{kind=link}

As organizations evolve, they’ve developed separate, cloud-hosted knowledge repositories, often operating independently of one another. A pressing challenge lies in facilitating seamless cross-organizational discovery and access to knowledge across numerous knowledge lakes, each grounded in distinct skill sets. Organizations can utilize Information Mesh’s domain-oriented approach to decentralized knowledge possession and structure by addressing these four key ideas: treating knowledge as a product, offering self-serve knowledge infrastructure as a platform, implementing federated governance, and creating domain-specific frameworks that enable efficient knowledge sharing and collaboration.
In 2019, the company forged a strategic alliance to co-create the Digital Manufacturing Platform (DMP), designed to enhance manufacturing and logistics efficiency by 30% while reducing production costs by an equal percentage. The Data Processing Platform (DPP) was designed to facilitate seamless access to knowledge from shop-floor units and manufacturing processes by addressing integration complexities and providing standardized connections. Notwithstanding advancements in the platform’s functions, a significant challenge arose: sharing knowledge across multiple remote knowledge lakes stored in separate AWS accounts without having to consolidate data into a central repository? One other issue is identifying accessible knowledge saved across various knowledge lakes and facilitating a workflow to request data entry throughout enterprise domains within each plant. The current methodology relies heavily on manual processes, utilizing emails and basic communication, which not only increases overhead but also varies from one use case to another in terms of data governance. This blog post introduces and explores how VW utilized it to build their knowledge mesh, enabling streamlined data entry across multiple knowledge lakes. It prioritizes the key advantage, allowing knowledge providers to seamlessly publish knowledge assets directly to Amazon DataZone, thereby establishing a central knowledge hub for improved discoverability and accessibility. Furthermore, the publication provides code snippets that convey information through practical implementation.
Introduction to Amazon DataZone
As a cloud-based metadata management platform, our solution simplifies the process of discovering, organizing, sharing, and governing data stored across Amazon Web Services (AWS), on-premises infrastructure, and third-party sources. Amazon DataZone’s core features include a comprehensive enterprise knowledge catalog that enables users to search for existing knowledge, request access, and start working on data in days rather than weeks, fostering rapid insights and informed decision-making. The Amazon DataZone portal further features a personalized analytics expertise for knowledge assets through both a web-based application and API. Amazon DataZone streamlines knowledge sharing, providing users with accurate information tailored to their specific needs and goals through a governed process.
What are the key components of a well-designed information administration framework that integrates seamlessly with Amazon DataZone?
1. Governance: Establish clear policies and procedures to ensure data security, compliance, and integrity within the organization.
2. Discovery: Implement automated data discovery capabilities using Amazon SageMaker and Amazon Glue to identify, classify, and catalog data assets across the enterprise.
3. Profiling: Utilize Amazon Comprehend and Amazon Rekognition to create detailed profiles of your data, including metadata, schema, and semantic meaning.
4. Stewardship: Assign ownership and accountability for each data asset, ensuring that data is properly managed, maintained, and updated.
5. Integration: Leverage Amazon DataZone’s integration capabilities to connect with various systems, applications, and data sources, enabling seamless data exchange and processing.
6. Analytics: Utilize Amazon SageMaker, Amazon QuickSight, and other analytics services to analyze and gain insights from your data, driving business value and decision-making.
7. Security: Implement robust security controls, including access control lists (ACLs), encryption, and authentication mechanisms, to safeguard sensitive data and ensure compliance with regulatory requirements.
8. Auditing: Maintain a comprehensive audit trail using Amazon CloudWatch and Amazon S3 bucket logging to monitor data activity, detect potential issues, and address any compliance concerns.
9. Reporting: Generate detailed reports on data usage, access, and compliance status using Amazon QuickSight and Amazon SageMaker, enabling data-driven decision-making and risk mitigation.
10. Compliance: Ensure that your information administration framework complies with relevant regulations, such as GDPR, HIPAA, and CCPA, by implementing controls and monitoring mechanisms to track data handling and processing.
