
In an period the place knowledge drives innovation and decision-making, organizations are more and more centered on not solely accumulating knowledge however on sustaining its high quality and reliability. Excessive-quality knowledge is crucial for constructing belief in analytics, enhancing the efficiency of machine studying (ML) fashions, and supporting strategic enterprise initiatives.
Through the use of AWS Glue Knowledge High quality, you’ll be able to measure and monitor the standard of your knowledge. It analyzes your knowledge, recommends knowledge high quality guidelines, evaluates knowledge high quality, and gives you with a rating that quantifies the standard of your knowledge. With this, you may make assured enterprise choices. With this launch, AWS Glue Knowledge High quality is now built-in with the lakehouse structure of Amazon SageMaker, Apache Iceberg on normal objective Amazon Easy Storage Service (Amazon S3) buckets, and Amazon S3 Tables. This integration brings collectively serverless knowledge integration, high quality administration, and superior ML capabilities in a unified setting.
This publish explores how you should utilize AWS Glue Knowledge High quality to take care of knowledge high quality of S3 Tables and Apache Iceberg tables on normal objective S3 buckets. We’ll focus on methods for verifying the standard of printed knowledge and the way these built-in applied sciences can be utilized to implement efficient knowledge high quality workflows.
Resolution overview
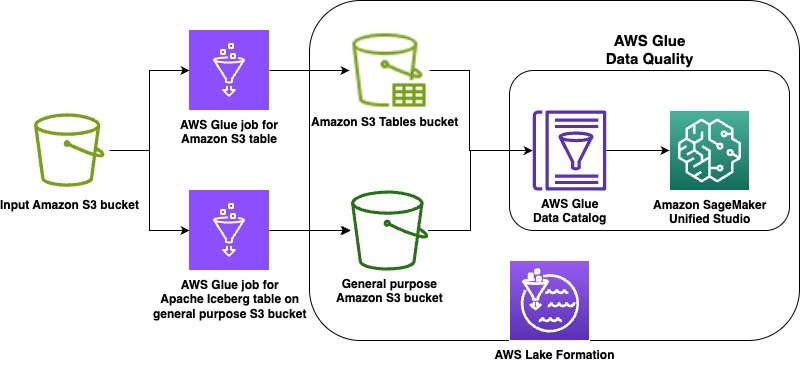
On this launch, we’re supporting the lakehouse structure of Amazon SageMaker, Apache Iceberg on normal objective S3 buckets, and Amazon S3 Tables. As instance use circumstances, we display knowledge high quality on an Apache Iceberg desk saved in a normal objective S3 bucket in addition to on Amazon S3 Tables. The steps will cowl the next:
- Create an Apache Iceberg desk on a normal objective Amazon S3 bucket and an Amazon S3 desk in a desk bucket utilizing two AWS Glue extract, rework, and cargo (ETL) jobs
- Grant acceptable AWS Lake Formation permissions on every desk
- Run knowledge high quality suggestions at relaxation on the Apache Iceberg desk on normal objective S3 bucket
- Run the information high quality guidelines and visualize the ends in Amazon SageMaker Unified Studio
- Run knowledge high quality suggestions at relaxation on the S3 desk
- Run the information high quality guidelines and visualize the ends in SageMaker Unified Studio
The next diagram is the answer structure.
Stipulations
To implement the directions, you should have the next stipulations:
Create S3 tables and Apache Iceberg on normal objective S3 bucket
First, full the next steps to add knowledge and scripts:
- Add the hooked up AWS Glue job scripts to your designated script bucket in S3
- To obtain the New York Metropolis Taxi – Yellow Journey Knowledge dataset for January 2025 (Parquet file), navigate to NYC TLC Journey Report Knowledge, develop 2025, and select Yellow Taxi Journey information beneath January part. A file known as
yellow_tripdata_2025-01.parquetshall be downloaded to your pc. - On the Amazon S3 console, open an enter bucket of your alternative and create a folder known as
nyc_yellow_trip_data. The stack will create aGlueJobRolewith permissions to this bucket. - Add the
yellow_tripdata_2025-01.parquetfile to the folder. - Obtain the CloudFormation stack file. Navigate to the CloudFormation console. Select Create stack. Select Add a template file and choose the CloudFormation template you downloaded. Select Subsequent.
- Enter a singular identify for Stack identify.
