

{kind=link}
Enterprises are adopting Apache Iceberg desk format for its multitude of advantages. The change information seize (CDC), ACID compliance, and schema evolution options cater to representing large datasets that obtain new information at a quick tempo. In an earlier weblog publish, we mentioned the right way to implement fine-grained entry management in Amazon EMR Serverless utilizing AWS Lake Formation for reads. Lake Formation helps you centrally handle and scale fine-grained information entry permissions and share information with confidence inside and out of doors your group.
On this publish, we exhibit the right way to use Lake Formation for learn entry whereas persevering with to make use of AWS Id and Entry Administration (IAM) policy-based permissions for write workloads that replace the schema and upsert (insert and replace mixed) information information into the Iceberg tables. The bimodal permissions are wanted to assist current information pipelines that use solely IAM and Amazon Easy Storage Service (Amazon) S3 bucket policy-based permissions and to assist desk operations that aren’t but out there within the analytics engines. The 2-way permission is achieved by registering the Amazon S3 information location of the Iceberg desk with Lake Formation in hybrid entry mode. Lake Formation hybrid entry mode lets you onboard new customers with Lake Formation permissions to entry AWS Glue Information Catalog tables with minimal interruptions to current IAM policy-based customers. With this resolution, organizations can use the Lake Formation permissions to scale the entry of their current Iceberg tables in Amazon S3 to new readers. You may prolong the methodology to different open desk codecs, equivalent to Linux Basis Delta Lake tables and Apache Hudi tables.
Key use circumstances for Lake Formation hybrid entry mode
Lake Formation hybrid entry mode is helpful within the following use circumstances:
- Avoiding information replication – Hybrid entry mode helps onboard new customers with Lake Formation permissions on current Information Catalog tables. For instance, you possibly can allow a subset of information entry (coarse vs. fine-grained entry) for numerous person personas, equivalent to information scientists and information analysts, with out making a number of copies of the information. This additionally helps preserve a single supply of fact for manufacturing and enterprise insights.
- Minimal interruption to current IAM policy-based person entry – With hybrid entry mode, you possibly can add new Lake Formation managed customers with minimal disruptions to your current IAM and Information Catalog policy-based person entry. Each entry strategies can coexist for a similar catalog desk, however every person can have just one mode of permissions.
- Transactional desk writes – Sure write operations like insert, replace, and delete are usually not supported by Amazon EMR for Lake Formation managed Iceberg tables. Check with Issues and limitations for added particulars. Though you might use Lake Formation permissions for Iceberg desk learn operations, you might handle the write operations because the desk house owners with IAM policy-based entry.
Resolution overview
An instance Enterprise Corp has a lot of Iceberg tables primarily based on Amazon S3. They’re at the moment managing the Iceberg tables manually with IAM coverage, Information Catalog useful resource coverage, and S3 bucket policy-based entry of their group. They need to share their transactional information of Iceberg tables throughout totally different groups, equivalent to information analysts and information scientists, asking for learn entry throughout just a few traces of enterprise. Whereas sustaining the possession of the desk’s updates to their single group, they need to present restricted learn entry to sure columns of their tables. That is achieved by utilizing the hybrid entry mode function of Lake Formation.
On this publish, we illustrate the situation with a knowledge engineer group and a brand new information analyst group. The information engineering group owns the extract, remodel, and cargo (ETL) utility that may course of the uncooked information to create and preserve the Iceberg tables. The information analyst group will question the tables to collect enterprise insights from these tables. The ETL utility will use IAM role-based entry to the Iceberg desk, and the information analyst will get Lake Formation permissions to question the identical tables.
The answer might be visually represented within the following diagram.