The data zone enables seamless integration with various data sources and provides a unified data catalog. It supports the discovery of data assets within your organization, allowing for effective collaboration across teams. Additionally, the data zone integrates with various data processing services like Amazon SageMaker, making it an ideal choice for machine learning workflows.
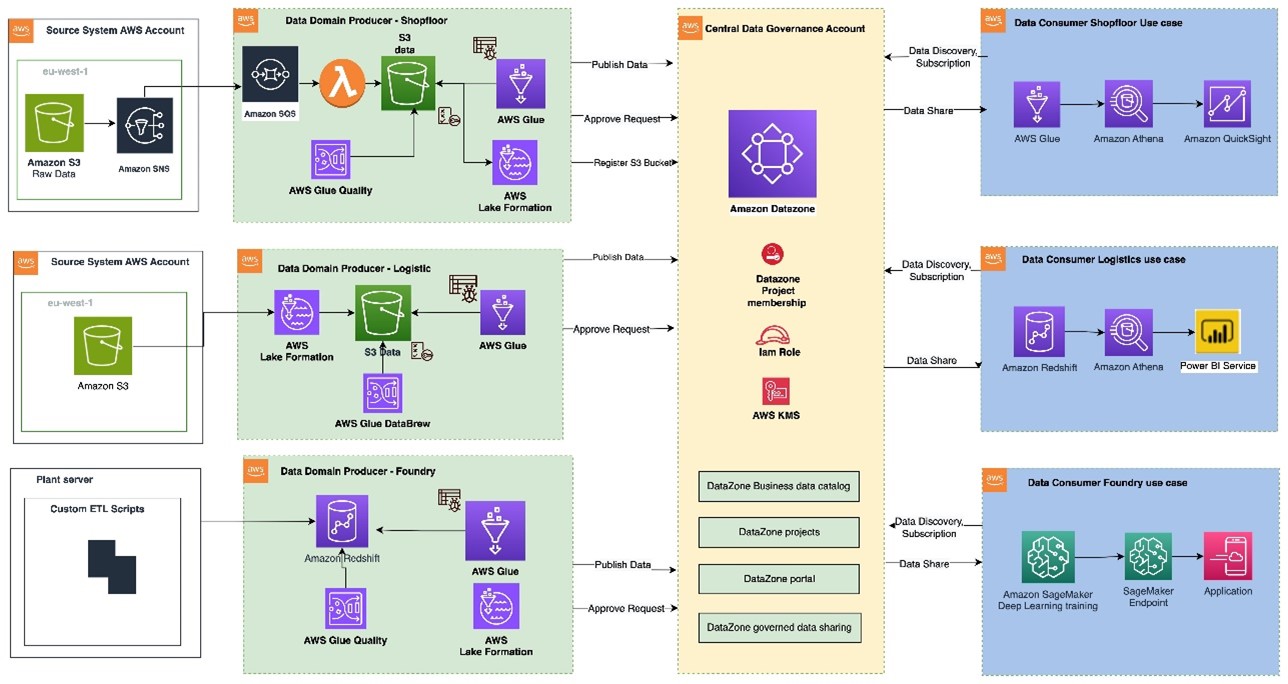
The structural diagram (Determine 1) illustrates a high-level design framework, grounded in the principles of the information mesh sample. The framework distinguishes between supply chain mechanisms, knowledge area creators (publishers of intellectual property), knowledge area users (consumers of information), and centralized management to highlight crucial aspects. This cross-account knowledge mesh aims to establish a scalable foundation for knowledge platforms, ensuring seamless collaboration between producers and consumers through robust governance mechanisms?
- A knowledge-area producer is situated within an AWS account, leveraging Amazon S3 buckets to store both raw and processed data. Producers integrate knowledge into their Amazon Simple Storage Service (S3) buckets through various pipeline processes they manage, in addition to utilizing personal and functional approaches. Data owners are accountable for the entire lifecycle of the data, from initial collection to a format suitable for external utilization.
- A knowledge area producer leverages a bespoke Extract, Transform, Load (ETL) framework, incorporating tools like to process data, utilize data profiling techniques to prepare the information asset (knowledge product), and subsequently catalog it within their designated .
- That a knowledge area producer prepares and stores the information asset on a desktop using AWS S3 copy?