- Configure the stack parameters. Default values are supplied within the following desk:
| Parameter | Default worth | Description |
ScriptBucketName | N/A – user-supplied | Title of the referenced Amazon S3 normal objective bucket containing the AWS Glue job scripts |
DatabaseName | iceberg_dq_demo | Title of the AWS Glue Database to be created for the Apache Iceberg desk on normal objective Amazon S3 bucket |
GlueIcebergJobName | create_iceberg_table_on_s3 | The identify of the created AWS Glue job that creates the Apache Iceberg desk on normal objective Amazon S3 bucket |
GlueS3TableJobName | create_s3_table_on_s3_bucket | The identify of the created AWS Glue job that creates the Amazon S3 desk |
S3TableBucketName | dataquality-demo-bucket | Title of the Amazon S3 desk bucket to be created. |
S3TableNamespaceName | s3_table_dq_demo | Title of the Amazon S3 desk bucket namespace to be created |
S3TableTableName | ny_taxi | Title of the Amazon S3 desk to be created by the AWS Glue job |
IcebergTableName | ny_taxi | Title of the Apache Iceberg desk on normal objective Amazon S3 to be created by the AWS Glue job |
IcebergScriptPath | scripts/create_iceberg_table_on_s3.py | The referenced Amazon S3 path to the AWS Glue script file for the Apache Iceberg desk creation job. Confirm the file identify matches the corresponding GlueIcebergJobName |
S3TableScriptPath | scripts/create_s3_table_on_s3_bucket.py | The referenced Amazon S3 path to the AWS Glue script file for the Amazon S3 desk creation job. Confirm the file identify matches the corresponding GlueS3TableJobName |
InputS3Bucket | N/A – user-supplied bucket | Title of the referenced Amazon S3 bucket with which the NY Taxi knowledge was uploaded |
