{kind=link}

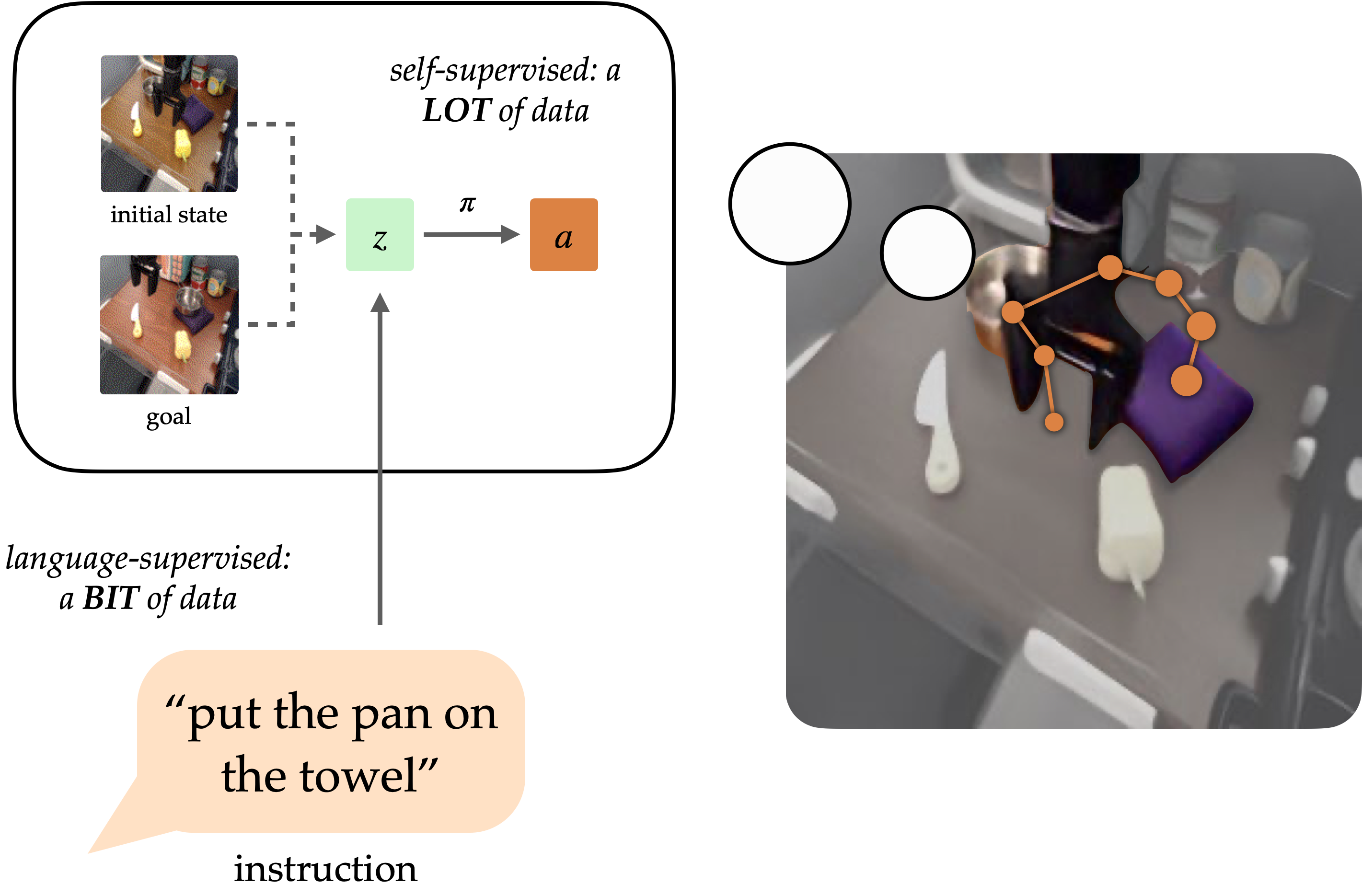
The primary objective of robotics research has long been to develop versatile robots capable of performing tasks on behalf of humans. While natural language holds promise as a user-friendly means of specifying tasks, it proves challenging to train robots to accurately follow linguistic instructions. While approaches such as language-conditioned behavioral cloning (LCBC) enable the immediate imitation of professional actions based on language inputs, they rely heavily on annotated coaching trajectories and struggle with generalization across diverse scenes and behaviors. While goal-conditioned methods excel in fundamental manipulation tasks, they still fall short in accommodating straightforward task definitions for human operators. Can we strike a balance between streamlining task assignments through LCBC-inspired methods and leveraging goal-conditioned learning’s productivity gains?
To function effectively, a robot that follows instructions requires the dual capacities of comprehension and execution. To effectively implement linguistic instructions within a physical context, one must first establish a clear understanding of the task at hand and then execute a series of deliberate actions to accomplish the intended goal. While these capabilities cannot be solely identified through human-annotated trajectories, they can instead be discerned independently from relevant data sources. Natural language insights gleaned from diverse human sources can significantly facilitate research into language grounding, allowing for the development of generalized frameworks that can be applied across multiple domains and visual contexts. In the interim, unlabelled robotic trajectories can be leveraged to train a robot to achieve specific goal states, regardless of whether those goals are unrelated to linguistic directives.