For ease of illustration, we use just one AWS account on this publish. Enterprise use circumstances usually have a number of accounts or cross-account entry necessities. The setup of the Iceberg tables, Lake Formation permissions, and IAM primarily based permissions are related for a number of and cross-account situations.
The high-level steps concerned within the permissions setup are as follows:
- Make it possible for
IAMAllowedPrincipalshasTremendousentry to the database and tables in Lake Formation.IAMAllowedPrincipalsis a digital group that represents any IAM principal permissions.Tremendousentry to this digital group is required to guarantee that IAM policy-based permissions to any IAM principal continues to work. - Register the information location with Lake Formation in hybrid entry mode.
- Grant DATA LOCATION permission to the IAM position that manages the desk with IAM policy-based permissions. With out the DATA LOCATION permission, write workloads will fail. Check the entry to the desk by writing new information to the desk because the IAM position.
- Add SELECT desk permissions to the
Information-Analystposition in Lake Formation. - Decide-in the
Information-Analystto the Iceberg desk, making the Lake Formation permissions efficient for the analyst. - Check entry to the desk because the
Information-Analystby working SELECT queries in Athena. - Check the desk write operations by including new information to the desk as
ETL-application-roleutilizing EMR Serverless. - Learn the newest replace, once more, as
Information-Analyst.
Stipulations
It’s best to have the next stipulations:
- An AWS account with a Lake Formation administrator configured. Check with Information lake administrator permissions and Arrange AWS Lake Formation. You may also consult with Simplify information entry in your enterprise utilizing Amazon SageMaker Lakehouse for the Lake Formation admin setup in your AWS account. For ease of demonstration, we’ve got used an IAM admin position added as a Lake Formation administrator.
- An S3 bucket to host the pattern Iceberg desk information and metadata.
- An IAM position to register your Iceberg desk Amazon S3 location with Lake Formation. Observe the coverage and belief coverage particulars for a user-defined position creation from Necessities for roles used to register areas.
- An IAM position named
ETL-application-role, which would be the runtime position to execute jobs in EMR Serverless. The minimal coverage required is proven within the following code snippet. Change the Amazon S3 information location of the Iceberg desk, database title, and AWS Key Administration Service (AWS KMS) key ID with your personal. For added particulars on the position setup, consult with Job runtime roles for Amazon EMR Serverless. This position can insert, replace, and delete information within the desk.Add the next belief coverage to the position:
- An IAM position referred to as
Information-Analyst, to characterize the information analyst entry. Use the next coverage to create the position. Additionally connect the AWS managed coveragearn:aws:iam::aws:coverage/AmazonAthenaFullAccessto the position, to permit querying the Iceberg desk utilizing Amazon Athena. Check with Information engineer permissions for added particulars about this position.Add the next belief coverage to the position:
Create the Iceberg desk
Full the next steps to create the Iceberg desk:
- Sign up to the Lake Formation console because the admin position.
- Within the navigation pane underneath Information Catalog, select Databases.
- From the Create dropdown menu, create a database named
iceberg_db. You may go away the Amazon S3 location property empty for the database. - On the Athena console, run the next supplied queries. The queries carry out the next operations:
- Create a desk referred to as
customer_csv, pointing to thebuyerdataset within the public S3 bucket. - Create an Iceberg desk referred to as
customer_iceberg, pointing to your S3 bucket location that may host the Iceberg desk information and metadata. - Insert information from the CSV desk to the Iceberg desk.
- Create a desk referred to as
Arrange the Iceberg desk as a hybrid entry mode useful resource
Full the next steps to arrange the Iceberg desk’s Amazon S3 information location as hybrid entry mode in Lake Formation:
- Register your desk location with Lake Formation:
- Sign up to the Lake Formation console as information lake administrator.
- Within the navigation pane, select Information lake Places.
- For Amazon S3 path, present the S3 prefix of your Iceberg desk location that holds each the information and metadata of the desk.
- For IAM position, present the user-defined position that has permissions to your Iceberg desk’s Amazon S3 location and that you just created based on the stipulations. For extra particulars, consult with Registering an Amazon S3 location.
- For Permission mode, choose Hybrid entry mode.
- Select Register location to register your Iceberg desk Amazon S3 location with Lake Formation.

