{kind=link}

Abstract: LLMs have revolutionized software program improvement by rising the productiveness of programmers. Nonetheless, regardless of off-the-shelf LLMs being educated on a major quantity of code, they don’t seem to be good. One key problem for our Enterprise prospects is the necessity to carry out information intelligence, i.e., to adapt and motive utilizing their very own group’s information. This contains with the ability to use organization-specific coding ideas, data, and preferences. On the similar time, we wish to maintain latency and price low. On this weblog, we show how fine-tuning a small open-source LLM on interplay information permits state-of-the-art accuracy, low price, and minimal latency.

Determine 1: Fast Repair helps customers resolve errors by suggesting code fixes in-line.
TL;DR of End result: We concentrate on the duty of program restore which requires fixing bugs in code. This downside has been broadly studied within the literature with out LLMs [1, 2] and extra not too long ago with LLMs [3, 4]. In business, sensible LLM brokers such because the Databricks Fast Repair can be found. Determine 1 exhibits the Fast Repair agent in motion in a Databricks Pocket book surroundings. On this venture, we fine-tuned the Llama 3.1 8b Instruct mannequin on inner code written by Databricks workers for analyzing telemetry. The fine-tuned Llama mannequin is evaluated in opposition to different LLMs by way of a stay A/B check on inner customers. We current ends in Determine 2 exhibiting that the fine-tuned Llama achieves 1.4x enchancment in acceptance charge over GPT-4o whereas reaching a 2x discount in inference latency.
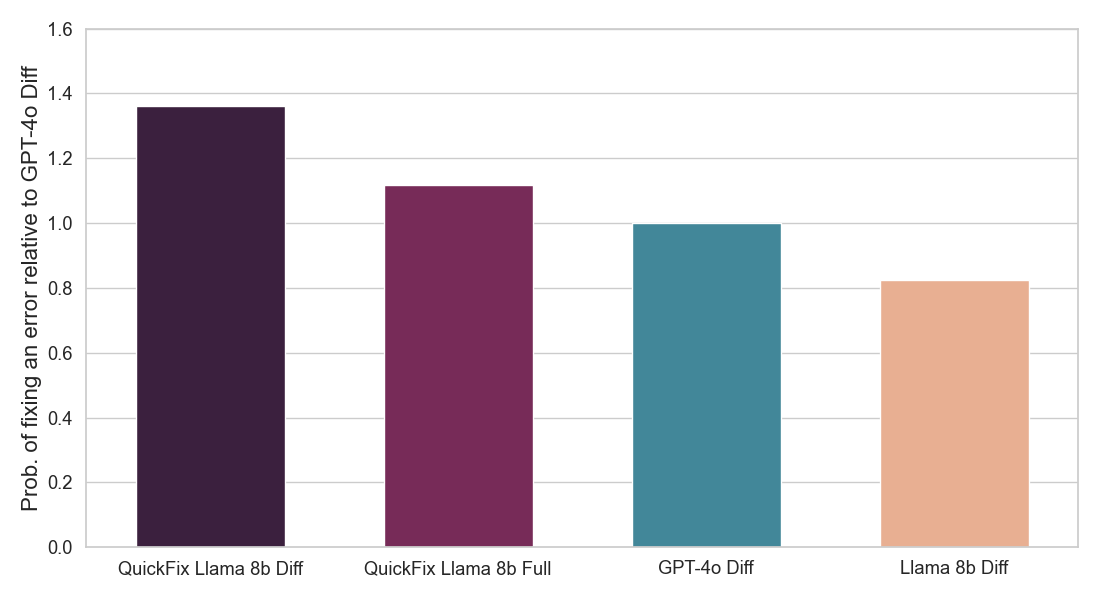
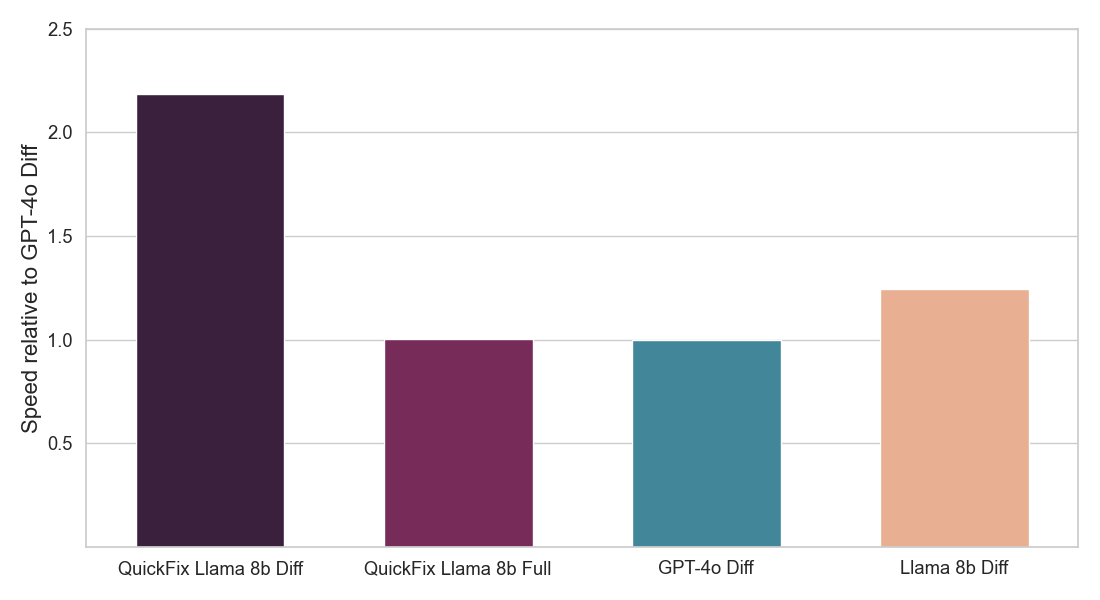
Determine 2: Exhibits fraction of proposed LLM fixes that had been accepted by customers (above) and inference velocity of every Fast Repair LLM agent (under). Each numbers are normalized with respect to the GPT-4o agent (see particulars under). Our mannequin (QuickFix Llama 8b Diff) achieves each the best accuracy and lowest latency. Fashions with the suffix diff generate edits to the buggy code, whereas these with the suffix full generate the complete code.
Why does it matter? Many organizations, together with many present Databricks prospects, have coding utilization information that comprises inhouse data, ideas, and preferences. Primarily based on our outcomes, these organizations can fine-tune small open-source LLMs that obtain higher code high quality and inference velocity. These fashions can then be hosted by the group or a trusted third celebration for price, reliability, and compliance wins.
We emphasize that coaching on interplay information is especially efficient for 3 causes. Firstly, it’s naturally generated – so requires no annotation effort. Secondly, it comprises examples which are encountered in observe and so it’s significantly helpful for fine-tuning even in average portions. Lastly, as interplay information is continually generated by interactions with the LLM agent, we are able to repeatedly use newly generated interplay information to additional fine-tune our LLM resulting in By no means Ending Studying (NEL).
What’s subsequent? We consider that these classes are additionally true for different enterprise purposes. Organizations can fine-tune LLMs akin to Llama for program restore or different duties utilizing Databricks’ fine-tuning service and serve the mannequin in only one click on. You will get began right here. We’re additionally exploring providing prospects the power to personalize Fast Repair utilizing their very own information.
Particulars of Our Research
A Databricks Workspace supplies a number of LLM brokers for enhancing productiveness. These embody an LLM agent for code autocomplete, an AI assistant which might interact in conversations to assist customers, and the Fast Repair agent for program restore. On this blogpost, we concentrate on the Fast Repair agent (Determine 1).
Program restore is a difficult downside in observe. The errors can vary from syntactic errors to improper column names to refined semantic points. Additional, there are personalization elements or constraints which aren’t at all times properly dealt with by off-the-shelf LLMs. For instance, Databricks customers usually write commonplace ANSI or Spark SQL, not PL/SQL scripts, however a unique format could also be most popular by different organizations. Equally, when fixing the code, we don’t wish to change the coding model even when the proposed repair is appropriate. One can use a proprietary mannequin akin to GPT-4, o1, or Claude 3.5 together with immediate engineering to try to treatment these limitations. Nonetheless, immediate engineering will not be as efficient as fine-tuning. Additional, these fashions are costly, and latency is an important issue, since we wish to recommend fixes earlier than the person can repair the code themselves. Immediate engineering approaches akin to in-context studying [5] or self-reflection [6] can additional enhance latency. Lastly, some prospects could also be hesitant to make use of proprietary fashions hosted elsewhere.
Small open-source fashions akin to Llama 8b, Gemma 4b, R1 Distill Llama 8b and Qwen 7b provide another with completely different tradeoffs. These fashions could be low cost, quick, and be educated and hosted by the group or a trusted third-party for higher compliance. Nonetheless, they have a tendency to carry out considerably worse than a few of the proprietary fashions listed above. As we are able to see in Determine 1, the Llama 3.1 8b instruct mannequin is the worst performing of the fashions examined. This raises the query:
Can we adapt small, open-source fashions and nonetheless outperform off-the-shelf proprietary fashions on accuracy, price and velocity?
Whereas immediate engineering supplies some beneficial properties (see outcomes under), it tends to be much less efficient than fine-tuning the LLM, particularly for smaller fashions. Nonetheless, to carry out efficient fine-tuning, we’d like applicable area information. The place can we get this?
Tremendous-tuning Llama 8b utilizing your Interplay Knowledge
For program restore duties, one can use interplay information that’s organically generated by customers to carry out fine-tuning. This works as follows (Determine 3):
 Determine 3: We use deployment logs for fine-tuning LLMs which can be utilized for by no means ending fine-tuning of LLMs.
Determine 3: We use deployment logs for fine-tuning LLMs which can be utilized for by no means ending fine-tuning of LLMs.
- We log the buggy code y, the primary time the person executes the code cell resulting in an error. We additionally log any further context x such because the error message, surrounding code cells, and metadata (e.g. listing of obtainable tables and APIs).
- We then log the code y’ the following time the person efficiently executes the code within the originally-buggy cell. This response might be doubtlessly generated by the Fast Repair Llama agent, by the person themselves, or by each.
- We retailer (x, y, y’) in a dataset for fine-tuning.
We filter two excessive instances: the place the supposed mounted code y’ is similar because the precise code y, indicating bugfix attributable to exterior causes (e.g., fixing a permission problem by way of altering config elsewhere), and the place y’ is considerably completely different than y, indicating a possible re-write quite than a focused repair. We are able to use this information to carry out fine-tuning by studying to generate y’ given context x and buggy code y.
We use Databricks’ personal inner interplay information, processed as described above, to fine-tune a Llama 3.1 8b Instruct mannequin. We prepare two varieties of mannequin – one which generates the whole mounted code (full fashions) and one which solely generates the code diff wanted to repair the buggy code (diff fashions). The latter tends to be sooner as they should produce fewer tokens, however they remedy a tougher activity. We used Databricks’ fine-tuning service and did a sweep over completely different studying charges and coaching iterations. The outcomes of our A/B check in Determine 2 present that our fine-tuned Llama mannequin is each considerably higher at fixing bugs than off-the-shelf LLMs and can be a lot sooner.
We choose the perfect hyperparameters utilizing an offline analysis the place we measure exact-match accuracy on a held-out subset of our interplay information. The precise-match accuracy is a 0-1 rating that measures whether or not our LLM can generate the mounted code y’ given the buggy code y and context x. Whereas it is a noisier metric than A/B testing, it could actually present a helpful sign for hyperparameter choice. We present offline analysis ends in Determine 4. Whereas the unique Llama fashions carry out considerably worse than GPT-4o fashions, our fine-tuned Llama mannequin performs the perfect total. Additional, whereas prompt-engineering by way of in-context studying (ICL) presents a considerable acquire, it’s nonetheless not as efficient as performing fine-tuning.
