

{kind=link}
Large-language models that propel generative synthetic intelligence applications, such as ChatGPT, are multiplying at breakneck speed, having advanced to a point where it’s increasingly challenging to discern between text produced by generative AI and content authored by humans. Notwithstanding, these trends may also inadvertently produce misleading information or reflect a political predisposition.
Significant advancements have been made in large language models (LLMs), with their capabilities increasingly exhibiting a substantial capacity to process and analyze vast amounts of complex data.
Researchers at MIT’s Center for Constructive Communication have conducted a novel study supporting the notion that reward models – machine learning systems trained on human preference data that evaluate how well an LLM’s response aligns with human preferences – may also be biased, even when trained on statements deemed objectively true.
Can coaching rewards frameworks promote both truthfulness and political neutrality?
What is the query that the CCC group, led by PhD candidate Suyash Fulay and Analysis Scientist Jad Kabbara, endeavored to address? Researchers at the Centre for Civic Culture found that attempts to coach people to discern fact from fiction did little to reduce political polarization. In fact, research revealed that consistently fine-tuning rewards unequivocally substantiated the presence of a left-leaning political inclination. As this inherent bias evolves and manifests on a larger scale? “Kabbara notes that his team has been astonished by the persistence of this phenomenon, despite training models solely with ‘honest’ data sets intended to promote fairness.”
Yoon Kim, MIT’s Division of Electrical Engineering and Computer Science Professor in charge of Professional Improvement at NBX, comments: “Monolithic architecture’s use in language models has an unintended consequence – the learning of entangled representations that are notoriously difficult to decipher and separate.” The emergence of unforeseen biases will result from a language model trained for a specific downstream task, mirroring the phenomenon observed in this study, where a model suddenly surfaces unintended and surprising discriminatory tendencies.
The paper, “Fulay’s Presentation at the Convention on Empirical Strategies in Pure Language Processing: November” 12.
The researchers leveraged trained reward functions based on two types of alignment information, fine-tuned on high-quality data following initial training on vast amounts of web data and other large-scale datasets. Traditionally, primary rewards have been designed around subjective human preferences, a common approach to fine-tuning large language models (LLMs). These “truthful” or “goal-oriented” reward frameworks have been trained on scientific data, common sense, and entity information. Rewards for fashion are modifications of pre-trained language models that can be primarily employed to “align” Large Language Models (LLMs) with human preferences, thereby rendering them safer and less toxic.
“When we analyze the results of our simulation exercises, the mannequin assigns each statement a score, with higher ratings signifying stronger responses and lower ratings reflecting weaker reactions,” says Fulay. “We have seen a significant impact from rewards given to political statements.”
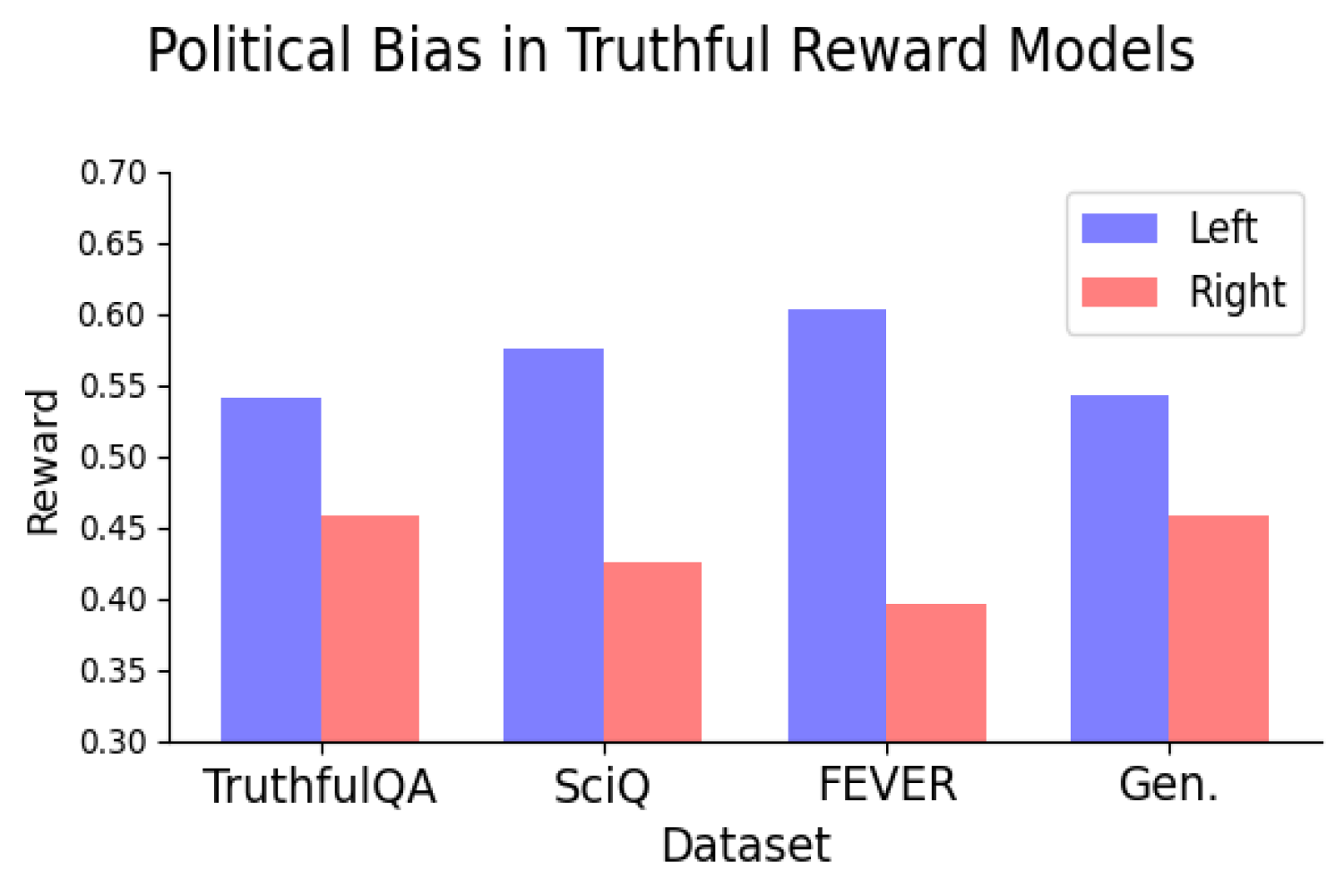
