{kind=link}


Two cobots utilizing autonomous analysis rollouts from finetuned LBMs to carry out long-horizon behaviors, like putting in a motorbike rotor. | Supply: Toyota Analysis Institute
Toyota Analysis Institute (TRI) this week launched the outcomes of its examine on Massive Habits Fashions (LBMs) that can be utilized to coach general-purpose robots. The examine confirmed a single LBM can be taught a whole bunch of duties and use prior data to amass new abilities with 80% much less coaching knowledge.
LBMs are pretrained on giant, various manipulation datasets. Regardless of their rising reputation, the robotics group is aware of surprisingly little in regards to the nuances of what LBMs truly provide. TRI’s work goals to make clear current progress in algorithm and dataset design with this examine.
In all, TRI mentioned its findings largely assist the current surge in reputation of LBM-style robotic basis fashions, including to proof that large-scale pretraining on various robotic knowledge is a viable path in the direction of extra succesful robots, although with a number of factors of warning.
Normal-purpose robots promise a future the place family robots can present on a regular basis help. Nonetheless, we’re not on the level the place any robotic can sort out common family duties. LBMs, or embodied AI programs that soak up robotic sensor knowledge and output actions, may change that, TRI mentioned.
In 2024, TRI gained an RBR50 Robotics Innovation Award for its work constructing LBMs for quick robotic instructing.
An summary of TRI’s findings
TRI educated a collection of diffusion-based LBMs on nearly 1,700 hours of robotic knowledge and performed 1,800 real-world analysis rollouts and over 47,000 simulation rollouts to scrupulously examine their capabilities. It discovered that LBMs:
- Ship constant efficiency enhancements relative to from-scratch insurance policies
- Allow new duties to be realized with 3-5× much less knowledge in difficult settings requiring robustness to a wide range of environmental components
- Enhance steadily as pretraining knowledge will increase
Even with just some hundred various hours of knowledge, and only some hundred demos per conduct, efficiency jumped meaningfully, TRI mentioned. Pretraining supplies constant efficiency uplifts at sooner than anticipated scales. There’s not but an web value of robotic knowledge, however advantages seem far earlier than that scale — a promising signal for enabling virtuous cycles of knowledge acquisition and bootstrapped efficiency, TRI claimed.