- Add information location permission to
ETL-application-role:- Within the navigation pane, select Information areas.
- For IAM customers and roles, select
ETL-application-role. - For Storage location, present the S3 prefix of your Iceberg desk.
- Select Grant.
Information location permission is required for write operations to the Iceberg desk location provided that the Iceberg desk’s S3 prefix is a toddler location of the database’s Amazon S3 location property.

- Grant Tremendous entry on the Iceberg database and desk to
IAMAllowedPrincipals:- Within the navigation pane, select Information permissions.
- Select IAM customers and roles and select
IAMAllowedPrincipals. - For LF-Tags or catalog sources, select Named Information Catalog sources.
- Beneath Databases, choose the title of your Iceberg desk’s database.
- Beneath Database permissions, choose Tremendous.
- Select Grant.


- Repeat the previous steps and for Tables – optionally available, select the Iceberg desk.
- Beneath Desk permissions, choose Tremendous.
- Select Grant.

- Add database and desk permissions to the
Information-Analystposition:- Repeat the steps in Step 3 to grant permissions for the
Information-Analystposition, as soon as for database-level permission and as soon as for table-level permission. - Choose Describe permissions for the Iceberg database.
- Choose Choose permissions for the Iceberg desk.
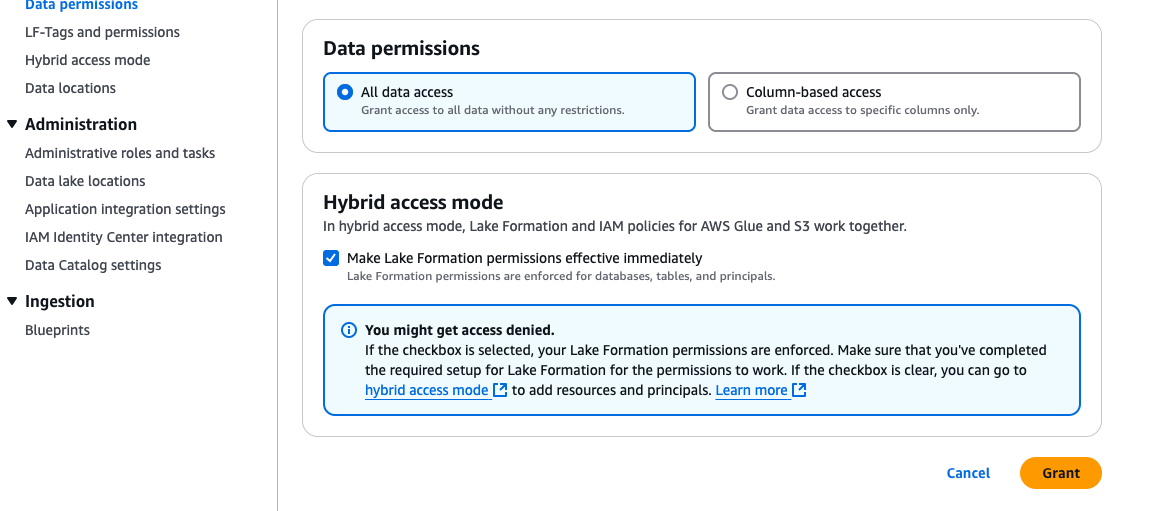
- Beneath Hybrid entry mode, choose Make Lake Formation permissions efficient instantly.
- Select Grant.
- Repeat the steps in Step 3 to grant permissions for the
The next screenshots present the database permissions for Information-Analyst.