 Determine 4: Offline analysis with completely different LLMs. We use 5 examples for ICL. We report imply 0-1 exact-match accuracy primarily based on whether or not the generated repair matches the bottom reality repair. We normalize accuracies relative to GPT-4o accuracy.
Determine 4: Offline analysis with completely different LLMs. We use 5 examples for ICL. We report imply 0-1 exact-match accuracy primarily based on whether or not the generated repair matches the bottom reality repair. We normalize accuracies relative to GPT-4o accuracy.
Lastly, what does our Fast Repair Llama mannequin study? We give two examples under as an example the profit.
 Instance 1: Prediction with GPT-4o and QuickFix Llama mannequin. Actual desk names and constants had been redacted.
Instance 1: Prediction with GPT-4o and QuickFix Llama mannequin. Actual desk names and constants had been redacted.
Within the first instance, the GPT-4o agent incorrectly reworked the buggy SQL code into PySpark SQL, whereas the fine-tuned QuickFix Llama mannequin saved the unique code model. The GPT-4o edits could end in customers spending time reverting pointless diffs, thereby diminishing the advantage of a bugfix agent.
 Instance 2: Prediction with GPT-4o and QuickFix Llama mannequin. We don’t present the context for brevity however the context on this case comprises a column _partition_date for desk table2. Actual desk names and constants had been redacted.
Instance 2: Prediction with GPT-4o and QuickFix Llama mannequin. We don’t present the context for brevity however the context on this case comprises a column _partition_date for desk table2. Actual desk names and constants had been redacted.
Within the second instance, we discovered that the GPT-4o agent incorrectly changed the column date with _event_time by over-indexing on the trace given within the error message. Nonetheless, the correct edit is to make use of the column named _partition_date from the context which is what each the person and the QuickFix Llama does. The GPT-4o’s edits do look superficially appropriate, utilizing a time variable advised by the SQL engine. Nonetheless, the suggestion truly demonstrates an absence of domain-specific data which could be corrected by fine-tuning.
Conclusion
Organizations have particular coding wants which are finest dealt with by a customized LLM agent. We’ve discovered that fine-tuning LLMs can considerably enhance the standard of coding ideas, out-performing prompt-engineering approaches. Particularly, our fine-tuned small Llama 8B fashions had been sooner, cheaper, and extra correct than considerably bigger proprietary fashions. Lastly, coaching examples could be generated utilizing interplay information which is obtainable at no additional annotation price. We consider these findings generalize past this system restore activity as properly.
With Mosaic AI Mannequin Coaching, prospects can simply fine-tune fashions akin to Llama. You’ll be able to study extra about fine-tune and deploy open-source LLMs at Databricks right here. Desirous about a customized Fast Repair mannequin on your group? Attain out to your Databricks account group to study extra.
Acknowledgments: We thank Michael Piatek, Matt Samuels, Shant Hovsepian, Charles Gong, Ted Tomlinson, Phil Eichmann, Sean Owen, Andy Zhang, Beishao Cao, David Lin, Yi Liu, Sudarshan Seshadri for priceless recommendation, assist, and annotations.
References
- Automated program restore, Goues, et al., 2019. In Communications of the ACM 62.12 (2019): 56-65.
- Semfix: Program restore by way of semantic evaluation, Nguyen et al. 2013. Within the thirty fifth Worldwide Convention on Software program Engineering (ICSE). IEEE, 2013.
- Inferfix: Finish-to-end program restore with LLMs, Jin et al., 2023. In Proceedings of the thirty first ACM Joint European Software program Engineering Convention and Symposium on the Foundations of Software program Engineering.
- RepairAgent: An Autonomous, LLM-Primarily based Agent for Program Restore, Bouzenia et al., 2024. In arXiv https://arxiv.org/abs/2403.17134.
- Language fashions are few-shot learners, Brown et al. 2020. Within the Advances in Neural Data Processing Programs (NeurIPS).
- Robotically correcting massive language fashions: Surveying the panorama of various self-correction methods, Pan et al., 2024. In Transactions of the Affiliation for Computational Linguistics (TACL).
*Authors are listed in alphabetical order