Conditioning on visible targets (i.e. Utilizing purposeful pictures provides supplementary benefits for comprehensive learning. As a framework for job specifications, targets are intriguing due to their propensity to evolve through hindsight relabeling (any point on a path can serve as a target). This approach enables the skillful reproduction of insurance policies through goal-conditioned behavioral cloning, leveraging massive amounts of unlabelled and unstructured trajectory data, as well as autonomous collection by the robotic system itself. Objectives are even more easily verifiable, as visual representations allow for direct pixel-to-pixel comparison with alternative states.
Despite this, targets are often far less accessible and user-friendly for human clients when compared to natural language. It’s often easier for customers to describe the task required than to provide a detailed description that would essentially necessitate performing the task anyway. By providing a language interface for goal-conditioned insurance policies, we enable the combination of strengths from both goal-oriented and language-based task specifications, thereby empowering generalist robots that can be easily instructed.
Our technique, described below, enables generalization to diverse directions and scenarios by leveraging vision-language fusion, thereby amplifying its physical capabilities through processing vast, unstructured datasets from robotic systems.
Purpose Representations for Instruction Following
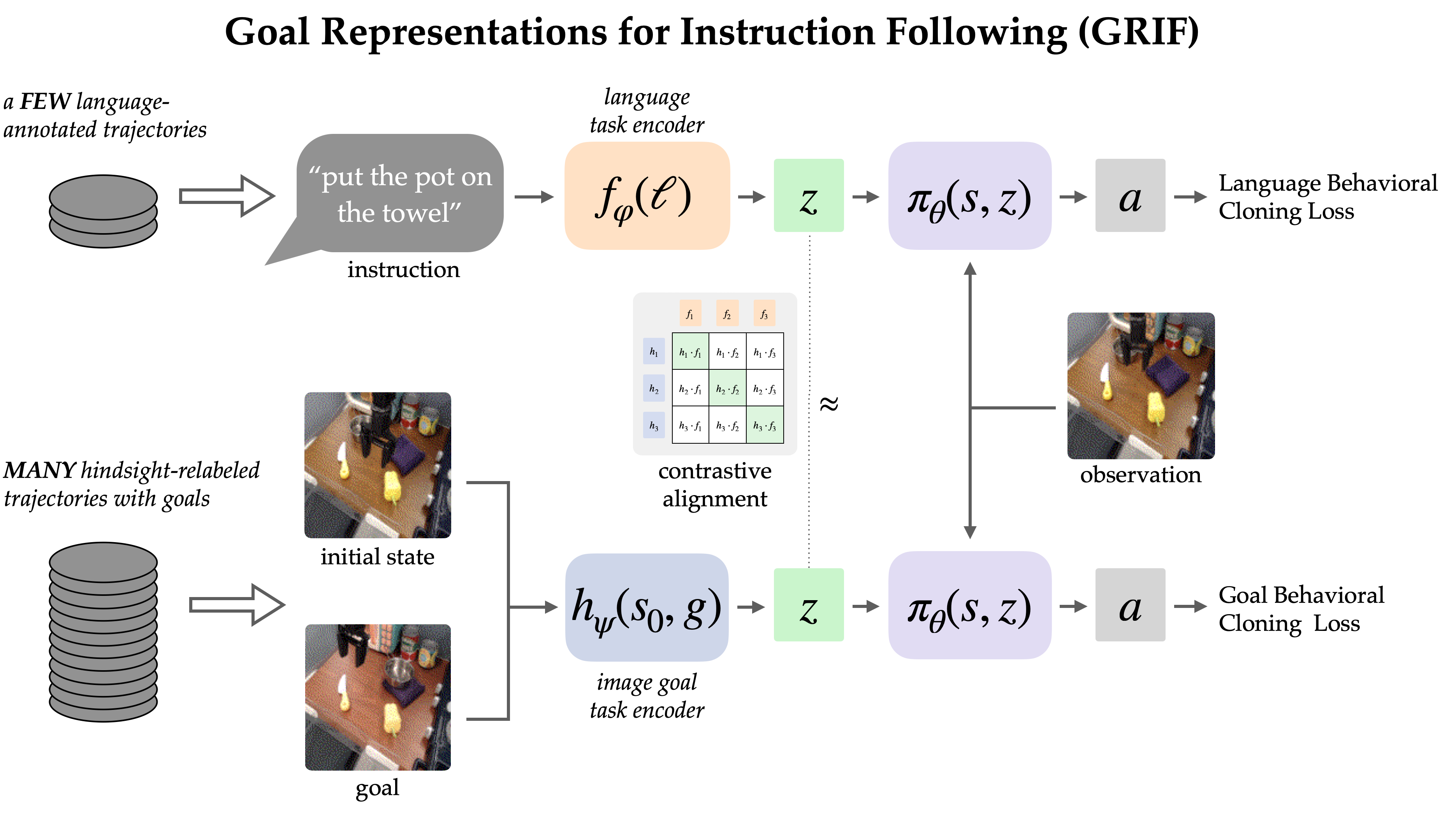
The GRIF mannequin comprises a language encoder, a purpose encoder, and a coverage network. The encoders effectively translate linguistic directions and pictorial representations into a common task depiction space, thereby enabling the prediction of actions by the coverage community. The mannequin can effectively condition itself on both linguistic directions or visual images to predict actions; nonetheless, we are predominantly employing goal-conditioned training as a means to bolster the language-conditioned use case.
Our method, Representations of Purpose for Instructional Following (RIPF)?Collectively trains a language-conditioned and goal-conditioned coverage model that aligns job representations to optimize task performance. Our primary understanding is that these representations, harmoniously integrated across language and purpose modalities, enable a seamless fusion of the benefits from goal-conditioned learning and language-conditioned coverage. Discovered insurance policies demonstrate the ability to generalise across languages and scenarios following training on extensive, unlabeled dataset demonstrations.
We trained our GRIF model on a dataset consisting of 7,000 labeled demonstration trajectories and 47,000 unlabeled ones within a kitchen manipulation setting. The dataset’s lack of manual annotation for its 47,000-plus trajectories posed a significant challenge, as human reviewers were required to label each one individually.
To effectively study from diverse sources of information, the General Reinforcement and Intrinsic Feedback (GRIF) framework is expertly combined with two specialized approaches: language-conditioned behavioral cloning (LCBC) and goal-conditioned behavioral cloning (GCBC). The labelled dataset seamlessly integrates language-specific and purpose-driven job descriptions, allowing us to monitor each language-and-goal-conditioned prediction with precision. LCBC and GCBC). The unlabeled dataset solely consists of targets and is utilized specifically for Generalized Cross-Entropy Based Clustering (GCBC). While seemingly subtle nuances exist between LCBC and GCBC, the primary difference lies in selecting the applicable duty scenario from an encoder, which then feeds into a shared prediction framework for anticipating actions.
By leveraging the collective expertise of the coverage community, we can anticipate a notable enhancement in performance when applying the unlabeled dataset for goal-conditioned training. Notwithstanding GRIF allows for a seamless transition between the two modalities by acknowledging that certain linguistic directions and visual cues prescribe the same behavior. We leverages this construct by stipulating that linguistic and objective representations are semantically aligned for analogous tasks. Unlabelled data’s inclusion may enhance language-specific coverage since the absence of explicit guidance can be compensated for by the purpose illustration’s approximate function.
Alignment via Contrastive Studying
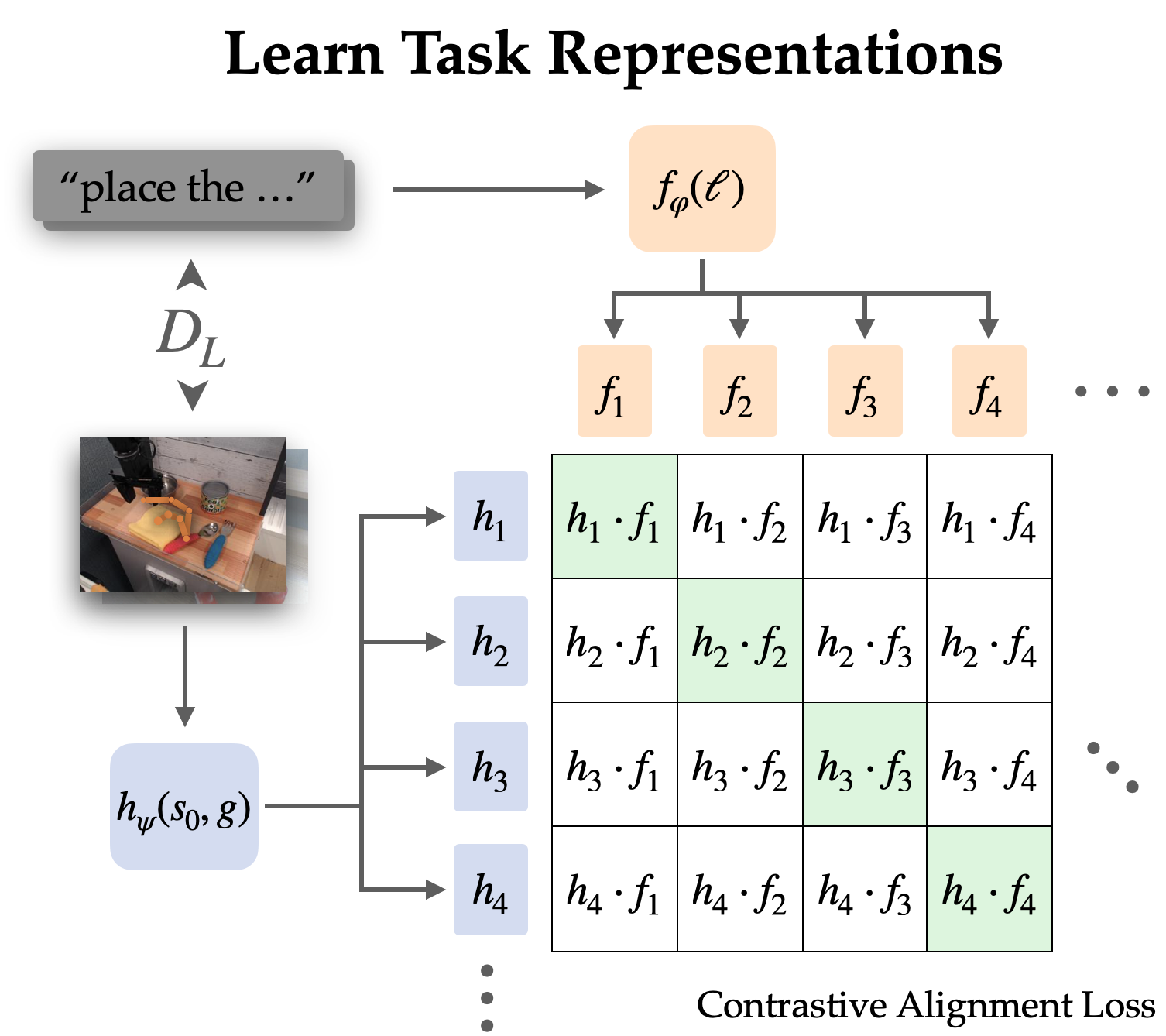