InputS3Path | nyc_yellow_trip_data | The referenced Amazon S3 path with which the NY Taxi knowledge was uploaded |
OutputBucketName | N/A – user-supplied | Title of the created Amazon S3 normal objective bucket for the AWS Glue job for Apache Iceberg desk knowledge |
Full the next steps to configure AWS Identification and Entry Administration (IAM) and Lake Formation permissions:
- Should you haven’t beforehand labored with S3 Tables and analytics providers, navigate to Amazon S3.
- Select Desk buckets.
- Select Allow integration to allow analytics service integrations along with your S3 desk buckets.
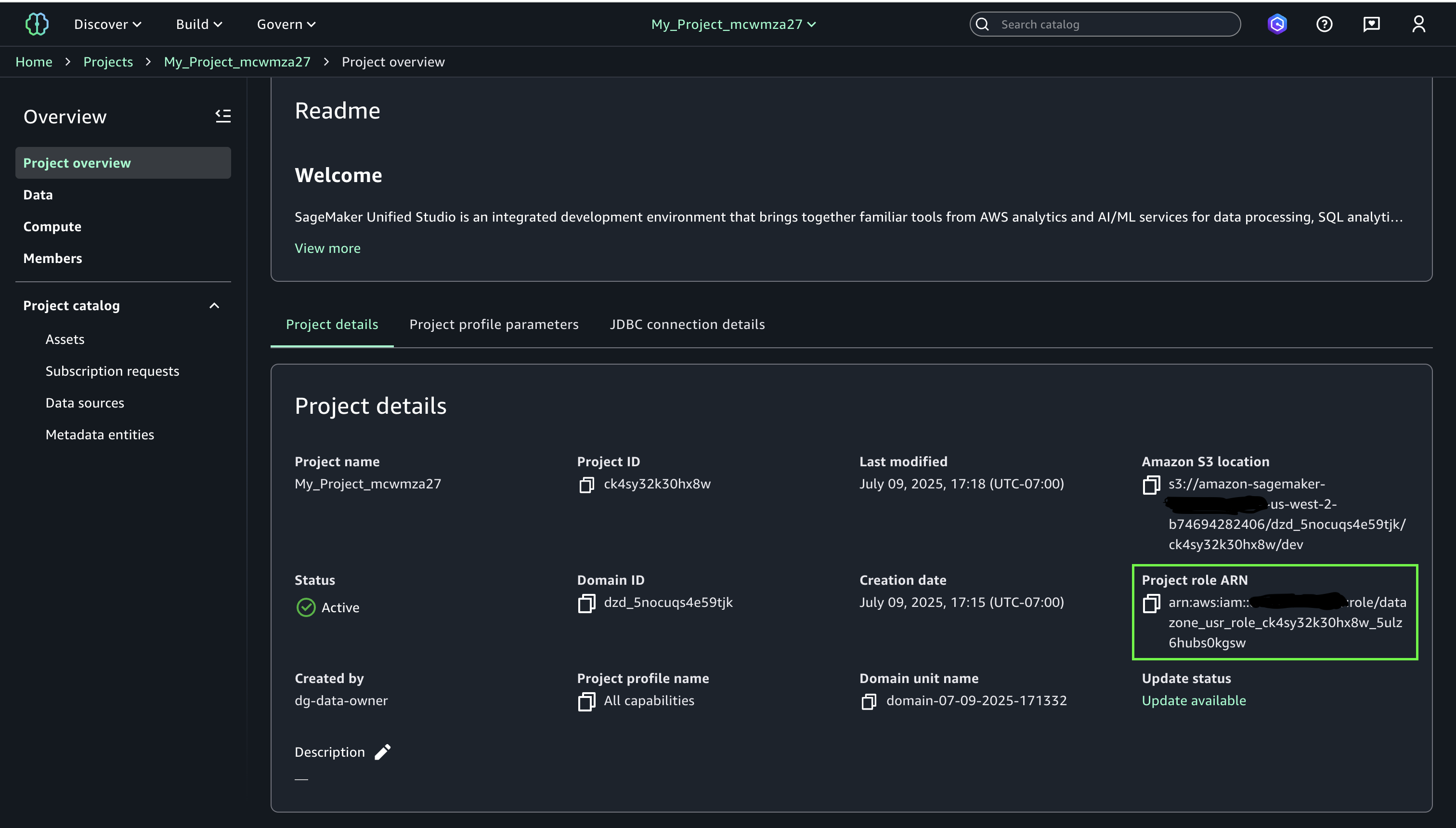
- Navigate to the Assets tab to your AWS CloudFormation stack. Notice the IAM function with the logical ID
GlueJobRoleand the database identify with the logical IDGlueDatabase. Moreover, be aware the identify of the S3 desk bucket with the logical IDS3TableBucketin addition to the namespace identify with the logical IDS3TableBucketNamespace. The S3 desk bucket identify is the portion of the Amazon Useful resource Title (ARN) which follows:arn:aws:s3tables:. The namespace identify is the portion of the namespace ARN which follows:: :bucket/{S3 Desk bucket Title} arn:aws:s3tables:.: :bucket/{S3 Desk bucket Title}|{namespace identify} - Navigate to the Lake Formation console with a Lake Formation knowledge lake administrator.
- Navigate to the Databases tab and choose your
GlueDatabase. Notice the chosen default catalog ought to match your AWS account ID. - Choose the Actions dropdown menu and beneath Permissions, select Grant.
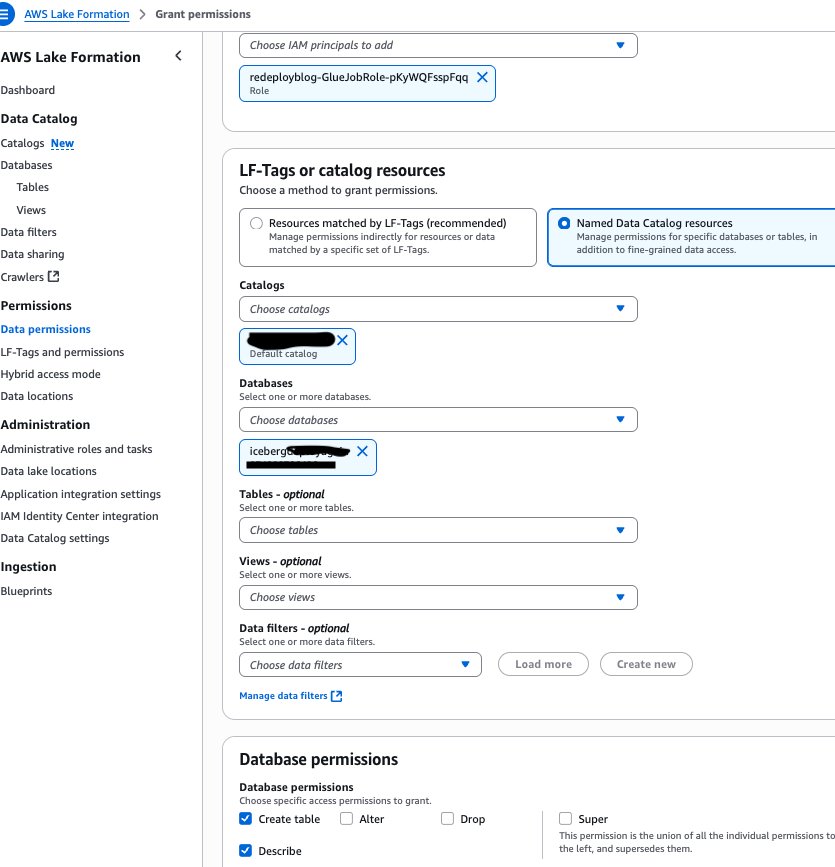
- Grant your
GlueJobRolefrom step 4 the required permissions. Beneath Database permissions, choose Create desk and Describe, as proven within the following screenshot.