The next screenshots present the desk permissions for Information-Analyst.
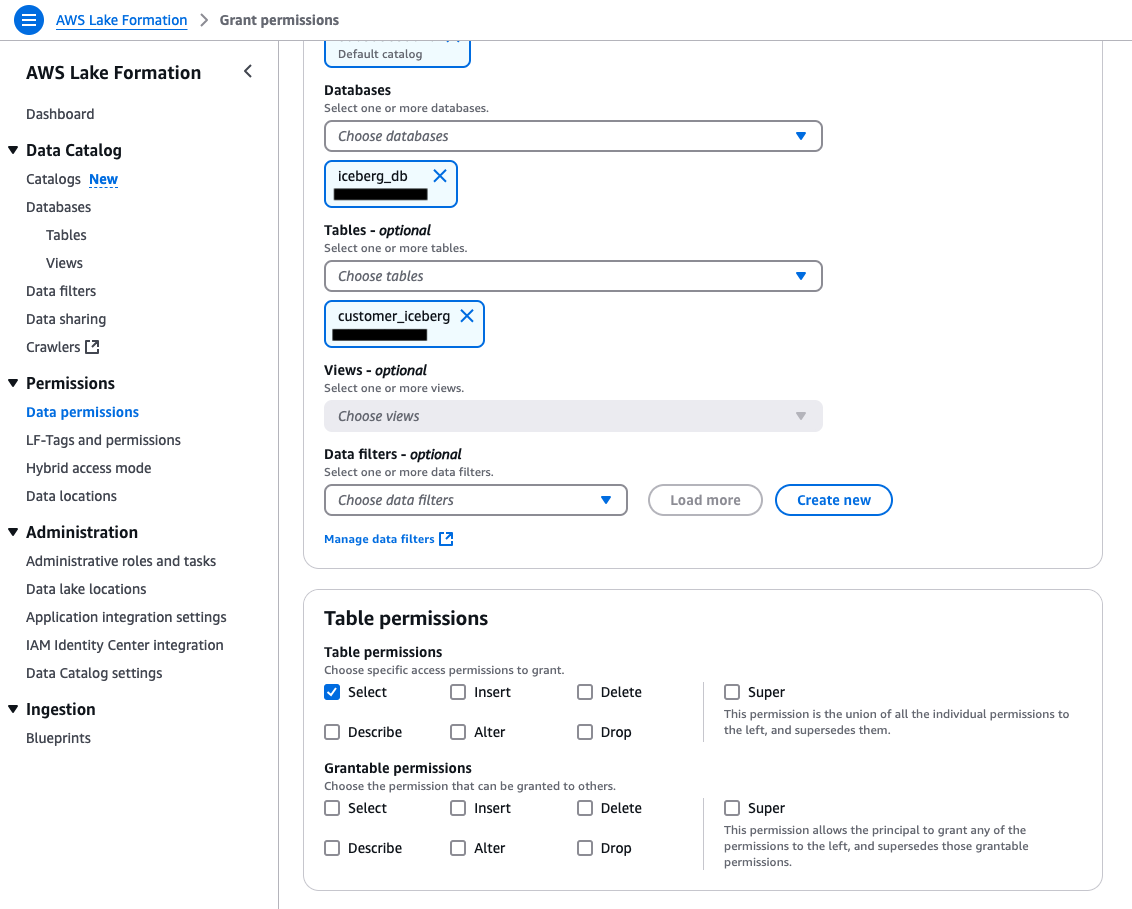
- Confirm Lake Formation permissions on the Iceberg desk and database to each
Information-AnalystandIAMAllowedPrincipals:- Within the navigation pane, select Information permissions.
- Filter by
Desk= customer_iceberg.
It’s best to seeIAMAllowedPrincipalswith All permission and Information-Analyst with Choose permission.
- Equally, confirm permissions for the database by filtering
database=iceberg_db.
It’s best to see IAMAllowedPrincipals with All permission and Information-Analyst with Describe permission.

- Confirm Lake Formation opt-in for
Information-Analyst:- Within the navigation pane, select Hybrid entry mode.
It’s best to see Information-Analyst opted-in for each database and desk stage permissions.

Question the desk because the Information-Analyst position in Athena
While you’re logged in to the AWS Administration Console as admin, arrange the Athena question outcomes bucket:
- On the console navigation bar, select your person title.
- Select Change position to change to the
Information-Analystposition.
- Enter your account ID, IAM position title (
Information-Analyst), and select Change Function.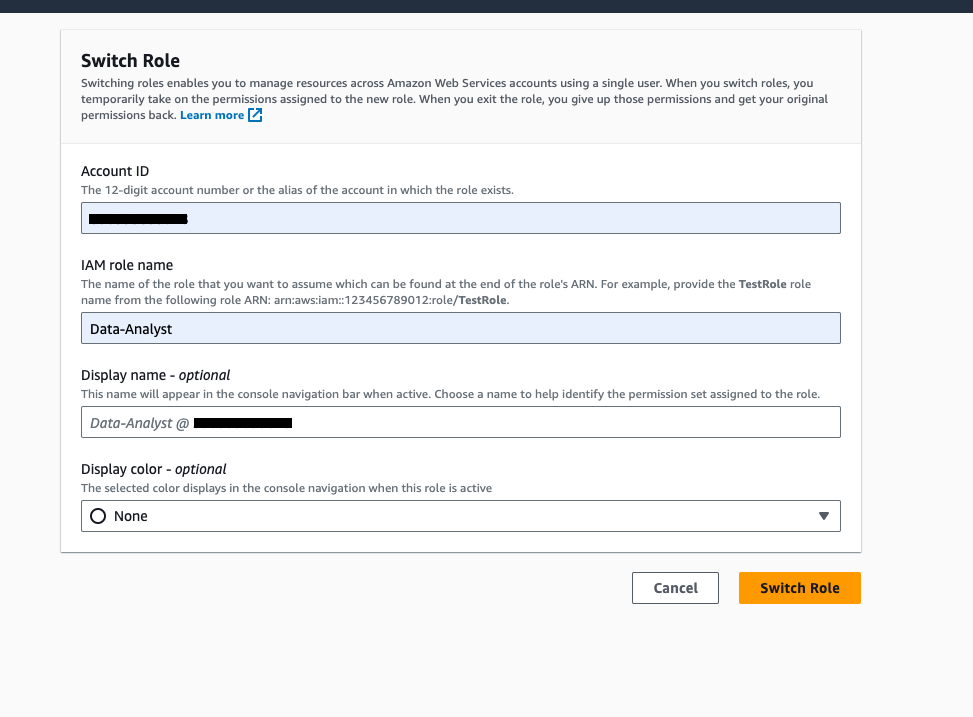
- Now that you just’re logged in because the
Information-Analystposition, open the Athena console and arrange the Athena question outcomes bucket. - Run the next question to learn the Iceberg desk. This verifies the Choose permission granted to the
Information-Analystposition in Lake Formation.

Upsert information as ETL-application-role utilizing Amazon EMR
To upsert information to Lake Formation enabled Iceberg tables, we are going to use Amazon EMR Studio, which is an built-in improvement setting (IDE) that makes it simple for information scientists and information engineers to develop, visualize, and debug information engineering and information science purposes written in R, Python, Scala, and PySpark. EMR Studio can be our web-based IDE to run our notebooks, and we are going to use EMR Serverless because the compute engine. EMR Serverless is a deployment choice for Amazon EMR that gives a serverless runtime setting. For the steps to run an interactive pocket book, see Submit a job run or interactive workload.
- Signal out of the AWS console as
Information-Analystand log again or change the person to admin. - On the Amazon EMR console, select EMR Serverless within the navigation pane.
- Select Get began.
- For first-time customers, Amazon EMR permits creation of an EMR Studio and not using a digital personal cloud (VPC). Create an EMR Serverless utility as follows:
- Present a reputation for the EMR Serverless utility, equivalent to
DemoHybridAccess. - Beneath Software setup, select Use default settings for interactive workloads.
- Select Create and begin utility.
- Present a reputation for the EMR Serverless utility, equivalent to


The following step is to create an EMR Studio.
- On the Amazon EMR console, select Studio underneath EMR Studio within the navigation pane.
- Select Create Studio.
- Choose Interactive workloads.
- It’s best to see a default pre-populated part. Maintain these default settings and select Create Studio and launch Workspace.

- After the workspace is launched, connect the EMR Serverless utility created earlier and choose
ETL-application-rolebecause the runtime position underneath Compute.

- Obtain the pocket book Iceberg-hybridaccess_final.ipynb and add it to EMR Studio workspace.
This pocket book configures the metastore properties to work with Iceberg tables. (For extra particulars, see Utilizing Apache Iceberg with EMR Serverless.) Then it performs insert, replace, and delete operations within the Iceberg desk. It additionally verifies if the operations are profitable by studying the newly added information.
- Choose PySpark because the kernel and execute every cell within the pocket book by selecting the run icon.
Check with Submit a job run or interactive workload for additional particulars about the right way to run an interactive pocket book.
The next screenshot reveals that the Iceberg desk insert operation accomplished efficiently.

The next screenshot illustrates working the replace assertion on the Iceberg desk within the pocket book.

The next screenshot reveals that the Iceberg desk delete operation accomplished efficiently.

Question the desk once more as Information-Analyst utilizing Athena
Full the next steps:
- Change your position to
Information-Analyston the AWS console. - Run the next question on the Iceberg desk and skim the row that was up to date by the EMR cluster:
The next screenshot reveals the outcomes. As we are able to see, ‘c_first_name’ column is up to date with new worth.

Clear up
To keep away from incurring prices, clear up the sources you used for this publish:
- Revoke the Lake Formation permissions and hybrid entry mode opt-in granted to the
Information-Analystposition andIAMAllowedPrincipals. - Revoke the registration of the S3 bucket to Lake Formation.
- Delete the Athena question outcomes out of your S3 bucket.
- Delete the EMR Serverless sources.
- Delete
Information-Analystposition andETL-application-rolefrom IAM.
Conclusion
On this publish, we demonstrated the right way to scale the adoption and use of Iceberg tables utilizing Lake Formation permissions for learn workloads, whereas sustaining full management over desk schema and information updates via IAM policy-based permissions for the desk house owners. The methodology additionally applies to different open desk codecs and customary Information Catalog tables, however the Apache Spark configuration for every open desk format will fluctuate.
Hybrid entry mode in Lake Formation is an choice you might use to undertake Lake Formation permissions steadily and scale these use circumstances that assist Lake Formation permissions whereas utilizing IAM primarily based permissions for the use circumstances that don’t. We encourage you to check out this setup in your setting. Please share your suggestions and any extra subjects you want to see within the feedback part.
In regards to the Authors
 Aarthi Srinivasan is a Senior Massive Information Architect with AWS Lake Formation. She collaborates with the service group to boost product options, works with AWS clients and companions to architect lake home options, and establishes finest practices.
Aarthi Srinivasan is a Senior Massive Information Architect with AWS Lake Formation. She collaborates with the service group to boost product options, works with AWS clients and companions to architect lake home options, and establishes finest practices.
 Parul Saxena is a Senior Massive Information Specialist Options Architect in AWS. She helps clients and companions construct extremely optimized, scalable, and safe options. She makes a speciality of Amazon EMR, Amazon Athena, and AWS Lake Formation, offering architectural steering for complicated large information workloads and helping organizations in modernizing their architectures and migrating analytics workloads to AWS.
Parul Saxena is a Senior Massive Information Specialist Options Architect in AWS. She helps clients and companions construct extremely optimized, scalable, and safe options. She makes a speciality of Amazon EMR, Amazon Athena, and AWS Lake Formation, offering architectural steering for complicated large information workloads and helping organizations in modernizing their architectures and migrating analytics workloads to AWS.