{kind=link}

As the cornerstone of the Databricks Information Intelligence Platform, Spark serves as the foundation for workloads across hundreds of organizations globally. To further enhance its offering, Databricks is committed to investing in the development of Workflows, ensuring they remain aligned with the rapidly changing demands of modern data science and AI projects.
Last summer, we hosted our most extensive event yet, where we showcased several pioneering features and improvements in Databricks Workflows. The latest innovations unveiled at the Information + AI Summit incorporate advanced data-driven triggers, intelligent workflow automation, and improved SQL connectivity, designed to amplify dependability, flexibility, and user-friendliness. Additionally, we introduced infrastructure-as-code tools such as PyDABs and Terraform to streamline automation, and secured the final availability of serverless compute for workflows, thereby ensuring seamless, scalable orchestration. Looking ahead to 2024, we can expect even more advancements, including enhanced management circulation options, improved trigger mechanisms, and the maturation of Workflows into LakeFlow Jobs as part of our newly unified LakeFlow solution.
In this blog post, we’ll recap our previous updates, explore what’s next for Workflows, and provide guidance on how to start harnessing its potential right away.
What’s New in Databricks Workflow Innovations?
The past year has been a game-changer for Databricks Workflows, with over 70 new features launched to significantly enhance our orchestration capabilities. Below are the primary takeaways:
Information-Driven Triggers: Precision at Your Fingertips
- Conventional time-based scheduling may not be sufficient to guarantee information timeliness while minimizing unnecessary executions. Our data-driven triggers ensure that job initiation occurs precisely as new information becomes available. We’ll review whether tables display the latest available data in preview, or if fresh insights have emerged elsewhere, then seamlessly spin up compute and workload capacity whenever needed. This implementation guarantees that individuals consume sources primarily when crucial, thereby maximizing value, efficiency, and the timeliness of the information. To enhance file arrival triggers, we have eliminated previous restrictions on the number of data Workflows can track.
- Allow you to schedule jobs to run at regular intervals, such as daily or weekly, without the need to manage complex cron schedules.
Intelligent workflows: AI amplifies human expertise at every turn.
- Scheduling jobs can prove to be a challenging task, especially when the task involves deciphering complex cron syntax. The tool simplifies the process by generating proper Cron syntax from natural-language inputs, ensuring accessibility for users of all skill levels.
- The Databricks Assistant can now be seamlessly integrated into Workflows, available for immediate use in preview. When unforeseen errors occur during job processing, it provides real-time support. When encountering issues such as a failed data lake or incorrectly arranged jobs, Databricks Assistant promptly offers specific, actionable guidance to quickly identify and resolve the problem.
Workflow Administration at Scale
- As information workflows grow increasingly complex, the need for scalable orchestration becomes paramount. Databricks Workflows has been enhanced to support up to 1,000 tasks within a single job, streamlining the management of complex data pipelines and simplifying the orchestration of large-scale analytics projects.
- Customers can now simplify their workflow management by filtering jobs according to favorite tags assigned to each job. By utilizing a straightforward and intuitive interface, users can quickly locate specific job openings, for instance, Among team members designated as “Monetary Analysts”.
- The UI now offers advanced auto-completion for job values, simplifying the process of switching between tasks without manual entry errors or tedious typing.
- Detailed descriptions facilitate precise documentation of workflows, ensuring teams can quickly comprehend and troubleshoot tasks.
- To enhance scalability and reduce costs, we’ve updated the default settings for job clusters, ensuring seamless transitions from interactive development to scheduled execution.