Navigate again to the Databases tab in Lake Formation and choose the catalog that matches with the worth of S3TableBucket you famous in step 4 within the format:
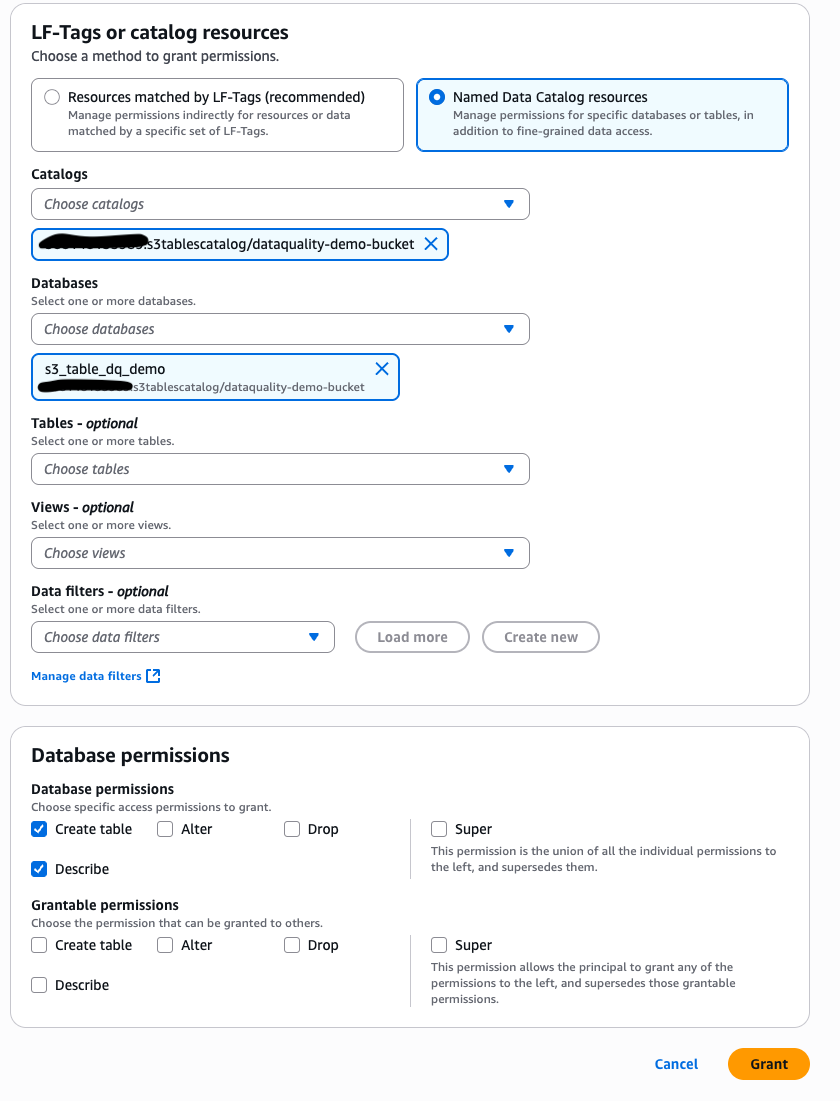
- Choose your namespace identify. From the Actions dropdown menu, beneath Permissions, select Grant.
- Grant your GlueJobRole from step 4 the required permissions Beneath Database permissions, choose Create desk and Describe, as proven within the following screenshot.
