{kind=link}

Information safety is a excessive precedence, significantly as organizations face growing cybersecurity threats. Sustaining the safety of buyer information is high precedence for AWS and Salesforce. With AWS PrivateLink, Salesforce Personal Join eliminates widespread safety dangers related to public endpoints. Salesforce Personal Join now works with Salesforce Information Cloud to maintain your buyer information safe when utilizing with key companies like Agentforce.
In Half 2 of this collection, we mentioned the structure and implementation particulars of cross-Area information sharing between Salesforce Information Cloud and AWS accounts. On this put up, we talk about the best way to create AWS endpoint companies to enhance information safety with Personal Join for Salesforce Information Cloud.
Resolution overview
On this instance, we configure PrivateLink for an Amazon Redshift occasion to allow direct, personal connectivity from Salesforce Information Cloud. AWS recommends that organizations use an Amazon Redshift managed VPC endpoint (powered by PrivateLink) to privately entry a Redshift cluster or serverless workgroup. For particulars about finest practices, check with Allow personal entry to Amazon Redshift out of your consumer purposes in one other VPC.
Nonetheless, some organizations may choose to make use of PrivateLink managed by themselves—for instance, a Redshift managed VPC endpoint just isn’t but obtainable in Salesforce Information Cloud, and you might want to handle your PrivateLink connection. This put up focuses on the answer to configure self-managed PrivateLink between Salesforce Information Cloud and Amazon Redshift in your AWS account to ascertain personal connectivity.
The next structure diagram exhibits the steps for organising personal connectivity between Salesforce Information Cloud and Amazon Redshift in your AWS account.

To arrange personal connectivity between Salesforce Information Cloud and Amazon Redshift, we use the next sources:
Conditions
To finish the steps on this put up, you have to have already got Amazon Redshift working in a non-public subnet and have the permissions to handle it.
Create a safety group for the Community Load Balancer
The safety group acts as a digital firewall. The one site visitors that reaches the occasion is the site visitors allowed by the safety group guidelines. To boost the safety posture, you solely need to enable site visitors to Redshift situations. Full the next steps to create a safety group on your Community Load Balancer (NLB):
- On the Amazon VPC console, select Safety teams within the navigation pane.
- Select Create safety group.
- Enter a reputation and outline for the safety group.
- For VPC, use the identical digital personal cloud (VPC) as your Redshift cluster.
- For Inbound guidelines, add a rule to permit site visitors to ingress the listening port 5439 on the load balancer.

- For Outbound guidelines, add a rule to permit site visitors to your Redshift occasion.

- Select Create safety group.
Create a goal group
Full the next steps to create a goal group:
- On the Amazon EC2 console, underneath Load balancing within the navigation pane, select Goal teams.
- Select Create goal group.
- For Select a goal kind, choose IP addresses.