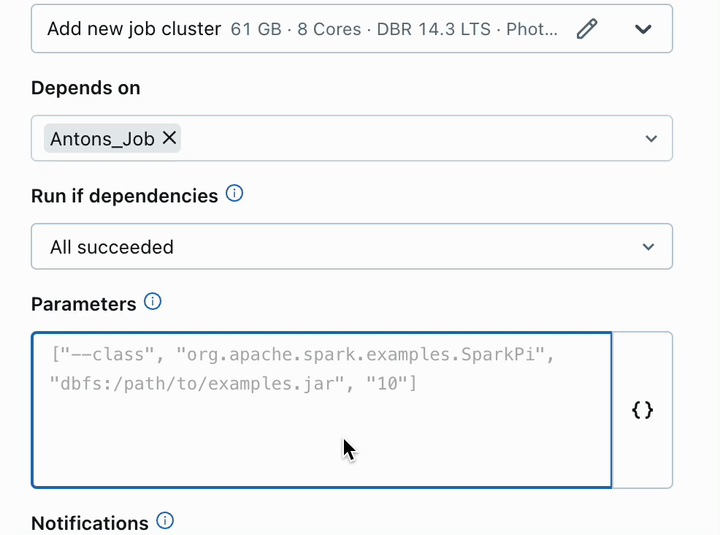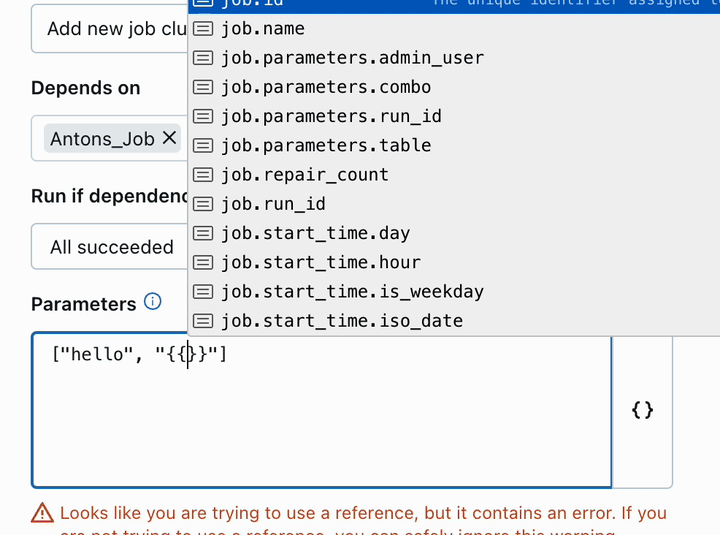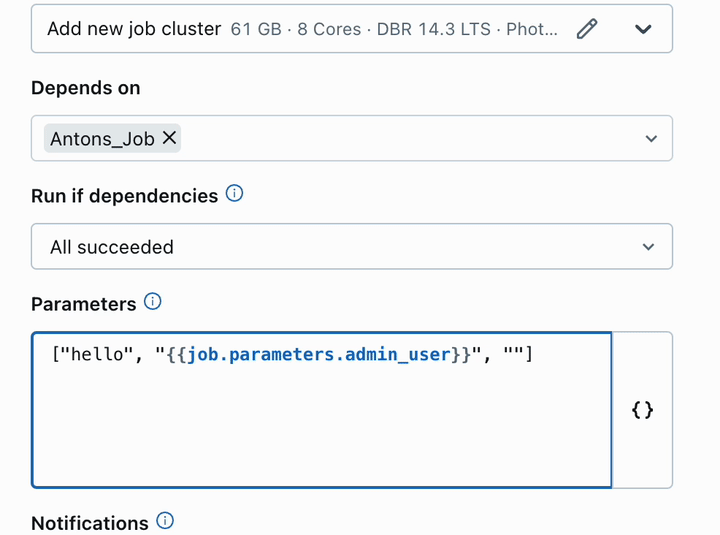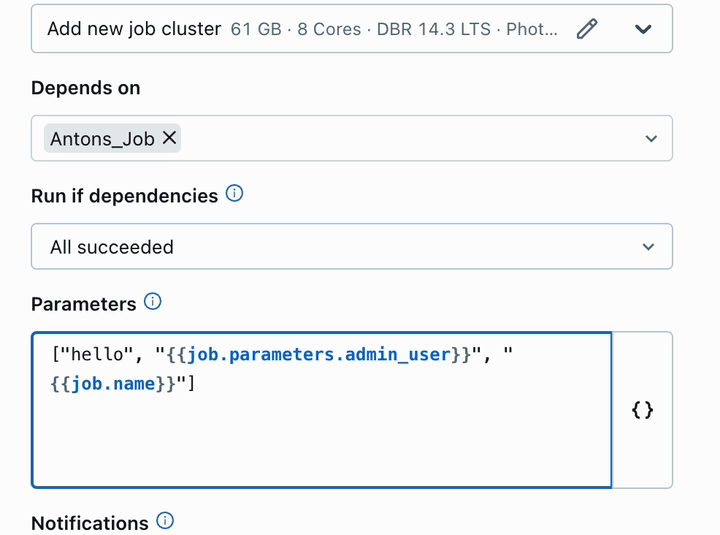
Operational Effectiveness: Unlocking Efficiency and Value through Strategic Alignment.
- The innovative timeline view within Workflows now features enhanced insights, offering a comprehensive overview of job performance metrics, empowering users to identify areas of inefficiency and refine their workflows for maximum speed and cost optimization.
- Understanding the price implications of your workflows is crucial for effectively managing budgets and optimising resource utilisation. With the introduction of system tables for Workflows, users can now track prices linked to each job over time, identify trends, and uncover opportunities for cost-effective improvements. We’ve also built dashboards on top of system tables that you can easily customize. Here are some potential responses that could help users reply to such questions: It’s also possible to access these.