To run the roles created within the CloudFormation stack to create the pattern tables and configure Lake Formation permissions for the DataQualityRole, full the next steps:
- Within the Assets tab of your CloudFormation stack, be aware the AWS Glue job names for the logical useful resource IDs:
GlueS3TableJobandGlueIcebergJob. - Navigate to the AWS Glue console and choose ETL jobs. Choose your
GlueIcebergJobfrom step 11 and select Run job. Choose yourGlueS3TableJoband select Run job. - To confirm the profitable creation of your Apache Iceberg desk on normal objective S3 bucket within the database, navigate to Lake Formation along with your Lake Formation knowledge lake administrator permissions. Beneath Databases, choose your
GlueDatabase. The chosen default catalog ought to match your AWS account ID. - On the dropdown menu, select View after which Tables. You need to see a brand new tab with the desk identify you specified for
IcebergTableName. You’ve verified the desk creation. - Choose this desk and grant your DataQualityRole (
-DataQualityRole- - To confirm the S3 desk within the S3 desk bucket, navigate to Databases within the Lake Formation console along with your Lake Formation knowledge lake administrator permissions. Be sure the chosen catalog is your S3 desk bucket catalog:
:s3tablescatalog/ - Choose your S3 desk namespace and select the dropdown menu View.
- Select Tables and it’s best to see a brand new tab with the desk identify you specified for
S3TableTableName. You’ve verified the desk creation. - Select the hyperlink for the desk and beneath Actions, select Grant. Grant your
DataQualityRolethe required Lake Formation permissions. Select Choose, Describe from Desk permissions for the S3 desk. - Within the Lake Formation console along with your Lake Formation knowledge lake administrator permissions, on the Administration tab, select Knowledge lake places .
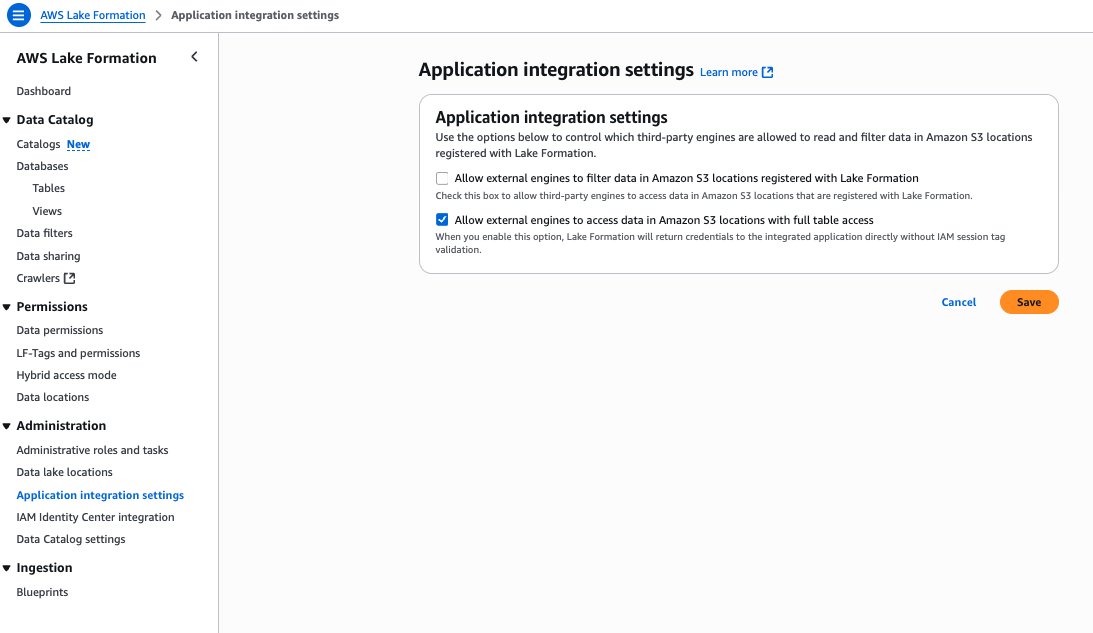
- Select Register location. Enter your
OutputBucketNamebecause the Amazon S3 path. Enter theLakeFormationRolefrom the stack sources because the IAM function. Beneath Permission mode, select Lake Formation. - On the Lake Formation console beneath Utility integration settings, choose Permit exterior engines to entry knowledge in Amazon S3 places with full desk entry, as proven within the following screenshot.
Generate suggestions for Apache Iceberg desk on normal objective S3 bucket managed by Lake Formation
On this part, we present find out how to generate knowledge high quality guidelines utilizing the information high quality rule suggestions characteristic of AWS Glue Knowledge High quality to your Apache Iceberg desk on a normal objective S3 bucket. Observe these steps:
- Navigate to the AWS Glue console. Beneath Knowledge Catalog, select Databases. Select the
GlueDatabase. - Beneath Tables, choose your
IcebergTableName. On the Knowledge high quality tab, select Run historical past. - Beneath Advice runs, select Advocate guidelines.
- Use the
DataQualityRole(-DataQualityRole-
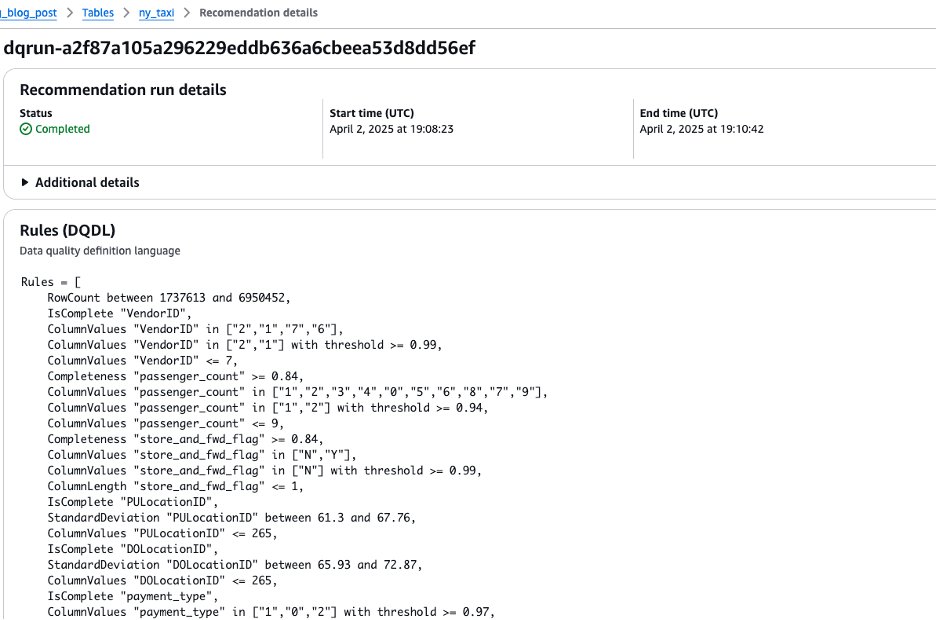
Run knowledge high quality guidelines for Apache Iceberg desk on normal objective S3 bucket managed by Lake Formation
On this part, we present find out how to create a knowledge high quality ruleset with the beneficial guidelines. After creating the ruleset, we run the information high quality guidelines. Observe these steps:
- Copy the ensuing guidelines out of your suggestion run by deciding on the dq-run ID and selecting Copy.
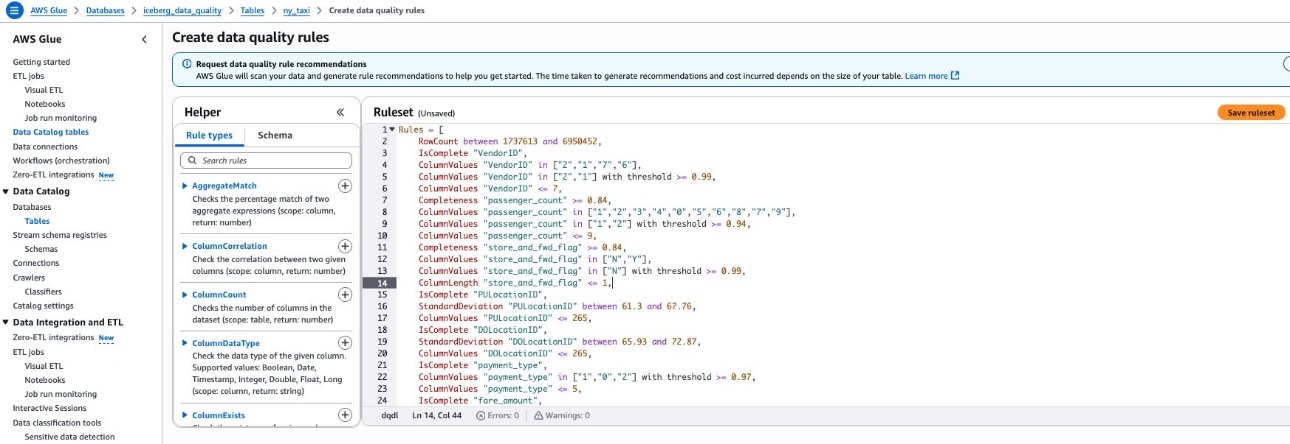
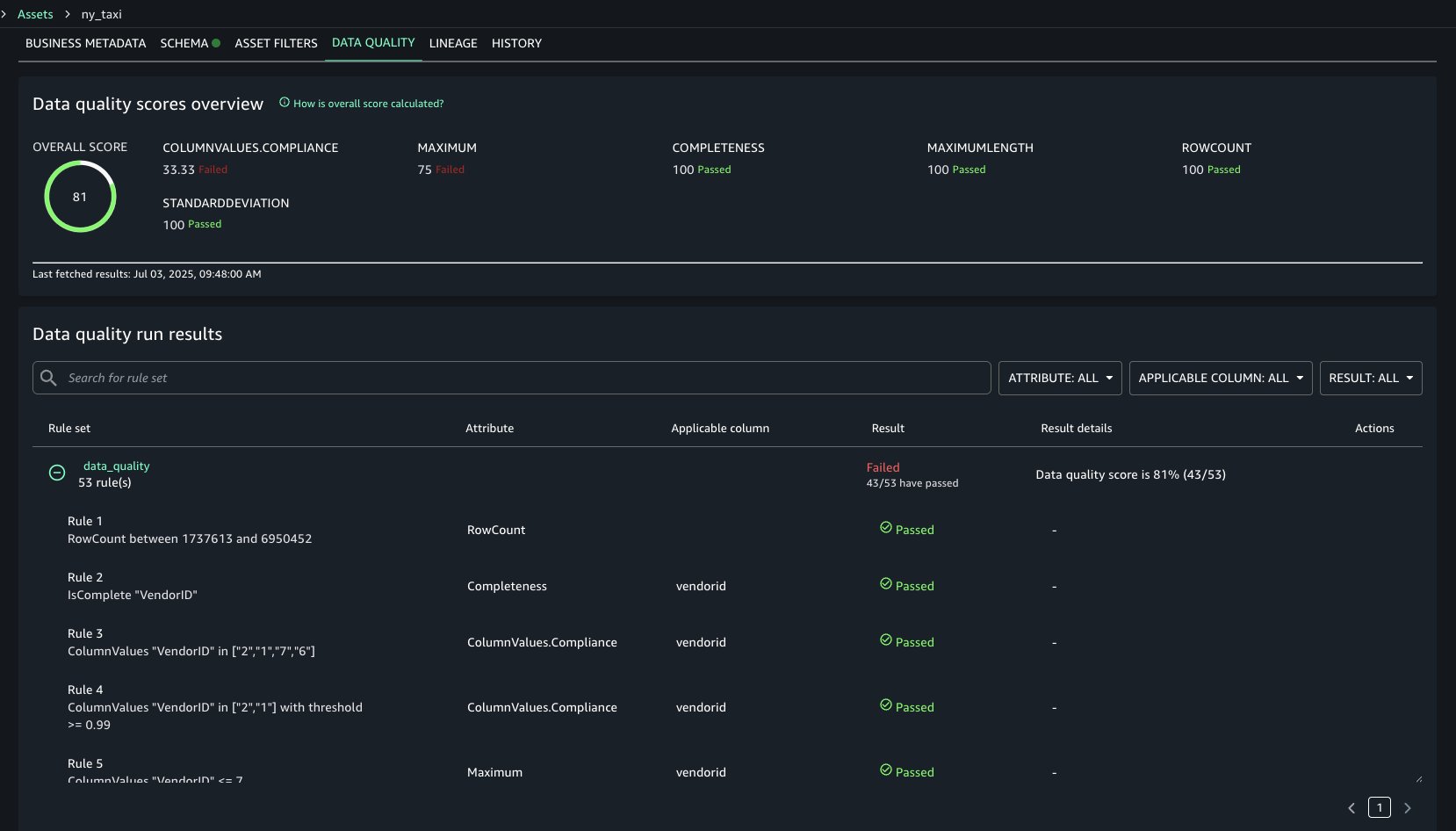
- Navigate again to the desk beneath the Knowledge high quality tab and select Create knowledge high quality guidelines. Paste the ruleset from step 1 right here. Select Save ruleset, as proven within the following screenshot.
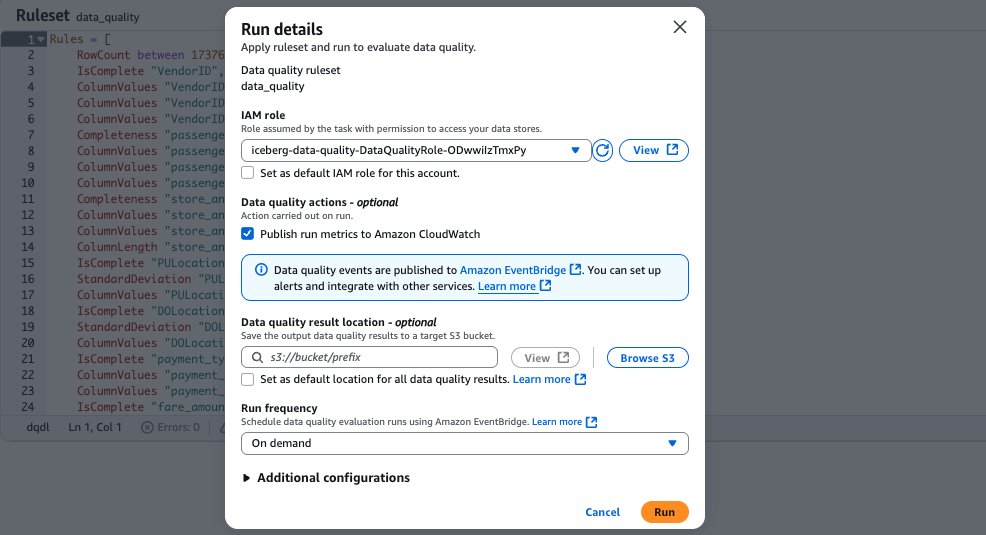
- After saving your ruleset, navigate again to the Knowledge High quality tab to your Apache Iceberg desk on the overall objective S3 bucket. Choose the ruleset you created. To run the information high quality analysis run on the ruleset utilizing your knowledge high quality function, select Run, as proven within the following screenshot.
Generate suggestions for the S3 desk on the S3 desk bucket
On this part, we present find out how to use the AWS Command Line Interface (AWS CLI) to generate suggestions to your S3 desk on the S3 desk bucket. This may even create a knowledge high quality ruleset for the S3 desk. Observe these steps:
- Fill in your S3 desk
namespace identify, S3 deskdesk identify,Catalog ID, andKnowledge High quality function ARNwithin the following JSON file and put it aside domestically:

 Brody Pearman is a Senior Cloud Help Engineer at Amazon Internet Companies (AWS). He’s obsessed with serving to clients use AWS Glue ETL to remodel and create their knowledge lakes on AWS whereas sustaining excessive knowledge high quality. In his free time, he enjoys watching soccer together with his mates and strolling his canine.
Brody Pearman is a Senior Cloud Help Engineer at Amazon Internet Companies (AWS). He’s obsessed with serving to clients use AWS Glue ETL to remodel and create their knowledge lakes on AWS whereas sustaining excessive knowledge high quality. In his free time, he enjoys watching soccer together with his mates and strolling his canine. Shiv Narayanan is a Technical Product Supervisor for AWS Glue’s knowledge administration capabilities like knowledge high quality, delicate knowledge detection and streaming capabilities. Shiv has over 20 years of information administration expertise in consulting, enterprise growth and product administration.
Shiv Narayanan is a Technical Product Supervisor for AWS Glue’s knowledge administration capabilities like knowledge high quality, delicate knowledge detection and streaming capabilities. Shiv has over 20 years of information administration expertise in consulting, enterprise growth and product administration. Shriya Vanvari is a Software program Developer Engineer in AWS Glue. She is obsessed with studying find out how to construct environment friendly and scalable programs to supply higher expertise for purchasers. Exterior of labor, she enjoys studying and chasing sunsets.
Shriya Vanvari is a Software program Developer Engineer in AWS Glue. She is obsessed with studying find out how to construct environment friendly and scalable programs to supply higher expertise for purchasers. Exterior of labor, she enjoys studying and chasing sunsets. Narayani Ambashta is an Analytics Specialist Options Architect at AWS, specializing in the automotive and manufacturing sector, the place she guides strategic clients in growing trendy knowledge and AI methods. With over 15 years of cross-industry expertise, she focuses on massive knowledge structure, real-time analytics, and AI/ML applied sciences, serving to organizations implement trendy knowledge architectures. Her experience spans throughout lakehouse structure, generative AI, and IoT platforms, enabling clients to drive digital transformation initiatives. When not architecting trendy options, she enjoys staying lively by sports activities and yoga.
Narayani Ambashta is an Analytics Specialist Options Architect at AWS, specializing in the automotive and manufacturing sector, the place she guides strategic clients in growing trendy knowledge and AI methods. With over 15 years of cross-industry expertise, she focuses on massive knowledge structure, real-time analytics, and AI/ML applied sciences, serving to organizations implement trendy knowledge architectures. Her experience spans throughout lakehouse structure, generative AI, and IoT platforms, enabling clients to drive digital transformation initiatives. When not architecting trendy options, she enjoys staying lively by sports activities and yoga.{kind=link}