We explicitly align representations between goal-conditioned and language-conditioned tasks on a labelled dataset through contrastive learning.
As linguistic frameworks typically capture nuanced changes, we opt to harmonize state-goal pair representations with linguistic cues, rather than solely relying on purpose-driven language. By empirically reducing complexity, these simplified representations eliminate extraneous information in images, focusing solely on transformative changes between states.
We examine this alignment construction through a information-negative log-likelihood (infoNCE) objective using directions and images from our labelled data set. We develop twin encoders for visual and textual content by employing contrastive learning on paired sets of image and language representations. The target incentivizes excessive sameness among identical tasks’ portrayals, while fostering little similarity with other roles; notably, negative exemplars stem from distinct career paths.
Utilizing naive detrimental sampling – selecting uniformly from the dataset’s remainder – often results in discovered representations that overlook the specific task, instead aligning with general directions and targets referencing identical scenes. To effectively utilize linguistic nuances in real-world applications, it’s more productive to decouple language from a specific scene; instead, we need to clarify distinct roles within that same scene. To mitigate this issue, we employ an aggressive sampling strategy, wherein up to half of the negative samples originate from distinct trajectories within the same scene.
Intrinsically, this contrasting study design piques the interest of pre-trained vision-language models such as CLIP, inviting further exploration. They demonstrate exceptional zero-shot and few-shot generalisation capabilities for vision-language tasks, offering a solution to seamlessly integrate data from large-scale pre-training initiatives on the internet. Despite this, most vision-language frameworks are typically designed to match a solitary static image with its description without the capability to comprehend changes within the environment, and as such, they struggle when tasked with focusing on a single object amidst cluttered settings.
To effectively address these issues, we develop a mechanism to adapt and refine the Job Representation module within CLIP, ensuring accurate alignment. We adapt the CLIP architecture to accommodate input pairs comprising early-fusion representations, obtained by stacking and concatenating channels. The proposed approach appears to successfully initialize the process of encoding paired state and purpose images, with the notable strength of retaining pre-trained benefits from CLIP effectively.
Robotic Coverage Outcomes
We analyze the actual-world application of the GRIF framework across three scenarios, examining its effectiveness in fulfilling 15 distinct responsibilities. Directions are selected as a blend of those already represented within the coaching material and new ones requiring extrapolation from existing knowledge. This unusual amalgamation of disparate items presents a captivating tableau.
We compare our approach, GRIF, to a straightforward linear classification baseline (LCBC) and strengthen results with robust baselines inspired by prior research. The LLfP team collaborates with both the Local Learning and Cultural Behavioural Change (LCBC) and Global Coaching and Behavioural Change (GCBC) entities in a collective coaching capacity.
The BC-Z technique has been adapted to our specific context, namely the preparation area within LCBC, GCBC, and the relatively straightforward alignment timeframe. The algorithm streamlines the calculation of cosine distance losses between duty representations without relying on image-language pre-training methods.
Two primary weaknesses in the insurance policies have been identified. As a result, they are likely to struggle with understanding the language instructions, ultimately attempting alternative occupations or rendering no useful contributions whatsoever. When language grounding is tenuous, insurance policies may inadvertently initiate a new task after completing the intended one, as the original instruction becomes dislodged from its context.
Examples of grounding failures