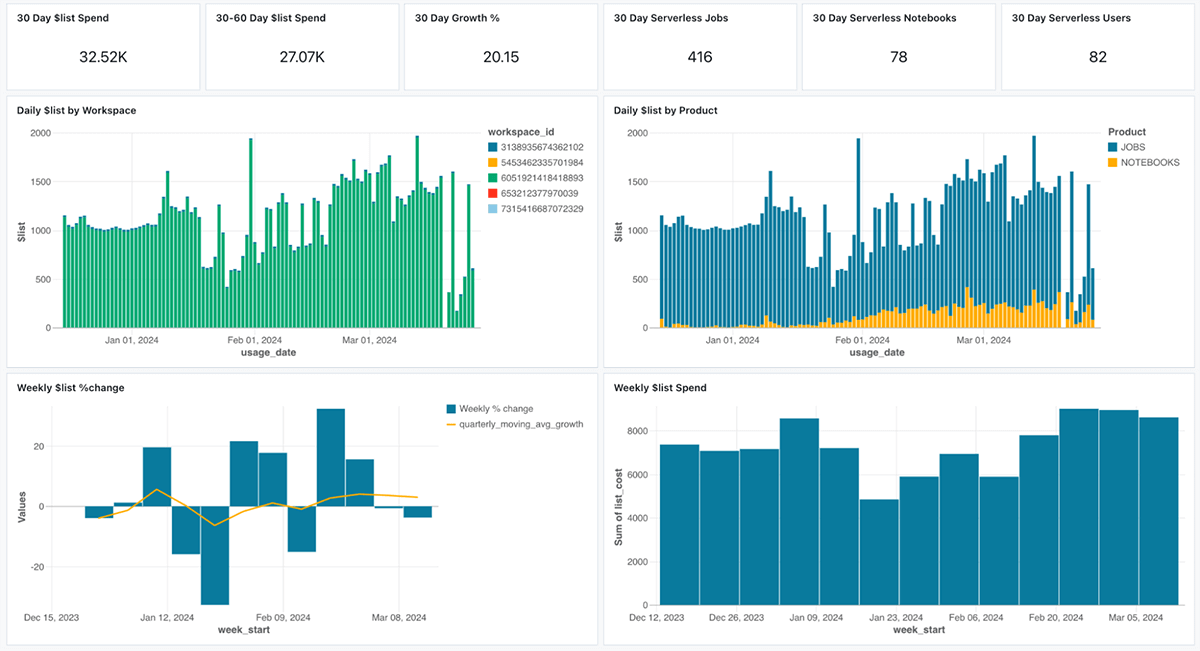
What’s New in Enhanced SQL Integration?
- SQL professionals can now capitalize on the results of one SQL job for subsequent tasks. This innovative function enables real-time workflow adaptability, allowing subsequent questions’ outputs to directly impact the logic governing their processing, thereby simplifying complex information transformations seamlessly.
- By enabling the execution of multiple SQL statements within a single workflow, Databricks Workflows offers enhanced flexibility when designing SQL-driven data pipelines. This integration enables seamless information processing, eliminating the need to switch between contexts or tools.
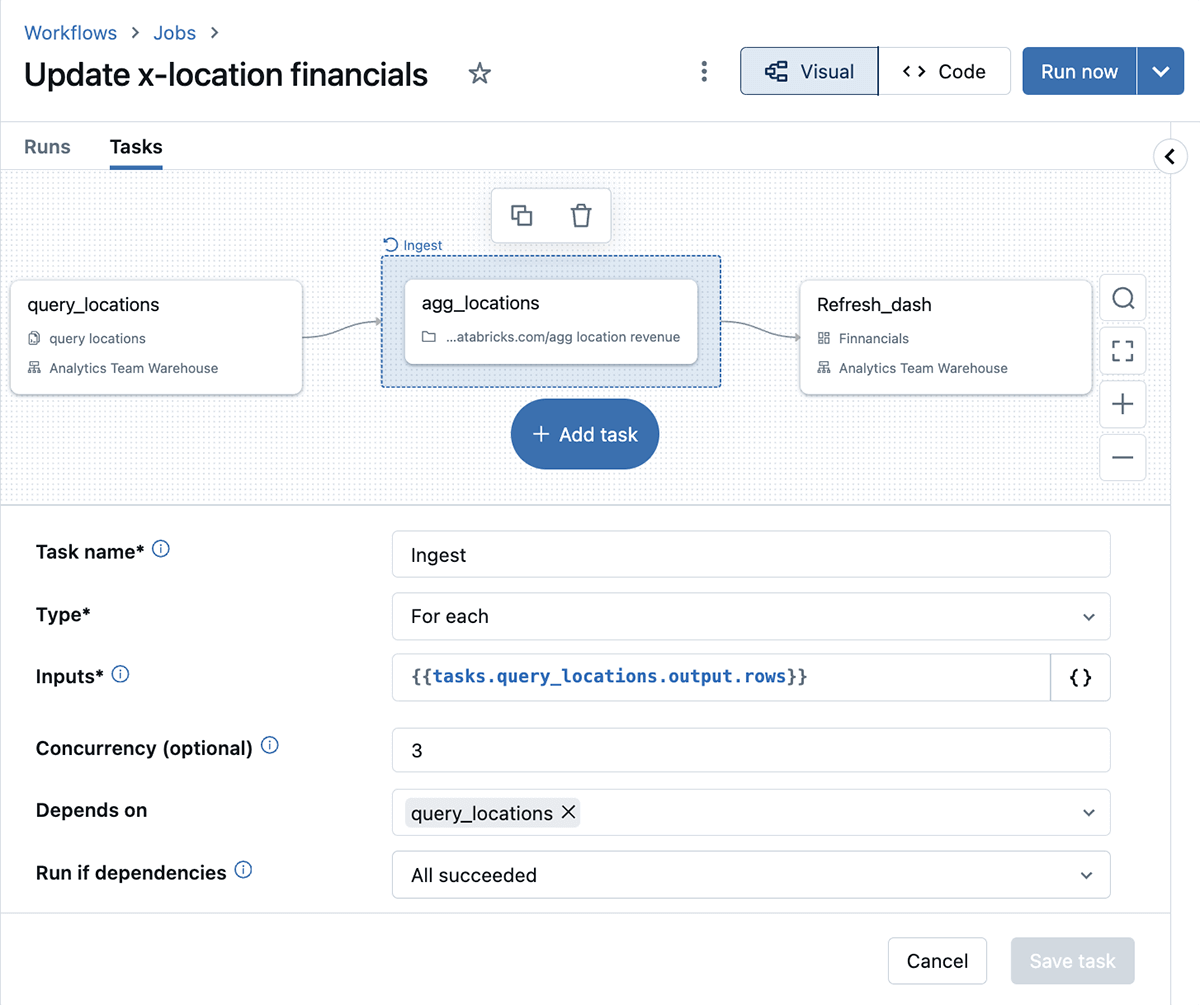
Serverless workflows orchestrate complex business logic using AWS Step Functions. This allows you to create state machines that manage your application’s workflow, making it easy to design and execute long-running processes.
Serverless data lake technologies leverage Amazon SageMaker to build scalable, real-time analytics workloads. With this capability, you can create machine learning models, analyze large datasets, and perform complex queries without worrying about infrastructure.
Serverless notebooks provide a secure, managed environment for data scientists and engineers to develop and deploy AI-powered applications using AWS Glue. This service integrates seamlessly with other AWS services, allowing you to easily build and deploy machine learning models.
- We were thrilled to explore Notebooks, Workflows, and Delta reside tables at DAIS. The performance-focused provisioning was deployed across majority of Databricks regions, enabling seamless access to rapid startup, scalable processing, and hassle-free infrastructure management for streamlined workflows. Serverless compute eliminates the need for intricate configurations, making it significantly easier to manage compared to traditional clustering models.