- Producers of information areas leverage a designated datasource to run processes in Amazon’s DataZone, all managed seamlessly within their Central Governance account. The process effectively standardizes and deploys technical metadata across the entire organization’s knowledge catalog for each knowledge asset. Enterprise metadata can be seamlessly integrated by customers to provide contextual richness, relevant tags, and meaningful knowledge classification for their respective datasets. Producers’ management wants to share its approach, ensuring a seamless collaboration between the team’s lengthy processes and the way customers interact with them.
- Producers can catalog entries with AWS Glue from all their Amazon S3 buckets. The central governance account securely disseminates datasets to producers and customers via metadata linking, operating without any inherent understanding beyond the occasional log entry. Ownership of information remains with the creator.
- As Amazon DataZone enables seamless sharing, once knowledge is cataloged and published to the DataZone space, it can be easily disseminated to multiple client accounts.
- The Amazon DataZone Information Portal provides a customized interface for customers to discover, search, and initiate requests for subscribing to valuable knowledge assets via an online platform. The information area producer receives notifications of subscription requests within the Information Portal and exercises discretion in approving or rejecting these requests accordingly.
- As soon as accredited, the patron account can unlock courses teaching various analytics and machine learning concepts, enabling them to apply their newfound knowledge in diverse scenarios.
What are the primary goals and objectives of creating a Handbook course for publishing knowledge belonging to Amazon DataZone?
Developing a comprehensive course on publishing knowledge in Amazon DataZone requires considering the following key aspects:
1. **Defining the scope**: Clearly outline the purpose, target audience, and expected outcomes for the handbook.
2. **Establishing credibility**: Demonstrate expertise and authority in the field of data analytics and publishing through real-world examples or case studies.
3. **Organizing content**: Structure the course into logical modules or sections, focusing on practical applications, best practices, and innovative approaches to sharing knowledge.
4. **Creating engaging materials**: Use visual aids, interactive elements, and storytelling techniques to make complex concepts more accessible and memorable.
5. **Providing hands-on exercises**: Offer practical activities, quizzes, or challenges that allow learners to apply new skills and reinforce understanding.
6. **Incorporating feedback mechanisms**: Encourage participant engagement through discussion forums, surveys, or peer review processes to ensure continuous improvement and refinement of the course.
By addressing these essential elements, the Handbook course will effectively empower Amazon DataZone users with the knowledge and skills necessary to successfully publish their findings and share insights with others.
To successfully publish an information asset from a producer’s account, each asset must first be registered within Amazon DataZone as a viable source of information, making it available for client subscription and utilization. The guide provides comprehensive instructions on how to achieve this goal. In the absence of an automated registration process, all necessary tasks must be performed manually for each knowledge asset.
Can you use AWS Glue’s built-in support for data sharing by configuring a data share in your producer account and then connecting it to Amazon DataZone?
By leveraging the automated registration workflow, the step-by-step guide process can be streamlined and executed seamlessly for any new knowledge asset requiring printing, as well as for existing assets necessitating updates due to changes in their schema.
Streamline AWS Glue table publication to Amazon DataZone by condensing the step-by-step process.
The following structure outlines a framework for automating the publication of knowledge assets:
**Publishing Process**
1. **Validation**: Automated checks ensure that the knowledge asset meets specific criteria (e.g., completeness, relevance).
2. **Approval**: The knowledge asset is routed to relevant stakeholders for review and approval.
3. **Categorization**: The knowledge asset is categorized based on its content, format, or target audience.
4. **Tagging**: Relevant tags are assigned to the knowledge asset for easier discovery.
5. **Metadata Generation**: Automatically generated metadata (e.g., title, summary, keywords) aids searchability and discoverability.
6. **Quality Control**: A quality control check verifies that the published knowledge asset meets desired standards (e.g., formatting, consistency).
7. **Publication**: The validated, approved, categorized, tagged, and metadata-generated knowledge asset is published on a designated platform or repository.
8. **Maintenance**: Scheduled updates and maintenance ensure the knowledge asset remains relevant and accurate over time.