TRI’s analysis suite contains a number of novel and extremely difficult long-horizon real-world duties; finetuned and evaluated on this setting, LBM pretraining improves efficiency regardless of these behaviors being extremely distinct from the pretraining duties.
Contained in the structure and knowledge of TRI’s LBMs
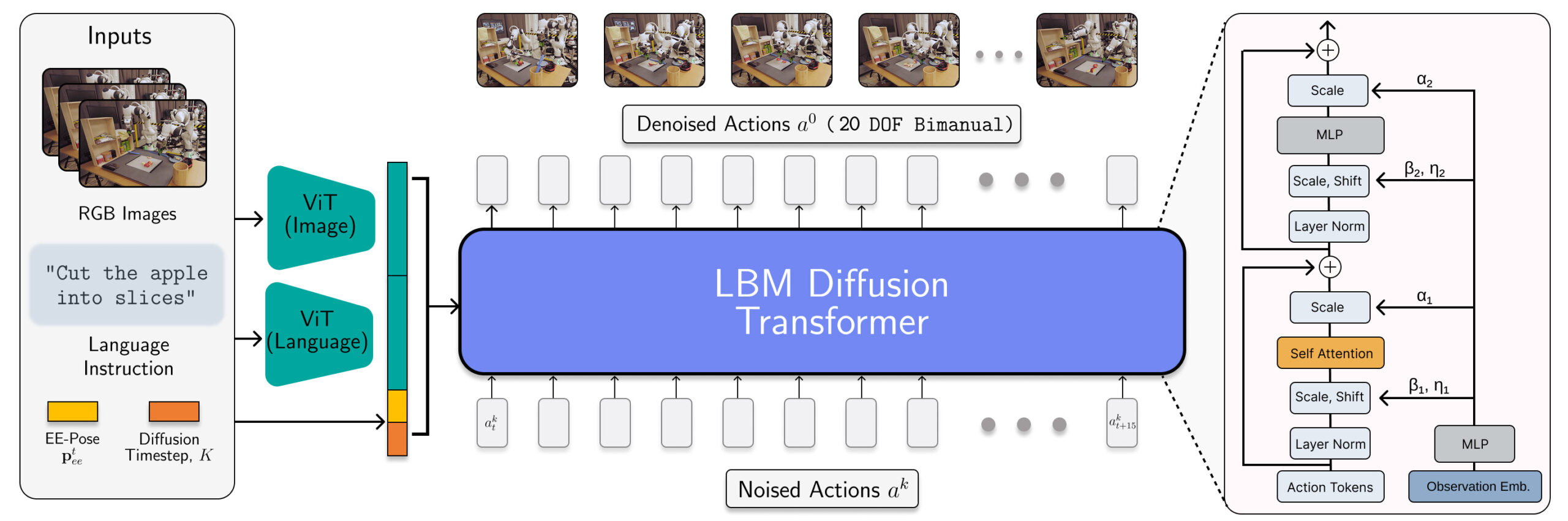
The LBM structure is instantiated as a diffusion transformer which predicts robotic actions. | Supply: Toyota Analysis Institute
TRI’s LBMs are scaled multitask diffusion insurance policies with multimodal ViT vision-language encoders and a transformer denoising head conditioned on encoded observations by way of AdaLN. These fashions eat wrist and scene cameras, robotic proprioception, and language prompts and predict 16 timesteps (1.6 second) motion chunks.
The researchers educated the LBMs on a mix of 468 hours of internally collected bimanual robotic teleoperation knowledge, 45 hours of simulation-collected teleoperation knowledge, 32 hours of Common Manipulation Interface (UMI) knowledge, and roughly 1,150 hours of web knowledge curated from the Open X-Embodiment dataset.
Whereas the proportion of simulation knowledge is small, its inclusion in TRI’s pretraining combination ensures that it may consider the identical LBM checkpoint in each sim and actual.
TRI’s analysis strategies
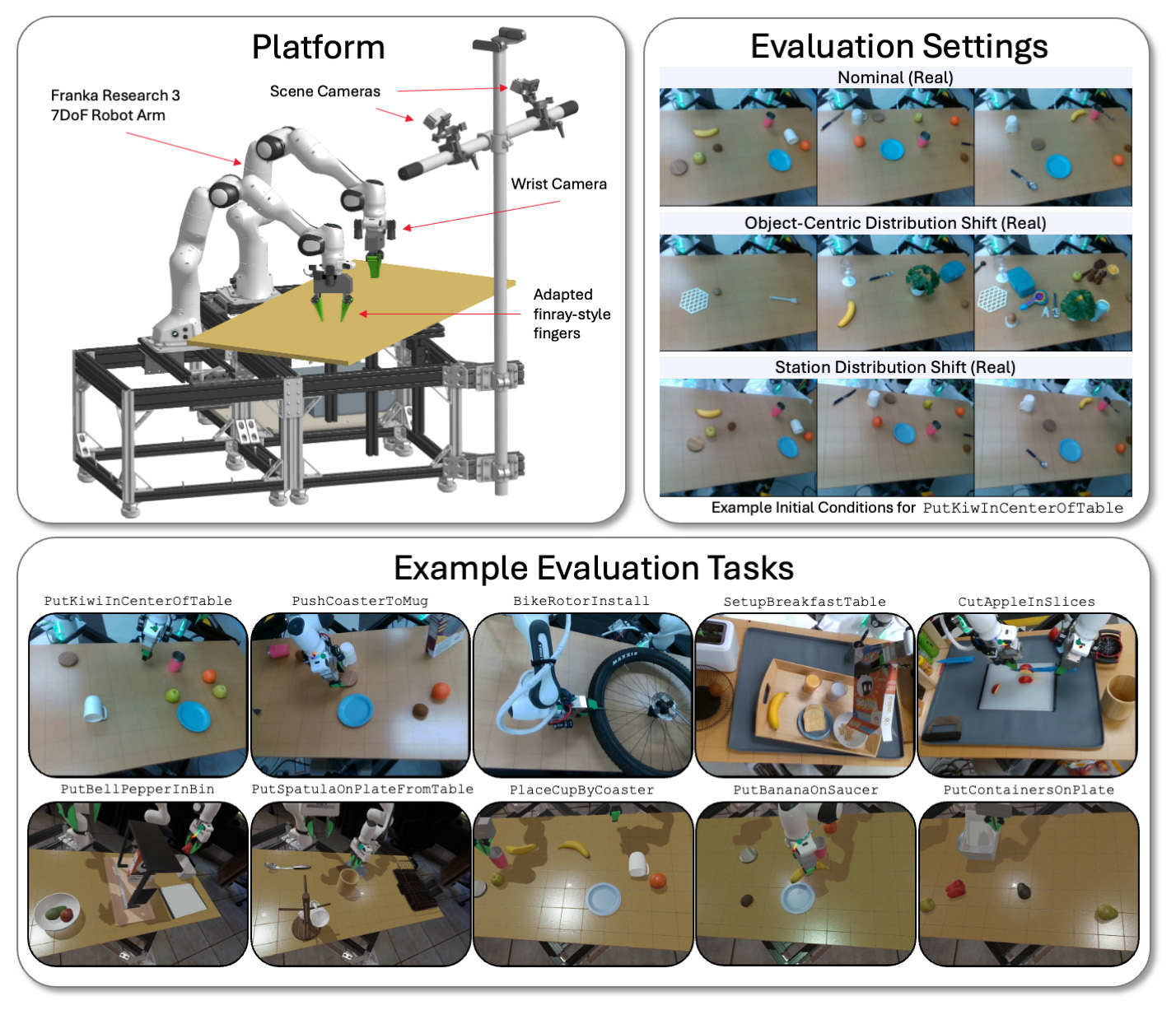
TRI evaluates its LBM fashions on a bimanual platform throughout a wide range of duties and environmental circumstances in each simulation and the actual world. | Supply: Toyota Analysis Institute
TRI evaluates its LBMs on bodily and Drake-simulated bimanual stations using Franka Panda FR3 arms and as much as six cameras — as much as two on every wrist, and two static scene cameras.
It evaluates the fashions on each seen duties (current within the pretraining knowledge) and unseen duties (which TRI makes use of to fine-tune its pretrained mannequin). TRI’s analysis suite consists of 16 simulated seen-during-pretraining duties, 3 real-world seen-during-pretraining duties, 5 beforehand unseen long-horizon simulated duties, and 5 complicated beforehand unseen long-horizon real-world duties.
Every mannequin was examined by way of 50 rollouts for every real-world activity and 200 rollouts for every simulation activity. This permits a excessive stage of statistical rigour in our evaluation, with the pretrained fashions evaluated on 4,200 rollouts throughout 29 duties.
TRI mentioned it rigorously controls preliminary circumstances to be constant in each the actual world and simulation. It additionally conducts blind A/B-style testing in the actual world with statistical significance computed by way of a sequential speculation testing framework.
Most of the results the researchers noticed have been solely measurable with larger-than-standard pattern sizes and cautious statistical testing that’s non-standard for empirical robotics. It’s straightforward for noise because of experimental variation to dwarf the consequences being measured, and plenty of robotics papers could also be measuring statistical noise because of inadequate statistical energy.
TRI’s high takeaways from the analysis
One of many staff’s most important takeaways is that finetuned efficiency easily improves with rising pretraining knowledge. On the knowledge scales we examined, TRI noticed no proof of efficiency discontinuities or sharp inflection factors; AI scaling seems alive and effectively in robotics.
TRI did expertise blended outcomes with non-finetuned pretrained LBMs, nevertheless. Encouragingly, it discovered {that a} single community is ready to be taught many duties concurrently, however it doesn’t observe constant outperformance from scratch single-task coaching with out fine-tuning. TRI expects that is partially as a result of language steerability of its mannequin.
In inner testing, TRI mentioned it has seen some promising early indicators that bigger VLA prototypes overcome a few of this problem, however extra work is required to scrupulously look at this impact in higher-language-capacity fashions.
On the subject of factors of warning, TRI mentioned delicate design decisions like knowledge normalization can have giant results on efficiency, usually dominating architectural or algorithmic modifications. It’s essential that these design decisions are rigorously remoted to keep away from conflating the supply of efficiency modifications.