- For Protocol: Port, select TCP and port 5436 (in case your Redshift cluster runs on a unique port, change the port accordingly).
- For IP handle kind, choose IPv4.
- For VPC, select the identical VPC as your Redshift cluster.
- Select Subsequent.
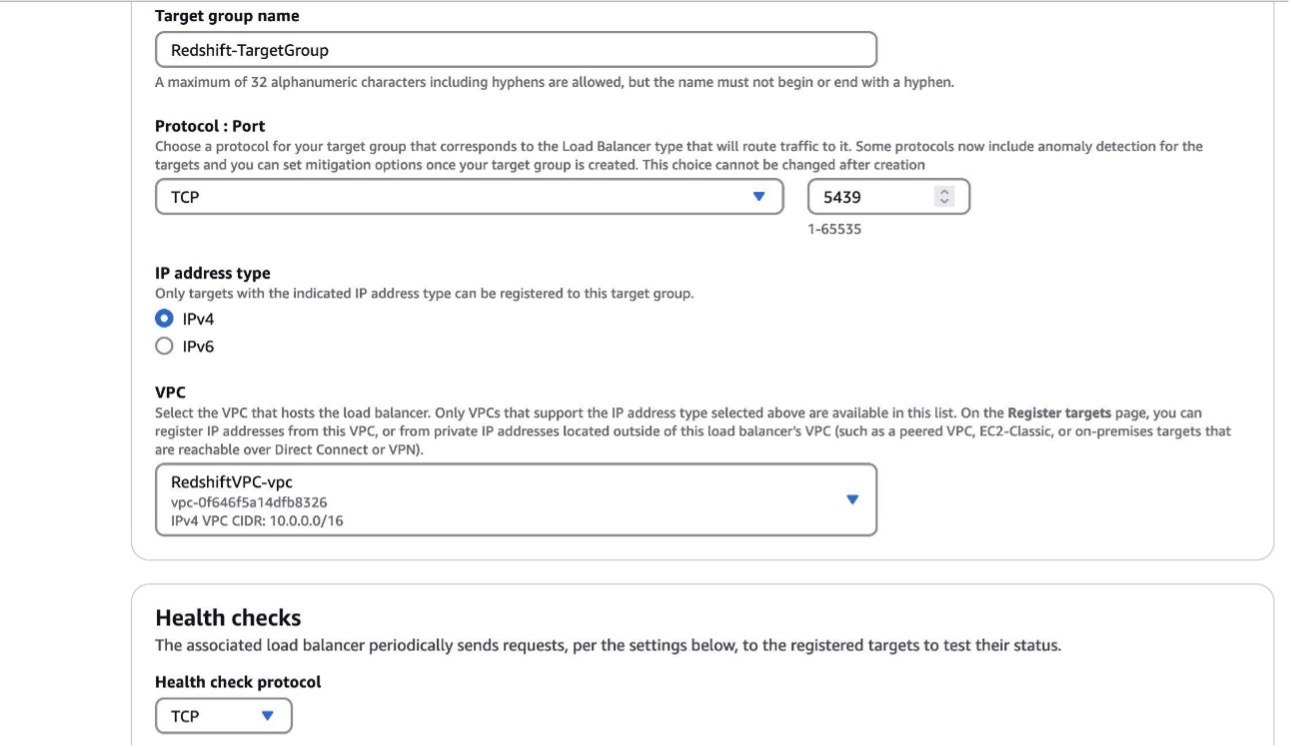
- For Enter an IPv4 handle from a VPC subnet, enter your Amazon Redshift IP handle.
To find this handle, navigate to your cluster particulars on the Amazon Redshift console, select the Properties tab, and underneath Community and safety settings, develop VPC endpoint connection particulars and duplicate the personal handle of the community interface. If you happen to’re utilizing Amazon Redshift Serverless, navigate to the workgroup house web page. The Amazon Redshift IPv4 addresses may be positioned within the Community and safety part underneath Information entry while you select VPC endpoint ID.

- After you add the IP handle, select Embody as pending beneath, then select Create goal group.

Create a load balancer
Full the next steps to create a load balancer:
- On the Amazon EC2 console, select Load balancers within the navigation pane.
- Select Create load balancer.
- Select Community.
- For Load balancer identify, enter a reputation.
- For Scheme, choose Inside.
- For Load balancer handle kind, choose IPv4.
- For VPC, use the VPC that your goal group is in.

- For Availably Zones, choose the Availability Zone the place the Redshift cluster is working.
- For Safety teams, select the safety group you created within the earlier step.
- For Listener particulars, add a listener that factors to the goal group created within the final step:
- For Protocol, select TCP.
- For Port, use 5439.
- For Default motion, select Redshift-TargetGroup.
- Select Create load balancer.


Ensure that the registered targets within the goal group are wholesome earlier than continuing. Additionally guarantee that the goal group has a goal for all Availability Zones in your AWS Area or the NLB has the Cross-zone load balancing attribute enabled.