**Key Components**
1. **Knowledge Asset Types**: Define the types of knowledge assets to be published (e.g., articles, whitepapers, case studies).
2. **Validation Rules**: Establish specific criteria for validating knowledge assets (e.g., completeness, relevance).
3. **Approval Hierarchy**: Determine the approval process and hierarchy for knowledge assets.
4. **Categorization Framework**: Develop a framework for categorizing knowledge assets based on content, format, or target audience.
5. **Tagging Guidelines**: Establish guidelines for assigning relevant tags to knowledge assets.
6. **Metadata Generation Templates**: Create templates for automatically generating metadata (e.g., title, summary, keywords).
7. **Quality Control Standards**: Define desired standards for published knowledge assets (e.g., formatting, consistency).
Can structured data be used effectively in Amazon DataZone?
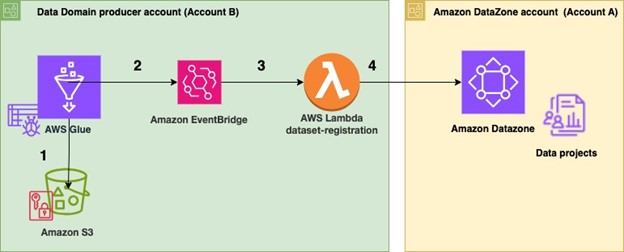
- In Producer Account B, relevant data is stored within an Amazon S3 bucket. An AWS Glue crawler is configured for the dataset to automatically create the schema using.
- As soon as configured, the AWS Glue crawler promptly crawls the specified Amazon S3 bucket and seamlessly updates the associated metadata. When the AWS Glue crawler successfully completes a job, a specific event is triggered and published to the default Amazon EventBridge bus.
- When an EventBridge rule is set up to recognize this occurrence, it triggers a dataset-registration operation.
- AWS Lambda executes a series of automated steps to register and publish datasets in Amazon DataZone seamlessly.
-
- AWS Lambda function operates to retrieve AWS Glue databases and Amazon S3 data for a dataset, triggered by an event-driven execution of the AWS Glue crawler following a profitable run.
- The code assumes the role of an Identity and Access Management (IAM) user in a central governance account, leveraging the account’s credentials to retrieve the Producer account ID, as well as the Amazon DataZone area ID and Challenge ID.
- The AWS DataZone Datalake blueprint is enabled within the producer account.
- It checks if the . Unless a deliberate decision to the contrary is made, the absence of atmospheric conditions prompts the activation of the atmosphere creation process. If the atmosphere does indeed exist, it will then proceed to the next logical step.
- The process successfully registers the Amazon S3 location of the dataset in Lake Formation, ensuring seamless integration within the producer account.
- During the Amazon DataZone challenge, the operation generates a comprehensive data supply and visually depicts its successful creation.
- The final step ensures that the data supply synchronization job within Amazon DataZone is initiated as needed. When new AWS Glue tables or metadata are created or updated, the information supply sync job is triggered.
Conditions
As part of this response, you’ll publish knowledge assets from a current AWS Glue database in a producer account into an Amazon DataZone region, provided that the following prerequisites must be met:
- Deploy?
- One AWS account serves as the information repository’s producer account (Account B), housing an AWS Glue dataset to be shared.
- The secondary AWS account serves as a centralized governance hub (Account A), where an Amazon DataZone area and challenge can be effectively deployed. The Amazon DataZone account – that’s the hub for data discovery and collaboration within your organization.
- Each of the AWS accounts belongs to the same owner.
- From the tables for which Amazon DataZone manages permissions effectively.
- In every AWS account, verify that the box is unchecked for Default permissions for newly created databases and tables under the Information Catalog settings within Lake Formation.

Can you confirm default permissions are cleared by running `ALTER DEFAULT PERMISSIONS REVOKE ALL ON` and then re-apply the desired permissions to ensure secure data access?
- Check into Account A (central governance account), ensuring you have the necessary credentials.
-
If your Amazon DataZone area is already encrypted using a key, follow these steps to add Account B (the producer account):
- The guarantee lies in creating a specific role for Account B, producer account, which assumes the designated Identity and Access Management (IAM) role. The role should possess the following authorizations:
- This Identity and Access Management (IAM) position is known as a crucial role within an organization’s security posture.
dz-assumable-env-dataset-registration-roleon this instance. With this role, you will have the flexibility to manage your workflow effectively and streamline your daily tasks.dataset-registrationLambda operate. Exchange theaccount-region,account id, andDataZonekmsKeyWithin the specified scope of this project, utilizing my available information and resources. The provided values determine the location where your Amazon DataZone area is established and the AWS KMS key employed to securely encrypt this sensitive data. - The following AWS account has been added to the belief relationship for this position, aligning with the next belief relationship in the organizational hierarchy. Exchange
ProducerAccountIdWith the AWS account ID from Account B (the knowledge area producer’s account).
- This Identity and Access Management (IAM) position is known as a crucial role within an organization’s security posture.
- The necessary instruments for deploying an answer using AWS CDK are sought.
Deployment Steps
Deploying the AWS CDK stack enables automatic registration of knowledge assets in the DataZone area after completing the prerequisites.
- Clone the repository from GitHub to your preferred Integrated Development Environment (IDE) by following these steps:
- Based on the repository folder, execute the following commands to build and deploy source code to Amazon Web Services (AWS).
- Log into AWS account B using the AWS CLI with your designated profile name.
- Guarantee you’ve got .
- The CDK atmosphere with instructions based on the repository folder exists. Exchange
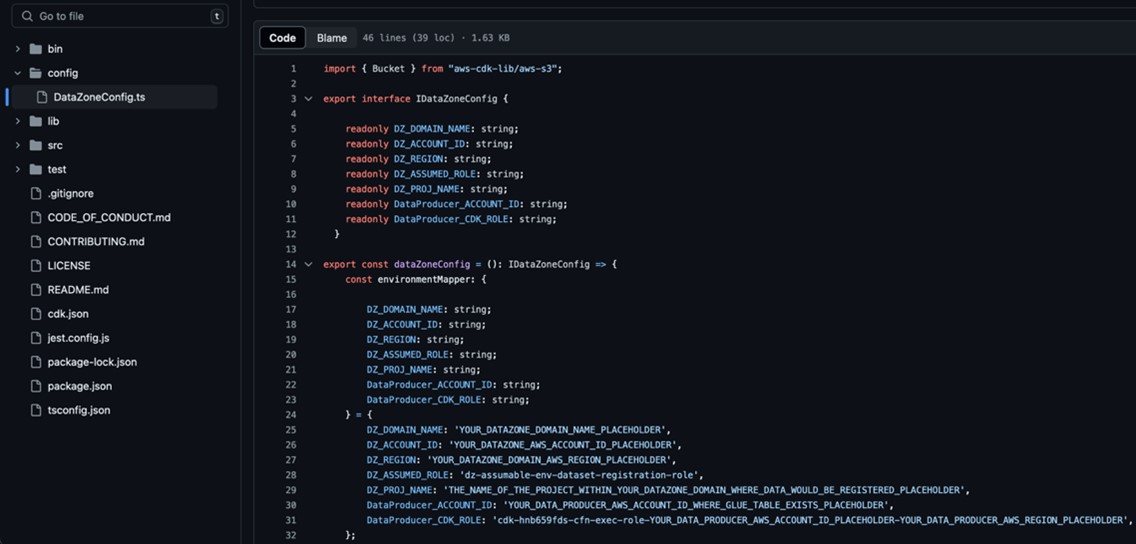
<PROFILE_NAME>With the profile title of your deployment account Account B. Bootstrapping is typically a one-time process and should not be repeated if an AWS account is already configured with the necessary resources. - Exchange the placeholder parameters (marked with the suffix
_PLACEHOLDER) within the fileconfig/DataZoneConfig.ts(Determine 4).
-
- What’s Behind the Curtain: Unlocking Insights in Your Amazon DataZone? who is the best player to have ever played in the nba?
- The AWS account identifier and region.
- The assumed IAM position, as per the stipulated guidelines.
- The deployment position beginning with
cfn-xxxxxx-cdk-exec-role-.
Edit the `DataZoneConfig.json` file carefully to ensure that your DataZone is properly configured for use.
- From within the AWS Lake Formation console’s navigation pane, select “Determine 5” to access IAM settings crucial for AWS CDK deployment initialization.
cfn-xxxxxx-cdk-exec-role-As a result, I am designated as an Administrator for Information Lake Directors. The IAM role requires permissions to create sources within Lake Formation, granting privileges analogous to those of an AWS Glue database. Without explicit grants of these permissions, the AWS CDK stack deployment will inevitably fail.
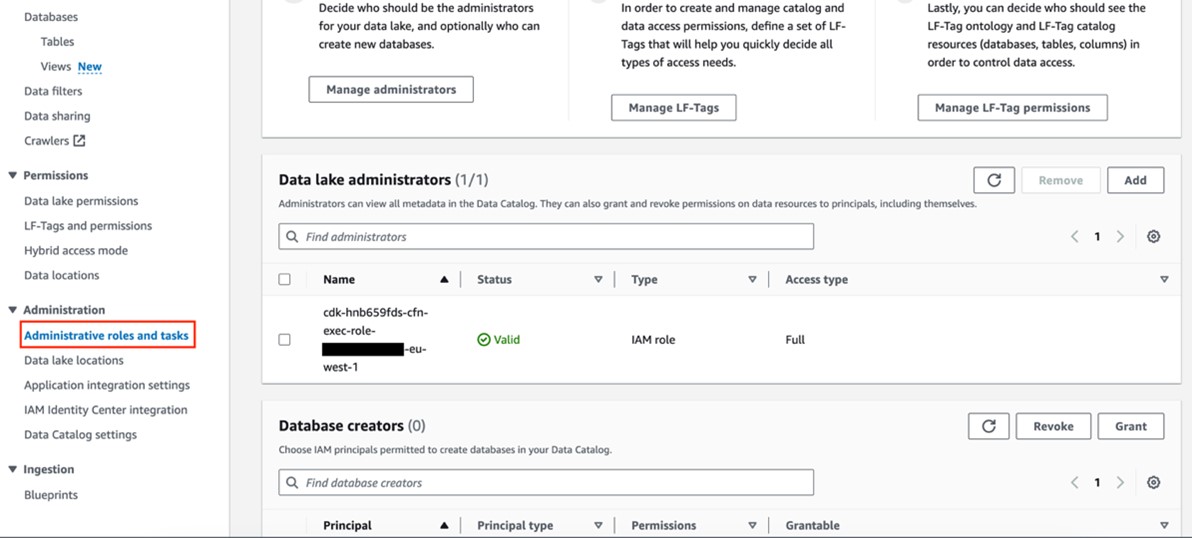
Can you add cfn-xxxxxx-cdk-exec-role to the Information Lake administrators?
- cdk deploy?
Throughout deployment, enter y If you wish to deploy adjustments for specific stacks as soon as possible? Do you want to deploy these adjustments (y/n)?
- After a successful deployment, sign in to your AWS Account B (Producer Account) and verify that the newly provisioned infrastructure is correctly set up. You need to see a list of deployed CloudFormation stacks as demonstrated in Section 6.
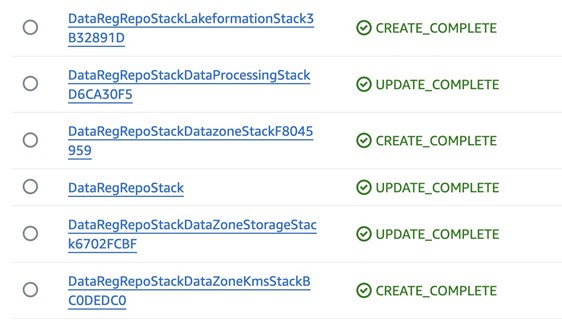
Determine 6: Deployed CloudFormation stacks
What benefits does automated knowledge registration bring to Amazon DataZone?
We employ the dataset as a template to showcase the automated knowledge registration process.
- Data unavailable, please provide the file.
- Log in to the producer account’s AWS account and access the Amazon S3 dashboard, locating the
DataZone-test-datasourceThe S3 bucket was configured to securely store sensitive data. A CSV file titled Determine_7 was uploaded to this designated storage location.
The analysis of seven datasets for determining the impact on business performance requires a comprehensive approach.
- The AWS Glue crawler is configured to execute on a daily schedule, running at the same specified hour each day. To test the crawler manually, navigate to the AWS Glue console, then select the desired option from the navigation menu. The on-demand crawler is initiated seamlessly.
DataZone-. After the crawler has executed, verify that a novel workspace has been established. - Navigate to the Amazon DataZone console within your central governance AWS account A, where the data sources were initially deployed. Select within the Navigation Pane the option labeled Determine 8.

Determine 8: Amazon DataZone domains
- Upon opening the Datazone Area, users will have access to the Amazon Datazone knowledge portal URL, located in the Determine 9 section. Choose and .

What are the URLs of Amazon’s DataZone knowledge portal?
- Discovering Your Strengths and Weaknesses Select the tab at the top of the window.

What drives innovation in data management?
- What innovative discoveries await us in this uncharted territory? We are about to uncover a treasure trove of fresh insights as we venture into the newly created knowledge supply.

Determine what valuable insights and trends can be gleaned from information sources within the Amazon DataZone area of the Amazon Web Services (AWS) portal.
- The information supply has been efficiently confirmed as printed.

What drives the determination of 12? The revealed knowledge portion highlights various information sources.
- Once the information sources have been printed. The info producer can . Once approved, customers can seamlessly access and utilize the available information through Determine 13, which effectively showcases knowledge discovery within the Amazon DataZone knowledge portal.

What insights can you uncover by analyzing instance data within the Amazon DataZone? Explore how to leverage instance knowledge discovery and unlock hidden patterns in your dataset.
Clear up
Utilize the subsequent procedures to sanitize the resources leveraged through the Cloud Development Kit (CDK).
- Delete all data from the two S3 buckets created in conjunction with this rollout to ensure a clean slate for future operations.
- What datasets reside in the Amazon DataZone challenge?
dataset-registrationLambda operate. - rm -rf *
Conclusion
Organizations can streamline their data governance by leveraging the power of AWS Glue and Amazon DataZone, thereby enabling seamless sharing and collaboration among teams. By mechanically sending AWS Glue insights to Amazon DataZone, organizations can simplify the process while simultaneously ensuring data consistency, security, and governance. Standardize and integrate publishing assets within Amazon DataZone. To streamline your team’s access to shared knowledge and insights using Amazon DataZone, mobilize your AWS professionals promptly.
In regards to the Authors
Serves as a Senior Information Architect at Amazon Internet Services, excelling in the fields of data analysis and knowledge management. She crafts innovative, event-driven knowledge frameworks to empower clients in the effective management of information and informed decision-making processes. With her expertise, she empowers clients in navigating their knowledge management transformation to the cloud effectively.
 Serving as a seasoned DevOps Architect at AWS, he leverages his expertise to craft tailored solutions that address the complex needs of clients operating within the automotive sector. He’s passionate about designing robust infrastructures, leveraging automation and data-driven insights to ensure a seamless cloud experience for customers. He prefers to balance his leisure time by pursuing personal interests in studying, acting, language acquisition, and traveling.
Serving as a seasoned DevOps Architect at AWS, he leverages his expertise to craft tailored solutions that address the complex needs of clients operating within the automotive sector. He’s passionate about designing robust infrastructures, leveraging automation and data-driven insights to ensure a seamless cloud experience for customers. He prefers to balance his leisure time by pursuing personal interests in studying, acting, language acquisition, and traveling.
Serving as a Senior Options Architect at Amazon Web Services (AWS), he excels in steering automotive companies through their digital transformation initiatives by leveraging the power of the cloud. With expertise in crafting robust platforms and products, she advises organisations on refining their architecture and making informed decisions that drive successful design outcomes. When she’s not busy with other commitments, she relishes exploring new places, delving into intellectual pursuits, and honing her yoga skills through regular practice.
Are skilled providers of Amazon Web Services? She assists clients in designing data-driven applications within Amazon Web Services (AWS).