{kind=link}

Most AI groups concentrate on the flawed issues. Right here’s a typical scene from my consulting work:
AI TEAM
Right here’s our agent structure—we’ve acquired RAG right here, a router there, and we’re utilizing this new framework for…ME
[Holding up my hand to pause the enthusiastic tech lead]
Are you able to present me the way you’re measuring if any of this really works?… Room goes quiet

Be taught sooner. Dig deeper. See farther.
This scene has performed out dozens of occasions over the past two years. Groups make investments weeks constructing complicated AI techniques however can’t inform me if their modifications are serving to or hurting.
This isn’t stunning. With new instruments and frameworks rising weekly, it’s pure to concentrate on tangible issues we will management—which vector database to make use of, which LLM supplier to decide on, which agent framework to undertake. However after serving to 30+ firms construct AI merchandise, I’ve found that the groups who succeed barely speak about instruments in any respect. As a substitute, they obsess over measurement and iteration.
On this publish, I’ll present you precisely how these profitable groups function. Whereas each scenario is exclusive, you’ll see patterns that apply no matter your area or group dimension. Let’s begin by inspecting the most typical mistake I see groups make—one which derails AI tasks earlier than they even start.
The Most Frequent Mistake: Skipping Error Evaluation
The “instruments first” mindset is the most typical mistake in AI growth. Groups get caught up in structure diagrams, frameworks, and dashboards whereas neglecting the method of truly understanding what’s working and what isn’t.
One consumer proudly confirmed me this analysis dashboard:
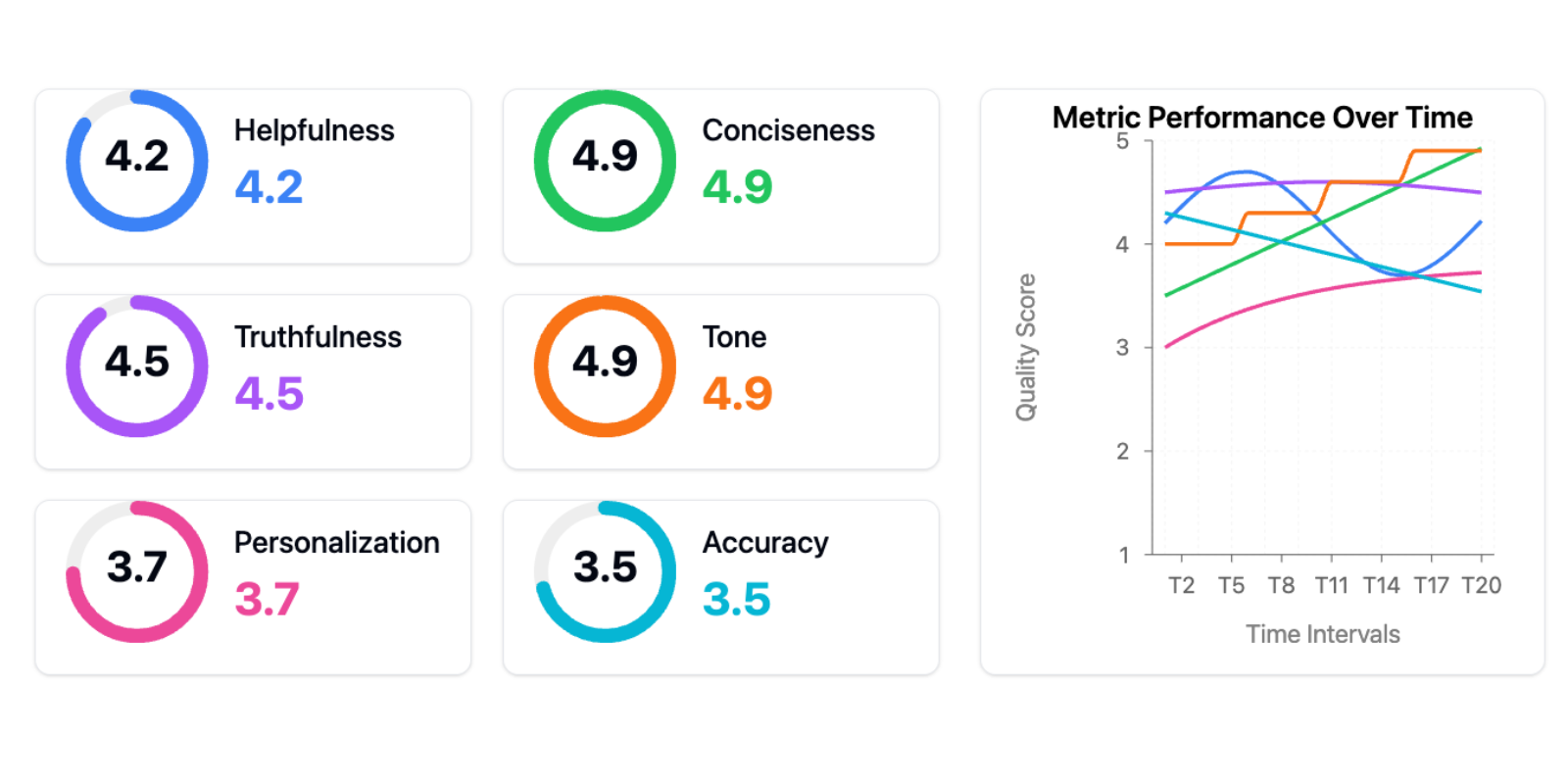
That is the “instruments entice”—the assumption that adopting the appropriate instruments or frameworks (on this case, generic metrics) will remedy your AI issues. Generic metrics are worse than ineffective—they actively impede progress in two methods:
First, they create a false sense of measurement and progress. Groups assume they’re data-driven as a result of they’ve dashboards, however they’re monitoring vainness metrics that don’t correlate with actual person issues. I’ve seen groups have a good time bettering their “helpfulness rating” by 10% whereas their precise customers have been nonetheless scuffling with primary duties. It’s like optimizing your web site’s load time whereas your checkout course of is damaged—you’re getting higher on the flawed factor.
Second, too many metrics fragment your consideration. As a substitute of specializing in the few metrics that matter in your particular use case, you’re making an attempt to optimize a number of dimensions concurrently. When the whole lot is vital, nothing is.
The choice? Error evaluation: the one Most worthy exercise in AI growth and persistently the highest-ROI exercise. Let me present you what efficient error evaluation appears like in observe.
The Error Evaluation Course of
When Jacob, the founding father of Nurture Boss, wanted to enhance the corporate’s apartment-industry AI assistant, his group constructed a easy viewer to look at conversations between their AI and customers. Subsequent to every dialog was an area for open-ended notes about failure modes.
After annotating dozens of conversations, clear patterns emerged. Their AI was scuffling with date dealing with—failing 66% of the time when customers mentioned issues like “Let’s schedule a tour two weeks from now.”
As a substitute of reaching for brand spanking new instruments, they:
- Checked out precise dialog logs
- Categorized the varieties of date-handling failures
- Constructed particular checks to catch these points
- Measured enchancment on these metrics
The consequence? Their date dealing with success charge improved from 33% to 95%.
Right here’s Jacob explaining this course of himself:
Backside-Up Versus Prime-Down Evaluation
When figuring out error varieties, you’ll be able to take both a “top-down” or “bottom-up” method.
The highest-down method begins with widespread metrics like “hallucination” or “toxicity” plus metrics distinctive to your activity. Whereas handy, it usually misses domain-specific points.
The simpler bottom-up method forces you to have a look at precise knowledge and let metrics naturally emerge. At Nurture Boss, we began with a spreadsheet the place every row represented a dialog. We wrote open-ended notes on any undesired conduct. Then we used an LLM to construct a taxonomy of widespread failure modes. Lastly, we mapped every row to particular failure mode labels and counted the frequency of every problem.
The outcomes have been hanging—simply three points accounted for over 60% of all issues:
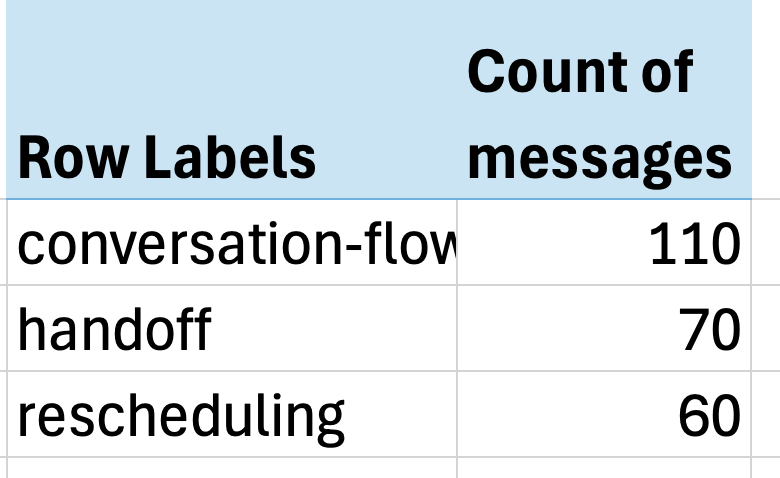
- Dialog stream points (lacking context, awkward responses)
- Handoff failures (not recognizing when to switch to people)
- Rescheduling issues (scuffling with date dealing with)
The impression was instant. Jacob’s group had uncovered so many actionable insights that they wanted a number of weeks simply to implement fixes for the issues we’d already discovered.