Within the load balancer’s safety setting, guarantee that Implement inbound guidelines on PrivateLink site visitors is off.

Create an endpoint service
Full the next steps to create an endpoint service:
- On the Amazon VPC console, select Endpoint companies within the navigation pane.
- Select Create endpoint service.
- For Load balancer kind, select Community.
- For Accessible load balancers, choose the load balancer you created within the final step
- From Supported Areas, choose an extra area if Information Cloud isn’t hosted in the identical AWS area because the Redshift occasion. For added settings go away Acceptance required.
If that is chosen, later, when the Salesforce Information Cloud endpoint is created to connect with the endpoint service, you have to to return again to this web page to just accept the connection. If not chosen, the connection will likely be constructed immediately.
- For Supported IP handle kind, choose IPv4.
- Select Create.

Subsequent, you might want to enable Salesforce principals.
- After you create the endpoint service, select Enable principals.
- In one other browser, navigate to Salesforce Information Cloud Setup.
- Underneath Exterior Integrations, entry the brand new Personal Join menu merchandise.
- Create a brand new personal community path to Amazon Redshift.

- Copy the principal ID.

- Return to the endpoint service creation web page.
- For Principals so as to add, enter the principal ID.
- Copy the endpoint service identify.
- Select Enable principals.

- Return to the Salesforce Information Cloud personal community configuration web page.
- For Route Identify, enter the endpoint service identify.
- Select Save.

The route standing ought to present as Allocating.

If you happen to opted to just accept connections within the earlier step, you’ll now want to just accept the connection from Salesforce Information Cloud.
- On the Amazon VPC console, navigate to the endpoint service.
- On the Endpoint connections tab, find your pending connection request.

- Settle for the endpoint connection request from Salesforce Information Cloud.

Navigate to the Salesforce Information Cloud setup and wait 30 seconds, then refresh the personal join route so the standing exhibits as Prepared.

Now you can use this route when making a reference to Amazon Redshift. For added particulars, check with Half 1 of this collection.

Amazon Redshift federation PrivateLink failover
Now that we have now mentioned the best way to configure PrivateLink to make use of with Personal Join for Salesforce Information Cloud, let’s talk about Amazon Redshift federation PrivateLink failover situations.
You may select to deploy your Redshift clusters in three completely different deployment modes:
- Amazon Redshift provisioned in a Single-AZ RA3 cluster
- Amazon Redshift provisioned in a Multi-AZ RA3 cluster
- Amazon Redshift Serverless
PrivateLink depends on a buyer managed NLB related to service endpoints utilizing IP handle goal teams. The goal group has the IP addresses of your Redshift occasion. If there’s a change in IP handle targets, the NLB goal group have to be up to date to the brand new IP addresses related to the service. Failover conduct for Amazon Redshift will differ primarily based on the deployment mode you utilize.
This part describes PrivateLink failover situations for these three deployment modes.
Amazon Redshift provisioned in a Single-AZ RA3 cluster
RA3 nodes assist provisioned cluster VPC endpoints, which decouple the backend infrastructure from the cluster endpoint used for entry. If you create or restore an RA3 cluster, Amazon Redshift makes use of a port inside the ranges of 5431–5455 or 8191–8215. When the cluster is about to a port in one among these ranges, Amazon Redshift robotically creates a VPC endpoint in your AWS account for the cluster and attaches community interfaces with a non-public IP for every Availability Zone within the cluster. For the PrivateLink configuration, you utilize the IP related to the VPC endpoint because the goal for the frontend NLB. You may determine the IP handle of the VPC endpoint on the Amazon Redshift console or by doing a describe-clusters question on the Redshift cluster.