What’s Subsequent for Databricks Workflows?
Looking ahead, 2024 promises to bring further significant advancements in Databricks Workflows. A glimpse into the future reveals an array of electrifying possibilities and upgrades awaiting us.
Streamlining Workflow Administration
The forthcoming upgrades to Databricks Workflows focus on streamlining complexity and facilitating efficient workflow management. Our objective is to simplify the process of setting up and executing advanced data workflows by developing innovative approaches to building, automating, and repurposing task responsibilities. Our goal is to streamline complex process management, empowering clients to navigate their workflow transformations with greater ease and efficiency as they grow.
Serverless Compute Enhancements
We’re introducing compatibility checks that simplify identifying workloads that would significantly benefit from serverless computing. To further enhance our offerings, we’ll utilize the capabilities of the Databricks Assistant to facilitate seamless transitions for clients moving to serverless computing models.
LakeFlow: Unlocking Seamless Information Engineering with Unified Insights
During the summit, we unveiled a comprehensive information engineering solution consisting of three interconnected components: LakeFlow Join for ingestion, Pipelines for transformation, and Jobs for orchestration. As we progress in evolving Workflows into LakeFlow Jobs, the orchestration enhancements we previously discussed will become integral components of LakeFlow’s orchestration framework.
Streamline Your Workflow with the Latest Innovations?
We’re thrilled to introduce you to our latest innovations in Databricks Workflows. To get began: