphere, contemplate the next assets:
- Technical documentation:
- Associated weblog posts:
These assets may also help you to implement and optimize this integration sample on your particular use case. As you start this journey, keep in mind to begin small, validate your structure with take a look at information, and regularly scale your implementation based mostly in your group’s wants.
Concerning the authors