If you happen to’d prefer to see error evaluation in motion, we recorded a dwell walkthrough right here.
This brings us to an important query: How do you make it straightforward for groups to have a look at their knowledge? The reply leads us to what I think about a very powerful funding any AI group could make…
The Most Necessary AI Funding: A Easy Information Viewer
The one most impactful funding I’ve seen AI groups make isn’t a elaborate analysis dashboard—it’s constructing a personalized interface that lets anybody look at what their AI is definitely doing. I emphasize personalized as a result of each area has distinctive wants that off-the-shelf instruments not often handle. When reviewing condominium leasing conversations, it’s good to see the total chat historical past and scheduling context. For real-estate queries, you want the property particulars and supply paperwork proper there. Even small UX choices—like the place to position metadata or which filters to reveal—could make the distinction between a software folks really use and one they keep away from.
I’ve watched groups battle with generic labeling interfaces, searching by means of a number of techniques simply to grasp a single interplay. The friction provides up: clicking by means of to completely different techniques to see context, copying error descriptions into separate monitoring sheets, switching between instruments to confirm info. This friction doesn’t simply sluggish groups down—it actively discourages the sort of systematic evaluation that catches delicate points.
Groups with thoughtfully designed knowledge viewers iterate 10x sooner than these with out them. And right here’s the factor: These instruments could be in-built hours utilizing AI-assisted growth (like Cursor or Loveable). The funding is minimal in comparison with the returns.
Let me present you what I imply. Right here’s the information viewer constructed for Nurture Boss (which I mentioned earlier):
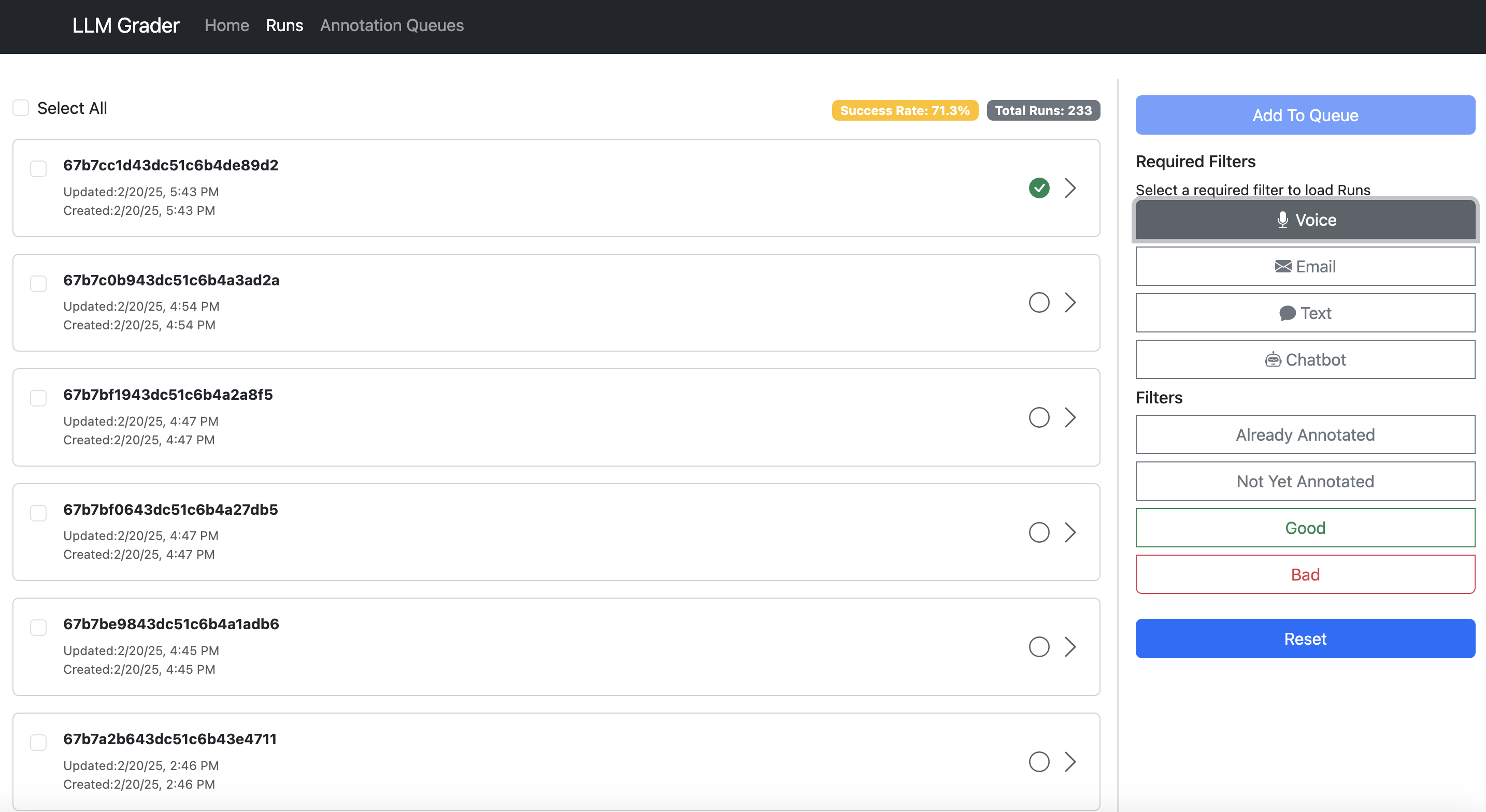
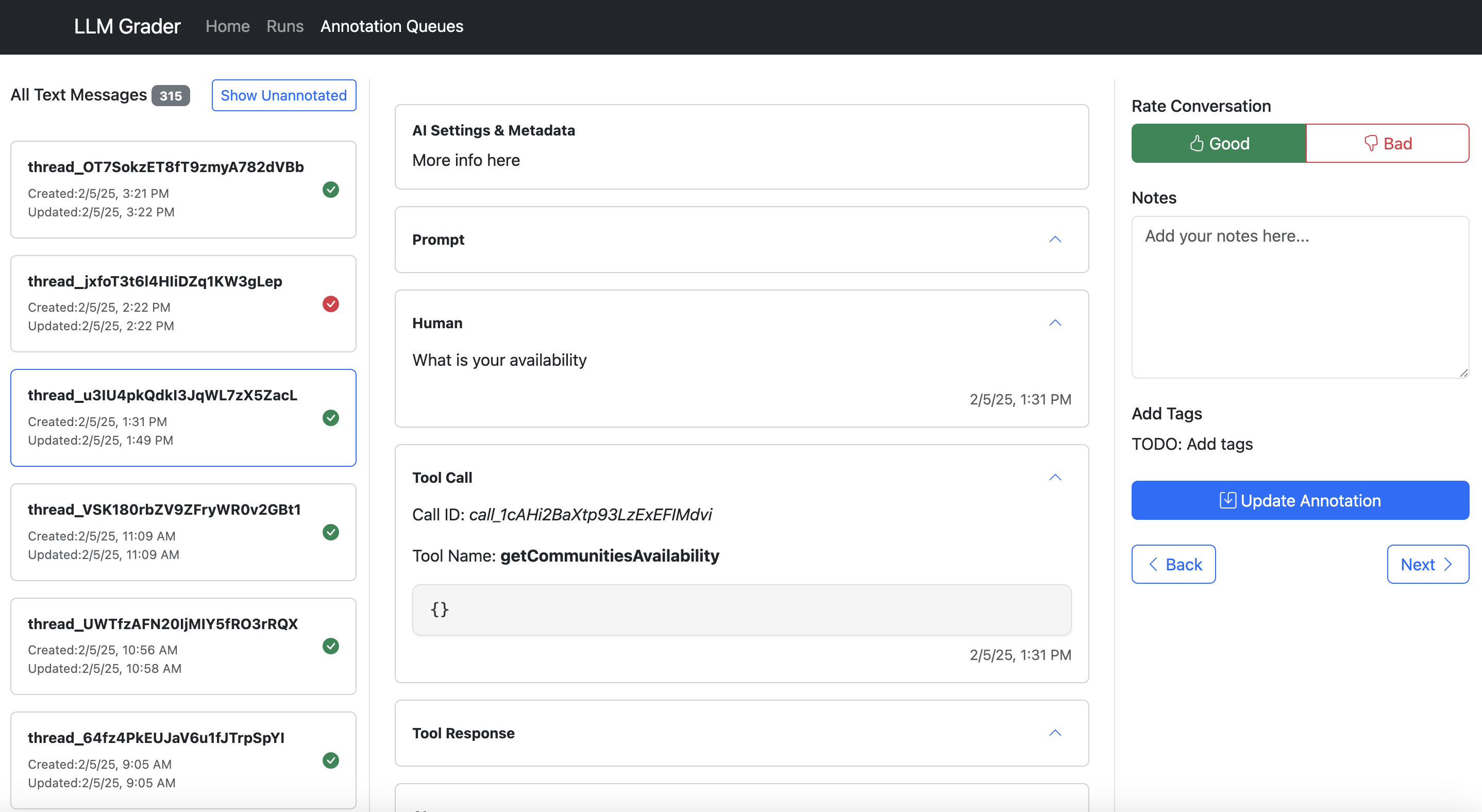
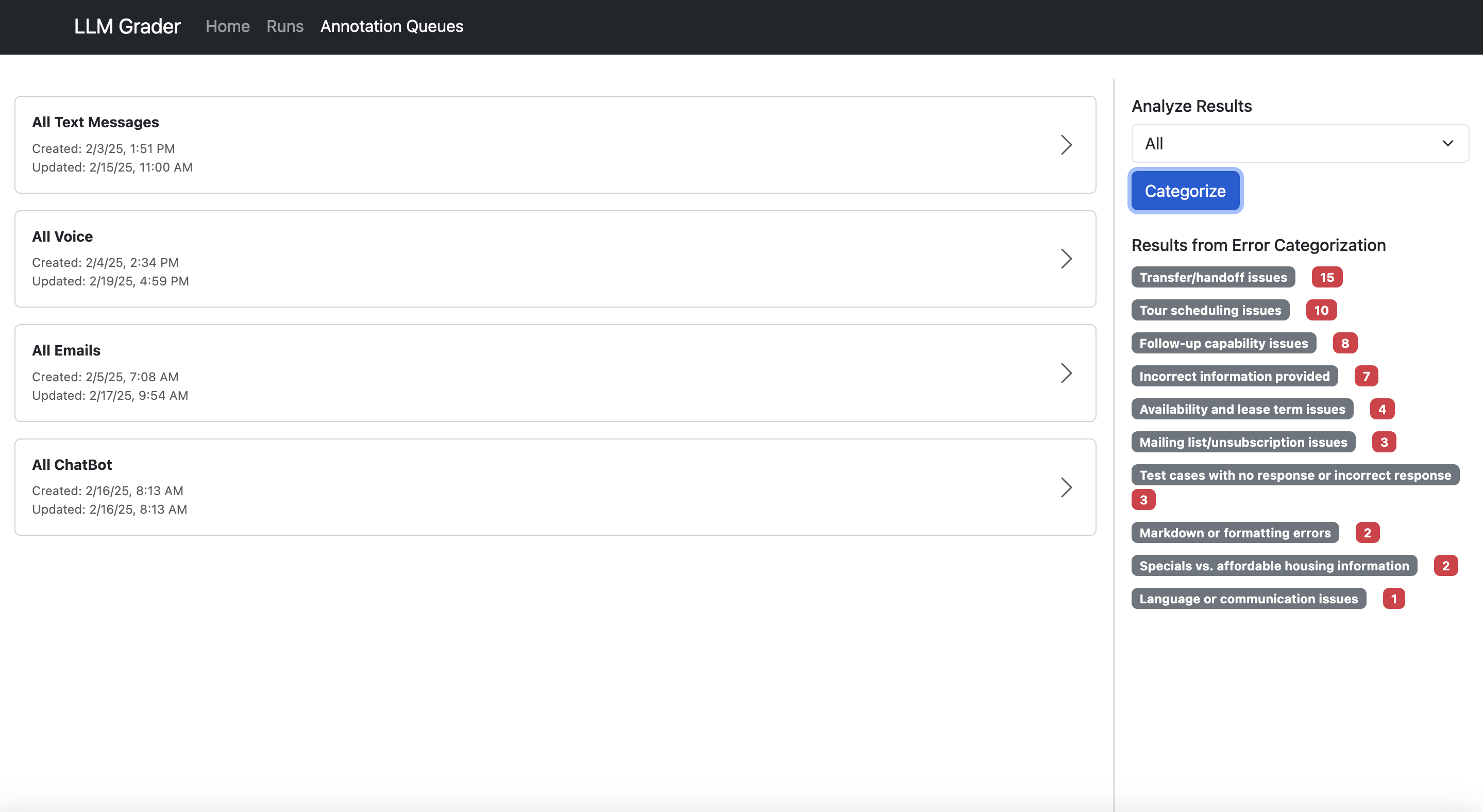
Right here’s what makes knowledge annotation software:
- Present all context in a single place. Don’t make customers hunt by means of completely different techniques to grasp what occurred.
- Make suggestions trivial to seize. One-click appropriate/incorrect buttons beat prolonged kinds.
- Seize open-ended suggestions. This allows you to seize nuanced points that don’t match right into a predefined taxonomy.
- Allow fast filtering and sorting. Groups want to simply dive into particular error varieties. Within the instance above, Nurture Boss can shortly filter by the channel (voice, textual content, chat) or the precise property they wish to take a look at shortly.
- Have hotkeys that enable customers to navigate between knowledge examples and annotate with out clicking.
It doesn’t matter what net frameworks you utilize—use no matter you’re accustomed to. As a result of I’m a Python developer, my present favourite net framework is FastHTML coupled with MonsterUI as a result of it permits me to outline the backend and frontend code in a single small Python file.
The secret’s beginning someplace, even when it’s easy. I’ve discovered customized net apps present the very best expertise, however in the event you’re simply starting, a spreadsheet is healthier than nothing. As your wants develop, you’ll be able to evolve your instruments accordingly.
This brings us to a different counterintuitive lesson: The folks finest positioned to enhance your AI system are sometimes those who know the least about AI.
Empower Area Consultants to Write Prompts
I lately labored with an schooling startup constructing an interactive studying platform with LLMs. Their product supervisor, a studying design knowledgeable, would create detailed PowerPoint decks explaining pedagogical rules and instance dialogues. She’d current these to the engineering group, who would then translate her experience into prompts.
However right here’s the factor: Prompts are simply English. Having a studying knowledgeable talk instructing rules by means of PowerPoint just for engineers to translate that again into English prompts created pointless friction. Probably the most profitable groups flip this mannequin by giving area specialists instruments to put in writing and iterate on prompts straight.
Construct Bridges, Not Gatekeepers
Immediate playgrounds are a terrific start line for this. Instruments like Arize, LangSmith, and Braintrust let groups shortly check completely different prompts, feed in instance datasets, and evaluate outcomes. Listed below are some screenshots of those instruments:
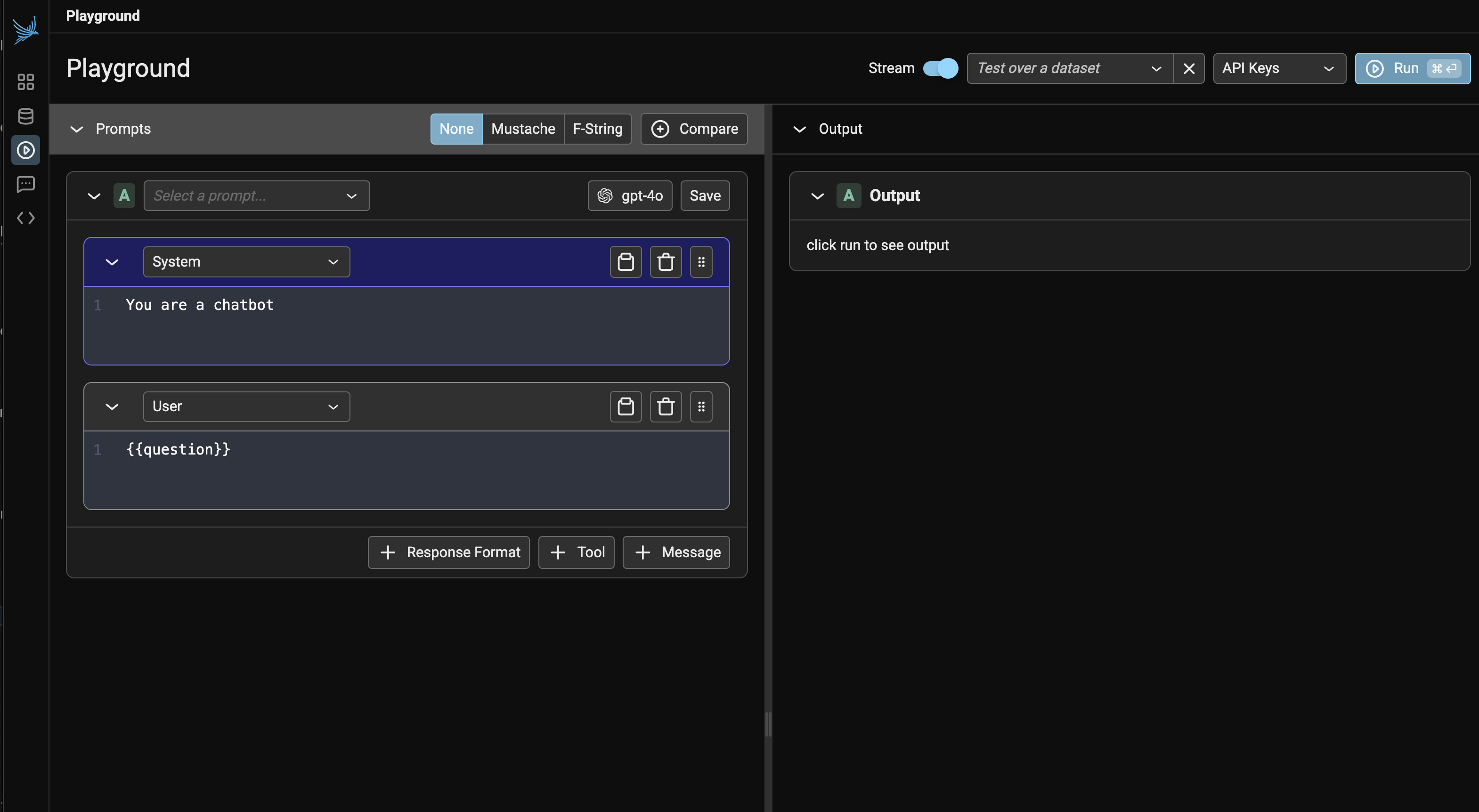
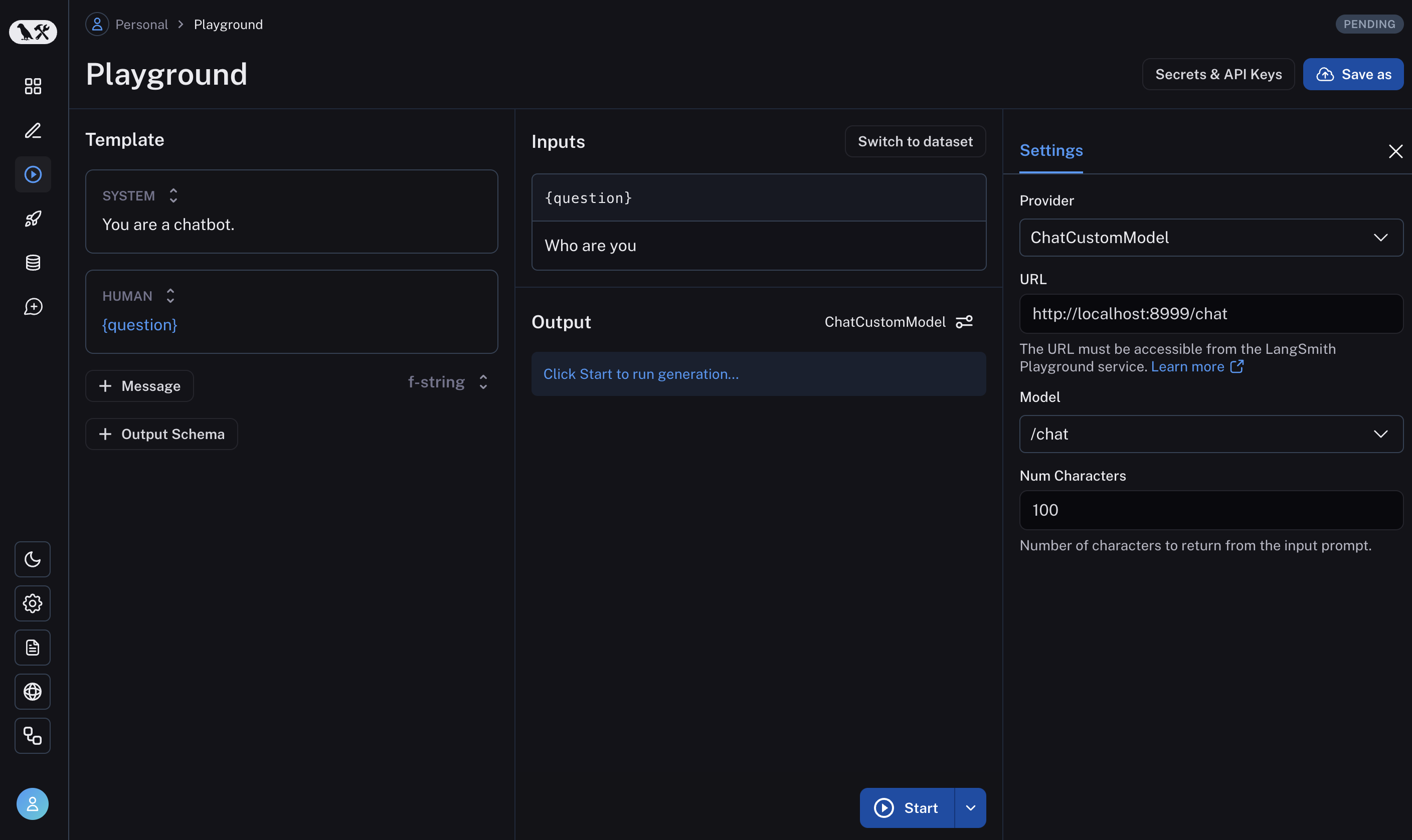
However there’s an important subsequent step that many groups miss: integrating immediate growth into their software context. Most AI purposes aren’t simply prompts; they generally contain RAG techniques pulling out of your information base, agent orchestration coordinating a number of steps, and application-specific enterprise logic. The best groups I’ve labored with transcend stand-alone playgrounds. They construct what I name built-in immediate environments—basically admin variations of their precise person interface that expose immediate modifying.
Right here’s an illustration of what an built-in immediate atmosphere would possibly appear to be for a real-estate AI assistant:
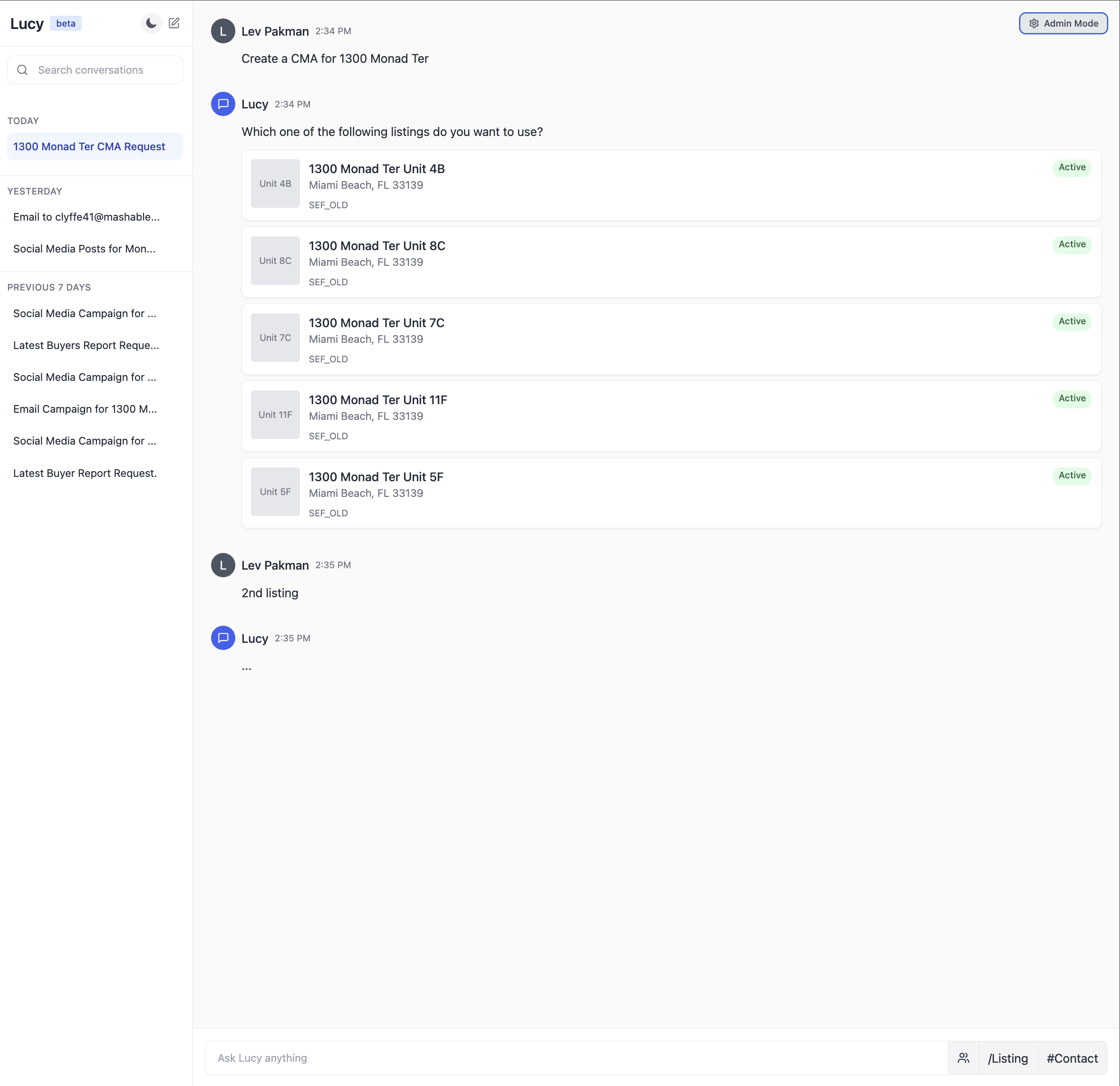
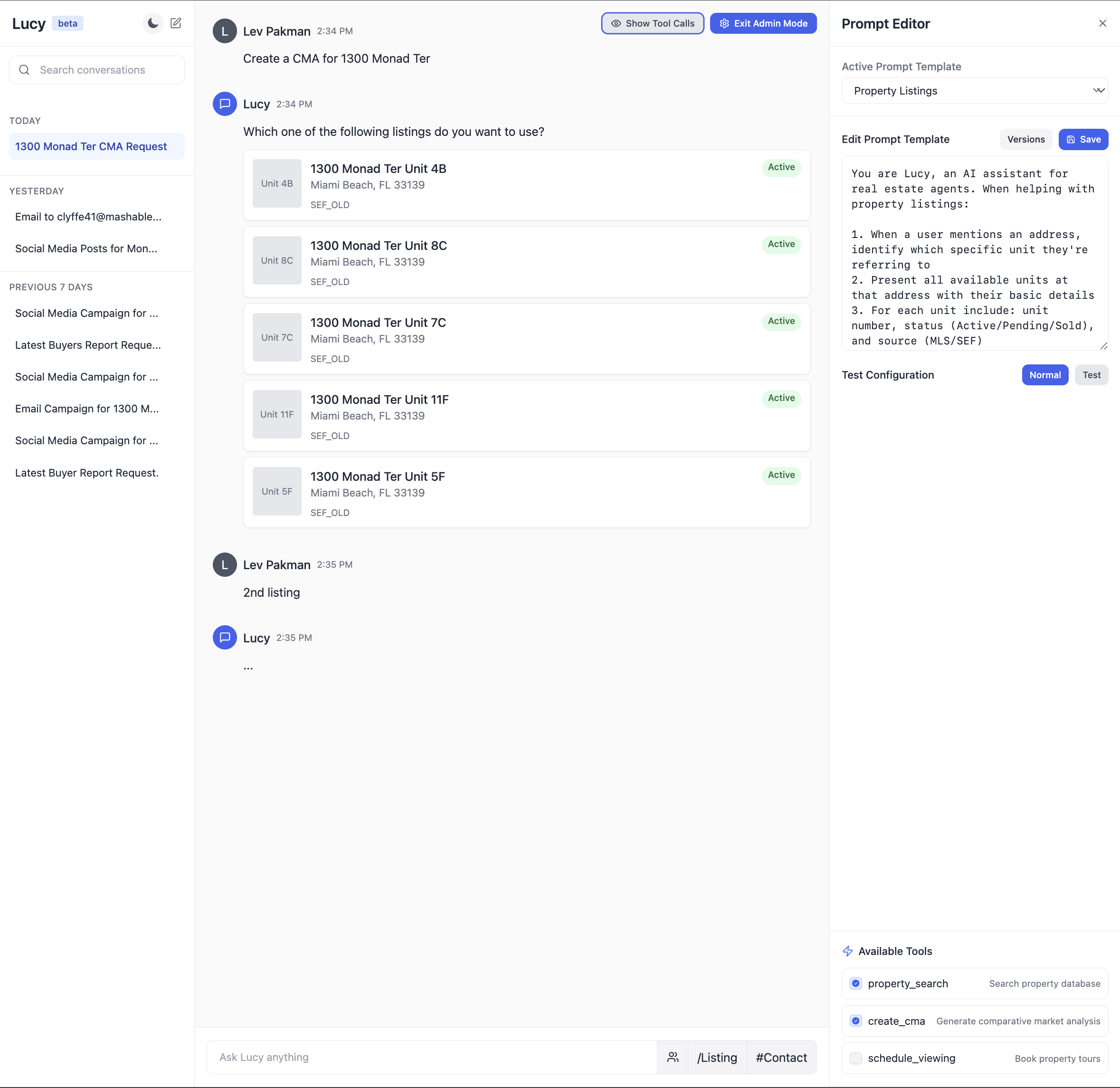
Ideas for Speaking With Area Consultants
There’s one other barrier that always prevents area specialists from contributing successfully: pointless jargon. I used to be working with an schooling startup the place engineers, product managers, and studying specialists have been speaking previous one another in conferences. The engineers saved saying, “We’re going to construct an agent that does XYZ,” when actually the job to be completed was writing a immediate. This created a synthetic barrier—the training specialists, who have been the precise area specialists, felt like they couldn’t contribute as a result of they didn’t perceive “brokers.”
This occurs in every single place. I’ve seen it with attorneys at authorized tech firms, psychologists at psychological well being startups, and medical doctors at healthcare corporations. The magic of LLMs is that they make AI accessible by means of pure language, however we frequently destroy that benefit by wrapping the whole lot in technical terminology.
Right here’s a easy instance of easy methods to translate widespread AI jargon:
| As a substitute of claiming… | Say… |
| “We’re implementing a RAG method.” | “We’re ensuring the mannequin has the appropriate context to reply questions.” |
| “We have to forestall immediate injection.” | “We’d like to verify customers can’t trick the AI into ignoring our guidelines.” |
| “Our mannequin suffers from hallucination points.” | “Generally the AI makes issues up, so we have to verify its solutions.” |
This doesn’t imply dumbing issues down—it means being exact about what you’re really doing. While you say, “We’re constructing an agent,” what particular functionality are you including? Is it perform calling? Device use? Or only a higher immediate? Being particular helps everybody perceive what’s really occurring.
There’s nuance right here. Technical terminology exists for a motive: it gives precision when speaking with different technical stakeholders. The secret’s adapting your language to your viewers.
The problem many groups increase at this level is “This all sounds nice, however what if we don’t have any knowledge but? How can we take a look at examples or iterate on prompts after we’re simply beginning out?” That’s what we’ll speak about subsequent.
Bootstrapping Your AI With Artificial Information Is Efficient (Even With Zero Customers)
Some of the widespread roadblocks I hear from groups is “We will’t do correct analysis as a result of we don’t have sufficient actual person knowledge but.” This creates a chicken-and-egg downside—you want knowledge to enhance your AI, however you want a good AI to get customers who generate that knowledge.
Fortuitously, there’s an answer that works surprisingly effectively: artificial knowledge. LLMs can generate real looking check instances that cowl the vary of situations your AI will encounter.
As I wrote in my LLM-as-a-Choose weblog publish, artificial knowledge could be remarkably efficient for analysis. Bryan Bischof, the previous head of AI at Hex, put it completely:
LLMs are surprisingly good at producing glorious – and various – examples of person prompts. This may be related for powering software options, and sneakily, for constructing Evals. If this sounds a bit just like the Giant Language Snake is consuming its tail, I used to be simply as shocked as you! All I can say is: it really works, ship it.
A Framework for Producing Practical Check Information
The important thing to efficient artificial knowledge is choosing the proper dimensions to check. Whereas these dimensions will range primarily based in your particular wants, I discover it useful to consider three broad classes:
- Options: What capabilities does your AI must assist?
- Eventualities: What conditions will it encounter?
- Person personas: Who shall be utilizing it and the way?
These aren’t the one dimensions you would possibly care about—you may additionally wish to check completely different tones of voice, ranges of technical sophistication, and even completely different locales and languages. The vital factor is figuring out dimensions that matter in your particular use case.
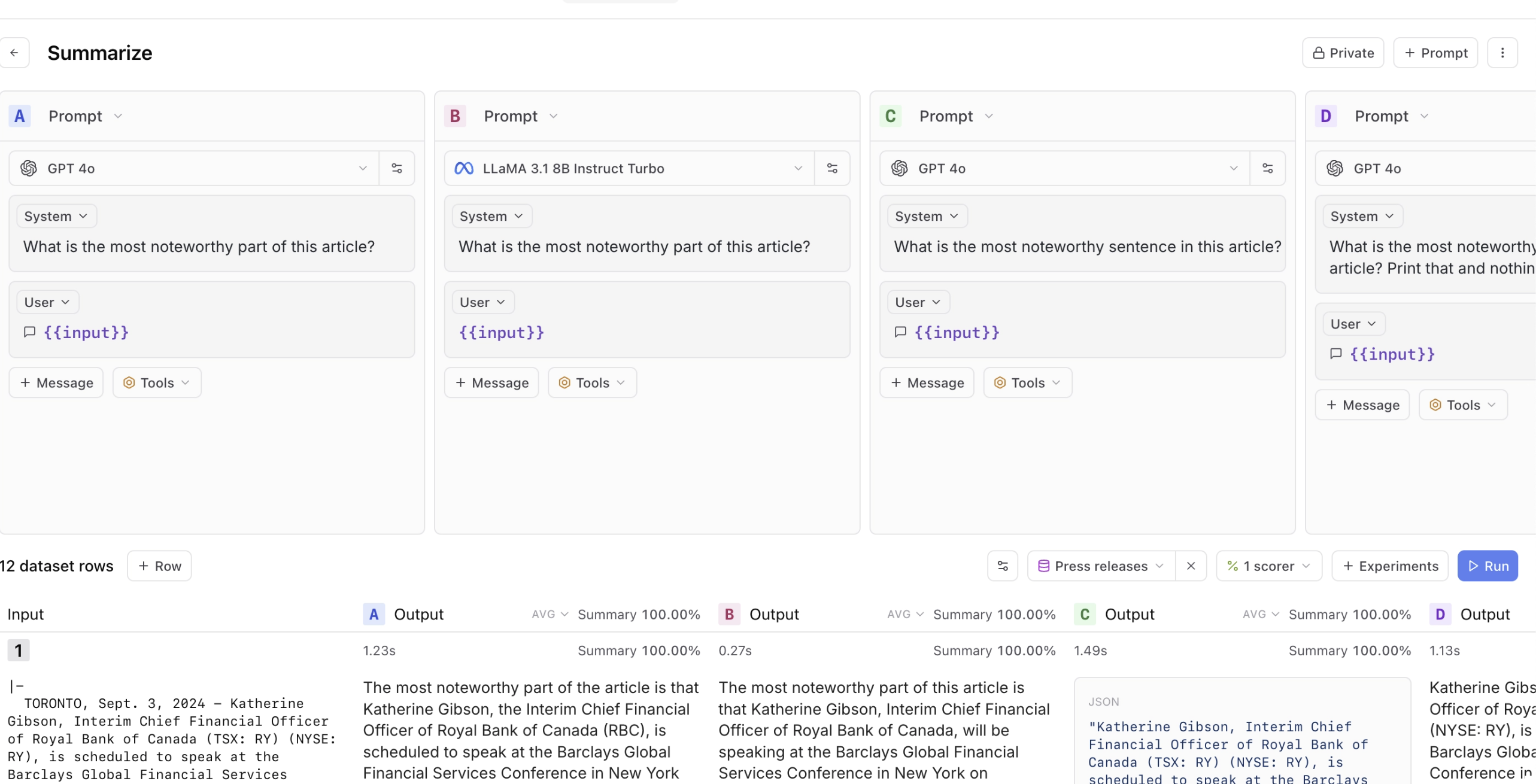
For a real-estate CRM AI assistant I labored on with Rechat, we outlined these dimensions like this:

However having these dimensions outlined is barely half the battle. The actual problem is guaranteeing your artificial knowledge really triggers the situations you wish to check. This requires two issues:
- A check database with sufficient selection to assist your situations
- A approach to confirm that generated queries really set off supposed situations
For Rechat, we maintained a check database of listings that we knew would set off completely different edge instances. Some groups desire to make use of an anonymized copy of manufacturing knowledge, however both manner, it’s good to guarantee your check knowledge has sufficient selection to train the situations you care about.
Right here’s an instance of how we would use these dimensions with actual knowledge to generate check instances for the property search characteristic (that is simply pseudo code, and really illustrative):
def generate_search_query(situation, persona, listing_db): """Generate a practical person question about listings""" # Pull actual itemizing knowledge to floor the technology sample_listings = listing_db.get_sample_listings( price_range=persona.price_range, location=persona.preferred_areas ) # Confirm now we have listings that can set off our situation if situation == "multiple_matches" and len(sample_listings) 0: increase ValueError("Discovered matches when testing no-match situation") immediate = f""" You're an knowledgeable actual property agent who's trying to find listings. You're given a buyer kind and a situation. Your job is to generate a pure language question you'd use to look these listings. Context: - Buyer kind: {persona.description} - Situation: {situation} Use these precise listings as reference: {format_listings(sample_listings)} The question ought to mirror the client kind and the situation. Instance question: Discover properties within the 75019 zip code, 3 bedrooms, 2 bogs, value vary $750k - $1M for an investor. """ return generate_with_llm(immediate) This produced real looking queries like:
| Characteristic | Situation | Persona | Generated Question |
|---|---|---|---|
| property search | a number of matches | first_time_buyer | “Searching for 3-bedroom properties beneath $500k within the Riverside space. Would love one thing near parks since now we have younger children.” |
| market evaluation | no matches | investor | “Want comps for 123 Oak St. Particularly interested by rental yield comparability with comparable properties in a 2-mile radius.” |
The important thing to helpful artificial knowledge is grounding it in actual system constraints. For the real-estate AI assistant, this implies:
- Utilizing actual itemizing IDs and addresses from their database
- Incorporating precise agent schedules and availability home windows
- Respecting enterprise guidelines like displaying restrictions and see durations
- Together with market-specific particulars like HOA necessities or native laws
We then feed these check instances by means of Lucy (now a part of Capability) and log the interactions. This offers us a wealthy dataset to investigate, displaying precisely how the AI handles completely different conditions with actual system constraints. This method helped us repair points earlier than they affected actual customers.
Generally you don’t have entry to a manufacturing database, particularly for brand spanking new merchandise. In these instances, use LLMs to generate each check queries and the underlying check knowledge. For a real-estate AI assistant, this would possibly imply creating artificial property listings with real looking attributes—costs that match market ranges, legitimate addresses with actual road names, and facilities acceptable for every property kind. The secret’s grounding artificial knowledge in real-world constraints to make it helpful for testing. The specifics of producing strong artificial databases are past the scope of this publish.
Tips for Utilizing Artificial Information
When producing artificial knowledge, comply with these key rules to make sure it’s efficient:
- Diversify your dataset: Create examples that cowl a variety of options, situations, and personas. As I wrote in my LLM-as-a-Choose publish, this range helps you determine edge instances and failure modes you won’t anticipate in any other case.
- Generate person inputs, not outputs: Use LLMs to generate real looking person queries or inputs, not the anticipated AI responses. This prevents your artificial knowledge from inheriting the biases or limitations of the producing mannequin.
- Incorporate actual system constraints: Floor your artificial knowledge in precise system limitations and knowledge. For instance, when testing a scheduling characteristic, use actual availability home windows and reserving guidelines.
- Confirm situation protection: Guarantee your generated knowledge really triggers the situations you wish to check. A question supposed to check “no matches discovered” ought to really return zero outcomes when run in opposition to your system.
- Begin easy, then add complexity: Start with simple check instances earlier than including nuance. This helps isolate points and set up a baseline earlier than tackling edge instances.
This method isn’t simply theoretical—it’s been confirmed in manufacturing throughout dozens of firms. What usually begins as a stopgap measure turns into a everlasting a part of the analysis infrastructure, even after actual person knowledge turns into out there.
Let’s take a look at easy methods to keep belief in your analysis system as you scale.
Sustaining Belief In Evals Is Vital
It is a sample I’ve seen repeatedly: Groups construct analysis techniques, then step by step lose religion in them. Generally it’s as a result of the metrics don’t align with what they observe in manufacturing. Different occasions, it’s as a result of the evaluations grow to be too complicated to interpret. Both manner, the consequence is similar: The group reverts to creating choices primarily based on intestine feeling and anecdotal suggestions, undermining your complete function of getting evaluations.
Sustaining belief in your analysis system is simply as vital as constructing it within the first place. Right here’s how essentially the most profitable groups method this problem.
Understanding Standards Drift
Some of the insidious issues in AI analysis is “standards drift”—a phenomenon the place analysis standards evolve as you observe extra mannequin outputs. Of their paper “Who Validates the Validators? Aligning LLM-Assisted Analysis of LLM Outputs with Human Preferences,” Shankar et al. describe this phenomenon:
To grade outputs, folks must externalize and outline their analysis standards; nonetheless, the method of grading outputs helps them to outline that very standards.
This creates a paradox: You possibly can’t totally outline your analysis standards till you’ve seen a variety of outputs, however you want standards to judge these outputs within the first place. In different phrases, it’s unattainable to utterly decide analysis standards previous to human judging of LLM outputs.
I’ve noticed this firsthand when working with Phillip Carter at Honeycomb on the corporate’s Question Assistant characteristic. As we evaluated the AI’s potential to generate database queries, Phillip seen one thing attention-grabbing:
Seeing how the LLM breaks down its reasoning made me notice I wasn’t being constant about how I judged sure edge instances.
The method of reviewing AI outputs helped him articulate his personal analysis requirements extra clearly. This isn’t an indication of poor planning—it’s an inherent attribute of working with AI techniques that produce various and generally sudden outputs.
The groups that keep belief of their analysis techniques embrace this actuality reasonably than combating it. They deal with analysis standards as residing paperwork that evolve alongside their understanding of the issue house. Additionally they acknowledge that completely different stakeholders might need completely different (generally contradictory) standards, they usually work to reconcile these views reasonably than imposing a single commonplace.
Creating Reliable Analysis Techniques
So how do you construct analysis techniques that stay reliable regardless of standards drift? Listed below are the approaches I’ve discovered only:
1. Favor Binary Selections Over Arbitrary Scales
As I wrote in my LLM-as-a-Choose publish, binary choices present readability that extra complicated scales usually obscure. When confronted with a 1–5 scale, evaluators regularly battle with the distinction between a 3 and a 4, introducing inconsistency and subjectivity. What precisely distinguishes “considerably useful” from “useful”? These boundary instances devour disproportionate psychological power and create noise in your analysis knowledge. And even when companies use a 1–5 scale, they inevitably ask the place to attract the road for “ok” or to set off intervention, forcing a binary resolution anyway.
In distinction, a binary go/fail forces evaluators to make a transparent judgment: Did this output obtain its function or not? This readability extends to measuring progress—a ten% enhance in passing outputs is straight away significant, whereas a 0.5-point enchancment on a 5-point scale requires interpretation.
I’ve discovered that groups who resist binary analysis usually achieve this as a result of they wish to seize nuance. However nuance isn’t misplaced—it’s simply moved to the qualitative critique that accompanies the judgment. The critique gives wealthy context about why one thing handed or failed and what particular facets may very well be improved, whereas the binary resolution creates actionable readability about whether or not enchancment is required in any respect.
2. Improve Binary Judgments With Detailed Critiques
Whereas binary choices present readability, they work finest when paired with detailed critiques that seize the nuance of why one thing handed or failed. This mixture offers you the very best of each worlds: clear, actionable metrics and wealthy contextual understanding.
For instance, when evaluating a response that accurately solutions a person’s query however accommodates pointless info, critique would possibly learn:
The AI efficiently offered the market evaluation requested (PASS), however included extreme element about neighborhood demographics that wasn’t related to the funding query. This makes the response longer than vital and doubtlessly distracting.
These critiques serve a number of features past simply rationalization. They power area specialists to externalize implicit information—I’ve seen authorized specialists transfer from imprecise emotions that one thing “doesn’t sound correct” to articulating particular points with quotation codecs or reasoning patterns that may be systematically addressed.
When included as few-shot examples in decide prompts, these critiques enhance the LLM’s potential to motive about complicated edge instances. I’ve discovered this method usually yields 15%–20% greater settlement charges between human and LLM evaluations in comparison with prompts with out instance critiques. The critiques additionally present glorious uncooked materials for producing high-quality artificial knowledge, making a flywheel for enchancment.
3. Measure Alignment Between Automated Evals and Human Judgment
If you happen to’re utilizing LLMs to judge outputs (which is usually vital at scale), it’s essential to often verify how effectively these automated evaluations align with human judgment.
That is notably vital given our pure tendency to over-trust AI techniques. As Shankar et al. observe in “Who Validates the Validators?,” the shortage of instruments to validate evaluator high quality is regarding.
Analysis exhibits folks are inclined to over-rely and over-trust AI techniques. As an illustration, in a single excessive profile incident, researchers from MIT posted a pre-print on arXiv claiming that GPT-4 may ace the MIT EECS examination. Inside hours, [the] work [was] debunked. . .citing issues arising from over-reliance on GPT-4 to grade itself.
This overtrust downside extends past self-evaluation. Analysis has proven that LLMs could be biased by easy components just like the ordering of choices in a set and even seemingly innocuous formatting modifications in prompts. With out rigorous human validation, these biases can silently undermine your analysis system.
When working with Honeycomb, we tracked settlement charges between our LLM-as-a-judge and Phillip’s evaluations:
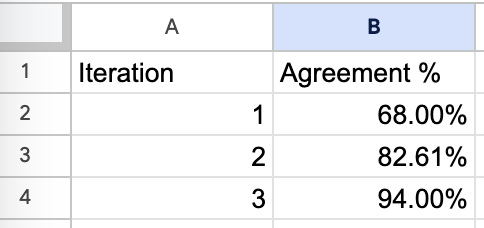
It took three iterations to realize >90% settlement, however this funding paid off in a system the group may belief. With out this validation step, automated evaluations usually drift from human expectations over time, particularly because the distribution of inputs modifications. You possibly can learn extra about this right here.
Instruments like Eugene Yan’s AlignEval reveal this alignment course of fantastically. AlignEval gives a easy interface the place you add knowledge, label examples with a binary “good” or “unhealthy,” after which consider LLM-based judges in opposition to these human judgments. What makes it efficient is the way it streamlines the workflow—you’ll be able to shortly see the place automated evaluations diverge out of your preferences, refine your standards primarily based on these insights, and measure enchancment over time. This method reinforces that alignment isn’t a one-time setup however an ongoing dialog between human judgment and automatic analysis.
Scaling With out Dropping Belief
As your AI system grows, you’ll inevitably face strain to cut back the human effort concerned in analysis. That is the place many groups go flawed—they automate an excessive amount of, too shortly, and lose the human connection that retains their evaluations grounded.
Probably the most profitable groups take a extra measured method:
- Begin with excessive human involvement: Within the early levels, have area specialists consider a major share of outputs.
- Examine alignment patterns: Quite than automating analysis, concentrate on understanding the place automated evaluations align with human judgment and the place they diverge. This helps you determine which varieties of instances want extra cautious human consideration.
- Use strategic sampling: Quite than evaluating each output, use statistical methods to pattern outputs that present essentially the most info, notably specializing in areas the place alignment is weakest.
- Preserve common calibration: At the same time as you scale, proceed to check automated evaluations in opposition to human judgment often, utilizing these comparisons to refine your understanding of when to belief automated evaluations.
Scaling analysis isn’t nearly lowering human effort—it’s about directing that effort the place it provides essentially the most worth. By focusing human consideration on essentially the most difficult or informative instances, you’ll be able to keep high quality at the same time as your system grows.
Now that we’ve coated easy methods to keep belief in your evaluations, let’s speak about a basic shift in how it’s best to method AI growth roadmaps.
Your AI Roadmap Ought to Depend Experiments, Not Options
If you happen to’ve labored in software program growth, you’re accustomed to conventional roadmaps: a listing of options with goal supply dates. Groups decide to transport particular performance by particular deadlines, and success is measured by how intently they hit these targets.
This method fails spectacularly with AI.
I’ve watched groups decide to roadmap goals like “Launch sentiment evaluation by Q2” or “Deploy agent-based buyer assist by finish of 12 months,” solely to find that the expertise merely isn’t prepared to fulfill their high quality bar. They both ship one thing subpar to hit the deadline or miss the deadline fully. Both manner, belief erodes.
The elemental downside is that conventional roadmaps assume we all know what’s attainable. With typical software program, that’s usually true—given sufficient time and sources, you’ll be able to construct most options reliably. With AI, particularly on the innovative, you’re continually testing the boundaries of what’s possible.
Experiments Versus Options
Bryan Bischof, former head of AI at Hex, launched me to what he calls a “functionality funnel” method to AI roadmaps. This technique reframes how we take into consideration AI growth progress. As a substitute of defining success as transport a characteristic, the potential funnel breaks down AI efficiency into progressive ranges of utility. On the high of the funnel is essentially the most primary performance: Can the system reply in any respect? On the backside is totally fixing the person’s job to be completed. Between these factors are numerous levels of accelerating usefulness.
For instance, in a question assistant, the potential funnel would possibly appear to be:
- Can generate syntactically legitimate queries (primary performance)
- Can generate queries that execute with out errors
- Can generate queries that return related outcomes
- Can generate queries that match person intent
- Can generate optimum queries that remedy the person’s downside (full answer)
This method acknowledges that AI progress isn’t binary—it’s about step by step bettering capabilities throughout a number of dimensions. It additionally gives a framework for measuring progress even once you haven’t reached the ultimate objective.