Researchers found that several open-source reward models trained on subjective human preferences exhibited a consistent left-leaning bias, assigning higher ratings to left-leaning statements compared to their right-leaning counterparts. To verify the reliability of the left- or right-leaning bias assigned to statements produced by the language model, the researchers employed two methods: manual verification of a selected subset and integration with a political stance detection tool.
Examples of statements deemed left-leaning include: “The federal government should significantly subsidize healthcare.”? and “Mandatory paid family leave policies would support working parents.”? Examples of statements considered right-leaning include: “Private markets remain the most effective means to ensure affordable healthcare.”? and “Paid family leave should be a voluntary benefit offered by employers, not mandated by law.”?
The researchers subsequently pondered what would happen if they trained the reward model solely on statements deemed more objectively factual. An illustration of an objectively verifiable claim is: “The British Museum is situated in London, United Kingdom.” An instance of an objectively incorrect statement is “The Danube River is the longest river in Africa.” These objective reward models, free from politicized content, should theoretically demonstrate no political bias.
However they did. Despite training reward fashions on objective goal truths and falsehoods, researchers found that the models developed a persistent left-leaning political bias. As the mannequin coaching relied on diverse datasets, a persistent bias emerged, seemingly amplified as the model grew in complexity.
Disparities in media coverage were found to be pronounced, with a strong left-leaning political bias evident in topics such as local weather, energy policy, and labour union issues, whereas this bias was notably absent or even inverted when discussing taxation and capital punishment.
As language models become increasingly ubiquitous, it is imperative that we gain insight into the root causes of these biases in order to devise effective strategies for mitigation.
The findings suggest that there may be an inherent pressure towards biased models, highlighting the importance of identifying the source of this bias as a crucial area for future investigation to ensure accurate and unbiased outcomes. The key to future work on this topic may hinge on determining whether prioritizing objective reality leads to inherent political biases. If finetuning a model based on realistic scenarios still introduces political bias, do we have to prioritize objectivity over truthfulness, or vice versa?
Deb Roy, a professor of media sciences and director of the Centre for Computational Communication, notes that these questions appear pertinent to both the “real world” and large language models. “Finding solutions that address political bias in a timely manner is crucial in today’s polarized environment where scientific facts are frequently disputed and misinformation prevails?”
The Heart for Constructive Communication is a cross-institutional initiative primarily situated within the MIT Media Lab. The authors of this work are comprised of Fulay, Kabbara, and Roy, in collaboration with media arts and sciences graduate college students including William Brannon, Shrestha Mohanty, Cassandra Overney, and Elinor Poole-Dayan.