Cultivate the fungus in a metal container.

Put the spoon on the towel.

Add the sliced yellow bell pepper to the arrangement.

Place the yellow bell pepper on the tablecloth.
The most likely opposite failure mode is failing to govern objects. This might be due to a lack of coordination, unstable control, or dropping objects at the wrong moment. While acknowledging that some limitations may arise from the robotic setup, we recognize that a skilled GCBC coverage expert can still consistently achieve optimal manipulation. However, this failure mode typically indicates a lack of effective utilization of goal-conditioned knowledge.
Examples of manipulation failures

Transfer the bell pepper to the area directly to your left.

Add the sliced bell pepper to the pan.

Dry the dish after the microwave.
While evaluating the baselines, each suffered from two distinct failure modes to varying degrees. Despite its reliance on a limited labelled trajectory dataset, LCBC’s inadequate manipulation capabilities hinder its ability to complete tasks efficiently. Large-scale language models like LLfP collectively train their coverage on both labeled and unlabeled information, thereby revealing a substantial improvement in their manipulation capabilities through Large-scale Language Constrained Beam Search Optimization (LCBC). It yields cost-effective success rates for straightforward scenarios, but struggles to deliver on more complex instructions. BC-Z’s alignment technique further enhances manipulation capabilities likely due to the optimized transition between modalities. Despite lacking external vision-language information sources, the system still faces challenges in generalizing to novel directions.
The GRIF excels at generating insightful generalizations while simultaneously boasting impressive manipulation abilities. Are prepared to execute linguistic instructions effectively, handling multiple tasks seamlessly within a given scenario. Below are presented several rollouts accompanied by their respective directions.
Coverage Rollouts from GRIF

Transfer the pan to the entrance of the oven.

Add the sliced bell pepper to the pan.

Put the knife onto the purple fabric.

Put the spoon onto the towel.
Conclusion
The General Reinforcement Insurance Framework (GRIF) enables robots to effectively process massive amounts of unlabeled trajectory data, enabling the analysis of goal-conditioned insurance policies and providing a “language interface” to these policies via aligned language-goal task representations. Noting a departure from traditional approaches to linking visual and linguistic inputs, our methodology synchronizes shifts in state with language, yielding significant improvements over conventional CLIP-based image-language correspondence methods. Our studies demonstrate that our approach effectively capitalizes on unlabeled robotic trajectories, yielding substantial boosts in efficiency compared to benchmarks and methods solely reliant on language-annotated data.
While our current approach exhibits several limitations, it’s likely that future advancements will effectively mitigate these constraints. GRIF is ill-equipped to handle tasks where detailed procedural instructions predominate over task objectives, such as “pour the water slowly” directives – these nuanced guidelines necessitate alternative alignment loss calculations that consider the intermediate actions involved in completing the duty. GRIF further posits that all linguistic knowledge stems directly from the fully annotated portions of our dataset or those leveraged from pre-trained vision-language models. Here is the rewritten text:
“A potential game-changer in future work could be to amplify our alignment loss, unlocking the full potential of human-in-the-loop video analysis and extracting rich semantic insights from vast amounts of web-scaled data.”
A method could leverage this data to improve grounding in natural language outside the robotic dataset, enabling broad, generalizable robotic policies that can respond to user instructions effectively.
The study upon which this publication is based:
If you are referencing a publication that has been previously cited in our study (GRIF), kindly provide the corresponding reference by typing:
@inproceedings{myers2023goal, author={Vivek Myers and Andre He and Kuan Fang and Homer Walke and Philippe Hansen-Estruch and Ching-An Cheng and Mihai Jalobeanu and Andrey Kolobov and Anca Dragan and Sergey Levine}, title={Purpose Representations for Instruction Following: A Semi-Supervised Language Interface to Management}, booktitle={Proceedings of the Convention on Robotic Learning}, year={2023}}