Probably the most profitable groups I’ve labored with construction their roadmaps round experiments reasonably than options. As a substitute of committing to particular outcomes, they decide to a cadence of experimentation, studying, and iteration.
Eugene Yan, an utilized scientist at Amazon, shared how he approaches ML venture planning with management—a course of that, whereas initially developed for conventional machine studying, applies equally effectively to trendy LLM growth:
Right here’s a typical timeline. First, I take two weeks to do an information feasibility evaluation, i.e., “Do I’ve the appropriate knowledge?”…Then I take a further month to do a technical feasibility evaluation, i.e., “Can AI remedy this?” After that, if it nonetheless works I’ll spend six weeks constructing a prototype we will A/B check.
Whereas LLMs won’t require the identical sort of characteristic engineering or mannequin coaching as conventional ML, the underlying precept stays the identical: time-box your exploration, set up clear resolution factors, and concentrate on proving feasibility earlier than committing to full implementation. This method offers management confidence that sources received’t be wasted on open-ended exploration, whereas giving the group the liberty to study and adapt as they go.
The Basis: Analysis Infrastructure
The important thing to creating an experiment-based roadmap work is having strong analysis infrastructure. With out it, you’re simply guessing whether or not your experiments are working. With it, you’ll be able to quickly iterate, check hypotheses, and construct on successes.
I noticed this firsthand through the early growth of GitHub Copilot. What most individuals don’t notice is that the group invested closely in constructing subtle offline analysis infrastructure. They created techniques that might check code completions in opposition to a really giant corpus of repositories on GitHub, leveraging unit checks that already existed in high-quality codebases as an automatic approach to confirm completion correctness. This was an enormous engineering enterprise—they needed to construct techniques that might clone repositories at scale, arrange their environments, run their check suites, and analyze the outcomes, all whereas dealing with the unimaginable range of programming languages, frameworks, and testing approaches.
This wasn’t wasted time—it was the muse that accelerated the whole lot. With stable analysis in place, the group ran 1000’s of experiments, shortly recognized what labored, and will say with confidence “This transformation improved high quality by X%” as a substitute of counting on intestine emotions. Whereas the upfront funding in analysis feels sluggish, it prevents limitless debates about whether or not modifications assist or harm and dramatically accelerates innovation later.
Speaking This to Stakeholders
The problem, in fact, is that executives usually need certainty. They wish to know when options will ship and what they’ll do. How do you bridge this hole?
The secret’s to shift the dialog from outputs to outcomes. As a substitute of promising particular options by particular dates, decide to a course of that can maximize the probabilities of attaining the specified enterprise outcomes.
Eugene shared how he handles these conversations:
I attempt to reassure management with timeboxes. On the finish of three months, if it really works out, then we transfer it to manufacturing. At any step of the way in which, if it doesn’t work out, we pivot.
This method offers stakeholders clear resolution factors whereas acknowledging the inherent uncertainty in AI growth. It additionally helps handle expectations about timelines—as a substitute of promising a characteristic in six months, you’re promising a transparent understanding of whether or not that characteristic is possible in three months.
Bryan’s functionality funnel method gives one other highly effective communication software. It permits groups to point out concrete progress by means of the funnel levels, even when the ultimate answer isn’t prepared. It additionally helps executives perceive the place issues are occurring and make knowledgeable choices about the place to take a position sources.
Construct a Tradition of Experimentation By way of Failure Sharing
Maybe essentially the most counterintuitive facet of this method is the emphasis on studying from failures. In conventional software program growth, failures are sometimes hidden or downplayed. In AI growth, they’re the first supply of studying.
Eugene operationalizes this at his group by means of what he calls a “fifteen-five”—a weekly replace that takes fifteen minutes to put in writing and 5 minutes to learn:
In my fifteen-fives, I doc my failures and my successes. Inside our group, we even have weekly “no-prep sharing classes” the place we focus on what we’ve been engaged on and what we’ve discovered. Once I do that, I am going out of my approach to share failures.
This observe normalizes failure as a part of the training course of. It exhibits that even skilled practitioners encounter dead-ends, and it accelerates group studying by sharing these experiences brazenly. And by celebrating the method of experimentation reasonably than simply the outcomes, groups create an atmosphere the place folks really feel protected taking dangers and studying from failures.
A Higher Means Ahead
So what does an experiment-based roadmap appear to be in observe? Right here’s a simplified instance from a content material moderation venture Eugene labored on:
I used to be requested to do content material moderation. I mentioned, “It’s unsure whether or not we’ll meet that objective. It’s unsure even when that objective is possible with our knowledge, or what machine studying methods would work. However right here’s my experimentation roadmap. Listed below are the methods I’m gonna strive, and I’m gonna replace you at a two-week cadence.”
The roadmap didn’t promise particular options or capabilities. As a substitute, it dedicated to a scientific exploration of attainable approaches, with common check-ins to evaluate progress and pivot if vital.
The outcomes have been telling:
For the primary two to 3 months, nothing labored. . . .After which [a breakthrough] got here out. . . .Inside a month, that downside was solved. So you’ll be able to see that within the first quarter and even 4 months, it was going nowhere. . . .However then you can too see that hastily, some new expertise…, some new paradigm, some new reframing comes alongside that simply [solves] 80% of [the problem].
This sample—lengthy durations of obvious failure adopted by breakthroughs—is widespread in AI growth. Conventional feature-based roadmaps would have killed the venture after months of “failure,” lacking the eventual breakthrough.
By specializing in experiments reasonably than options, groups create house for these breakthroughs to emerge. Additionally they construct the infrastructure and processes that make breakthroughs extra seemingly: knowledge pipelines, analysis frameworks, and fast iteration cycles.
Probably the most profitable groups I’ve labored with begin by constructing analysis infrastructure earlier than committing to particular options. They create instruments that make iteration sooner and concentrate on processes that assist fast experimentation. This method may appear slower at first, but it surely dramatically accelerates growth in the long term by enabling groups to study and adapt shortly.
The important thing metric for AI roadmaps isn’t options shipped—it’s experiments run. The groups that win are these that may run extra experiments, study sooner, and iterate extra shortly than their rivals. And the muse for this fast experimentation is all the time the identical: strong, trusted analysis infrastructure that offers everybody confidence within the outcomes.
By reframing your roadmap round experiments reasonably than options, you create the situations for comparable breakthroughs in your personal group.
Conclusion
All through this publish, I’ve shared patterns I’ve noticed throughout dozens of AI implementations. Probably the most profitable groups aren’t those with essentially the most subtle instruments or essentially the most superior fashions—they’re those that grasp the basics of measurement, iteration, and studying.
The core rules are surprisingly easy:
- Take a look at your knowledge. Nothing replaces the perception gained from inspecting actual examples. Error evaluation persistently reveals the highest-ROI enhancements.
- Construct easy instruments that take away friction. Customized knowledge viewers that make it straightforward to look at AI outputs yield extra insights than complicated dashboards with generic metrics.
- Empower area specialists. The individuals who perceive your area finest are sometimes those who can most successfully enhance your AI, no matter their technical background.
- Use artificial knowledge strategically. You don’t want actual customers to begin testing and bettering your AI. Thoughtfully generated artificial knowledge can bootstrap your analysis course of.
- Preserve belief in your evaluations. Binary judgments with detailed critiques create readability whereas preserving nuance. Common alignment checks guarantee automated evaluations stay reliable.
- Construction roadmaps round experiments, not options. Decide to a cadence of experimentation and studying reasonably than particular outcomes by particular dates.
These rules apply no matter your area, group dimension, or technical stack. They’ve labored for firms starting from early-stage startups to tech giants, throughout use instances from buyer assist to code technology.
Assets for Going Deeper
If you happen to’d prefer to discover these subjects additional, listed here are some sources which may assist:
- My weblog for extra content material on AI analysis and enchancment. My different posts dive into extra technical element on subjects reminiscent of establishing efficient LLM judges, implementing analysis techniques, and different facets of AI growth.1 Additionally take a look at the blogs of Shreya Shankar and Eugene Yan, who’re additionally nice sources of knowledge on these subjects.
- A course I’m instructing, Quickly Enhance AI Merchandise with Evals, with Shreya Shankar. It gives hands-on expertise with methods reminiscent of error evaluation, artificial knowledge technology, and constructing reliable analysis techniques, and contains sensible workouts and customized instruction by means of workplace hours.
- If you happen to’re in search of hands-on steerage particular to your group’s wants, you’ll be able to study extra about working with me at Parlance Labs.
Footnotes
- I write extra broadly about machine studying, AI, and software program growth. Some posts that increase on these subjects embrace “Your AI Product Wants Evals,” “Making a LLM-as-a-Choose That Drives Enterprise Outcomes,” and “What We’ve Realized from a 12 months of Constructing with LLMs.” You possibly can see all my posts at hamel.dev.