Amazon Redshift won’t take away a community interface related to a VPC endpoint except you add an extra subnet to an present Availability Zone or take away a subnet utilizing Amazon Redshift APIs. We suggest that you simply don’t add a number of subnets to an Availability Zone to keep away from disruption. There is likely to be failover situations the place extra community interfaces are added to a VPC endpoint.
In RA3 clusters, the nodes are robotically recovered and changed as wanted by Amazon Redshift. The cluster’s VPC endpoint won’t change even when the chief node is changed.
Cluster relocation is an non-obligatory function that permits Amazon Redshift to maneuver a cluster to a different Availability Zone with none lack of information or adjustments to your purposes. When cluster relocation is turned on, Amazon Redshift may select to relocate clusters in some conditions. Particularly, this occurs the place points within the present Availability Zone forestall optimum cluster operation or to enhance service availability. It’s also possible to invoke the relocation operate in instances the place useful resource constraints in a given Availability Zone are disrupting cluster operations. When a Redshift cluster is relocated to a brand new Availability Zone, the brand new cluster has the identical VPC endpoint however a brand new community interface is added within the new Availability Zone. The brand new personal handle must be added to the NLB’s goal group to optimize availability and efficiency.

Within the case {that a} cluster has failed and may’t be recovered robotically, you need to provoke a restore of the cluster from a earlier snapshot. This motion generates a brand new cluster with a brand new DNS identify, connection string, and VPC endpoint and IP handle for the cluster. You need to replace the NLB with the brand new IP for the VPC endpoint of the brand new cluster.
Amazon Redshift provisioned in a Multi-AZ RA3 cluster
Amazon Redshift helps Multi-AZ deployments for provisioned RA3 clusters. By utilizing Multi-AZ deployments, your Redshift information warehouse can proceed working in failure situations when an sudden occasion occurs in an Availability Zone. A Multi-AZ deployment deploys compute sources in two Availability Zones, and these compute sources may be accessed by way of a single endpoint. Within the case of a failure of the first nodes, Multi-AZ clusters will make secondary nodes major and deploy a brand new secondary stack in one other Availability Zone. The next diagram illustrates this structure.

Multi-AZ clusters deploy VPC endpoints that time to community interfaces in two Availability Zones, which must be configured as part of the NLB goal group. To configure the VPC endpoints within the NLB goal group, you may determine the IP addresses of the VPC endpoint utilizing the Amazon Redshift console or by doing a describe-clusters question on the Redshift cluster. In a failover state of affairs, VPC endpoint IPs won’t change and the NLB doesn’t require an replace.
Amazon Redshift won’t take away a community interface related to a VPC endpoint except you add an extra subnet in to an present Availability Zone or take away a subnet utilizing Amazon Redshift APIs. We suggest that you simply don’t add a number of subnets to an Availability Zone to keep away from disruption.

Amazon Redshift Serverless
Redshift Serverless gives managed infrastructure. You may carry out the get-workgroup question to get the workgroup’s VpcEndpoint IPs. IPs must be configured within the goal group of the PrivateLink NLB. As a result of it is a managed service, the failover is managed by AWS. In the course of the occasion of an underlying Availability Zone failure, the workgroup may get a brand new set of IPs. You may incessantly question the workgroup configuration or DNS document for the Redshift cluster to examine if IP addresses have modified and replace the NLB accordingly.

Automating IP handle administration
In situations the place Amazon Redshift operations may change the IP handle of the endpoint wanted for Amazon Redshift connectivity, you may automate the replace of NLB community targets by monitoring the outcomes for cluster DNS decision, utilizing describe-cluster or get-workgroup queries, and utilizing an AWS Lambda operate to replace the NLB goal group configuration.
You may periodically (on a schedule) question the DNS of the Redshift cluster for IP handle decision. Use a Lambda operate to check and replace the IP goal teams for the NLB. For an instance of this resolution, see Hostname-as-Goal for Community Load Balancers.
For legacy DS2 clusters the place the IP handle of the chief node have to be explicitly monitored, you may configure Amazon CloudWatch metrics to observe the HealthStatus of the chief node. You may configure the metric to set off an alarm, which alerts an Amazon Easy Notification Service (Amazon SNS) matter and invokes a Lambda operate to reconcile the NLB goal group.
For backup and restore patterns, you may create a rule in Amazon EventBridge triggered on the RestoreFromClusterSnapshot API motion, which invokes a Lambda operate to replace the NLB with the brand new IP addresses of the cluster.
For a cluster relocation sample, you may set off an occasion primarily based on the Amazon Redshift ModifyCluster availability-zone-relocation API motion.
Conclusion
On this put up, we mentioned the best way to use AWS endpoint companies to enhance information safety with Personal Join for Salesforce Information Cloud. If you’re presently utilizing the Salesforce Information Cloud zero-copy integration with Amazon Redshift, we suggest you observe the steps supplied on this put up to make the community connection between Salesforce and AWS safe. Attain out to your Salesforce and AWS assist groups for those who want extra assist to implement this resolution.
In regards to the authors
 Yogesh Dhimate is a Sr. Companion Options Architect at AWS, main expertise partnership with Salesforce. Previous to becoming a member of AWS, Yogesh labored with main corporations together with Salesforce driving their business resolution initiatives. With over 20 years of expertise in product administration and options structure Yogesh brings distinctive perspective in cloud computing and synthetic intelligence.
Yogesh Dhimate is a Sr. Companion Options Architect at AWS, main expertise partnership with Salesforce. Previous to becoming a member of AWS, Yogesh labored with main corporations together with Salesforce driving their business resolution initiatives. With over 20 years of expertise in product administration and options structure Yogesh brings distinctive perspective in cloud computing and synthetic intelligence.
 Avijit Goswami is a Principal Options Architect at AWS specialised in information and analytics. He helps AWS strategic clients in constructing high-performing, safe, and scalable information lake options on AWS utilizing AWS managed companies and open supply options. Outdoors of his work, Avijit likes to journey, hike, watch sports activities, and take heed to music.
Avijit Goswami is a Principal Options Architect at AWS specialised in information and analytics. He helps AWS strategic clients in constructing high-performing, safe, and scalable information lake options on AWS utilizing AWS managed companies and open supply options. Outdoors of his work, Avijit likes to journey, hike, watch sports activities, and take heed to music.
 Ife Stewart is a Principal Options Architect within the Strategic ISV phase at AWS. She has been engaged with Salesforce Information Cloud during the last 2 years to assist construct built-in buyer experiences throughout Salesforce and AWS. Ife has over 10 years of expertise in expertise. She is an advocate for range and inclusion within the expertise area.
Ife Stewart is a Principal Options Architect within the Strategic ISV phase at AWS. She has been engaged with Salesforce Information Cloud during the last 2 years to assist construct built-in buyer experiences throughout Salesforce and AWS. Ife has over 10 years of expertise in expertise. She is an advocate for range and inclusion within the expertise area.
 Mike Patterson is a Senior Buyer Options Supervisor within the Strategic ISV phase at AWS. He has partnered with Salesforce Information Cloud to align enterprise targets with modern AWS options to realize impactful buyer experiences. In his spare time, he enjoys spending time along with his household, sports activities, and out of doors actions.
Mike Patterson is a Senior Buyer Options Supervisor within the Strategic ISV phase at AWS. He has partnered with Salesforce Information Cloud to align enterprise targets with modern AWS options to realize impactful buyer experiences. In his spare time, he enjoys spending time along with his household, sports activities, and out of doors actions.
 Drew Loika is a Director of Product Administration at Salesforce and has spent over 15 years delivering buyer worth by way of information platforms and companies. When not diving deep with clients on what would assist them be extra profitable, he enjoys the acts of constructing, rising, and exploring the nice open air.
Drew Loika is a Director of Product Administration at Salesforce and has spent over 15 years delivering buyer worth by way of information platforms and companies. When not diving deep with clients on what would assist them be extra profitable, he enjoys the acts of constructing, rising, and exploring the nice open air.