

{kind=link}
The ecosystem of retrieval-augmented era (RAG) has taken off within the final couple of years. Increasingly open-source tasks, geared toward serving to builders construct RAG functions, at the moment are seen throughout the web. And why not? RAG is an efficient technique to enhance massive language fashions (LLMs) with an exterior information supply. So we thought, why not share the perfect GitHub repositories for mastering RAG programs with our readers?
However earlier than we try this, here’s a little about RAG and its functions.
RAG pipelines function within the following method:
- The system retrieves paperwork or knowledge,
- Information that’s informative or helpful for the context of finishing that person immediate, and
- The system feeds that context into an LLM to supply a response that’s correct and educated for that context.
As talked about, we are going to discover completely different open-source RAG frameworks and their GitHub repositories right here that allow customers to simply construct RAG programs. The intention is to assist builders, college students, and tech fanatics select an RAG toolkit that fits their wants and make use of it.
Why You Ought to Grasp RAG Techniques
Retrieval-Augmented Era has rapidly emerged as probably the most impactful improvements within the subject of AI. As corporations place increasingly more deal with implementing smarter programs with context consciousness, mastering it’s now not non-obligatory. Firms are using RAG pipelines for chatbots, information assistants, and enterprise automation. That is to make sure that their AI fashions are using real-time, domain-specific knowledge, moderately than relying solely on pre-trained information.
Within the age when RAG is getting used to automate smarter chatbots, assistants, and enterprise instruments, understanding it totally can provide you an ideal aggressive edge. Understanding the best way to construct and optimize RAG pipelines can open up numerous doorways in AI improvement, knowledge engineering, and automation. This shall in the end make you extra marketable and future-proof your profession.
Within the quest for that mastery, listed here are the highest GitHub repositories for RAG programs. However earlier than that, a have a look at how these RAG frameworks truly assist.
What Does the RAG Framework Do?
The Retrieval-Augmented Era (RAG) framework is a sophisticated AI structure developed to enhance the capabilities of LLMs by integrating exterior info into the response era course of. This makes the LLM responses extra knowledgeable or temporally related than the info used when initially establishing the language mannequin. The mannequin can retrieve related paperwork or knowledge from exterior databases or information repositories (APIs). It may then use it to generate responses primarily based on person inquiries moderately than merely counting on the info from the initially skilled mannequin.
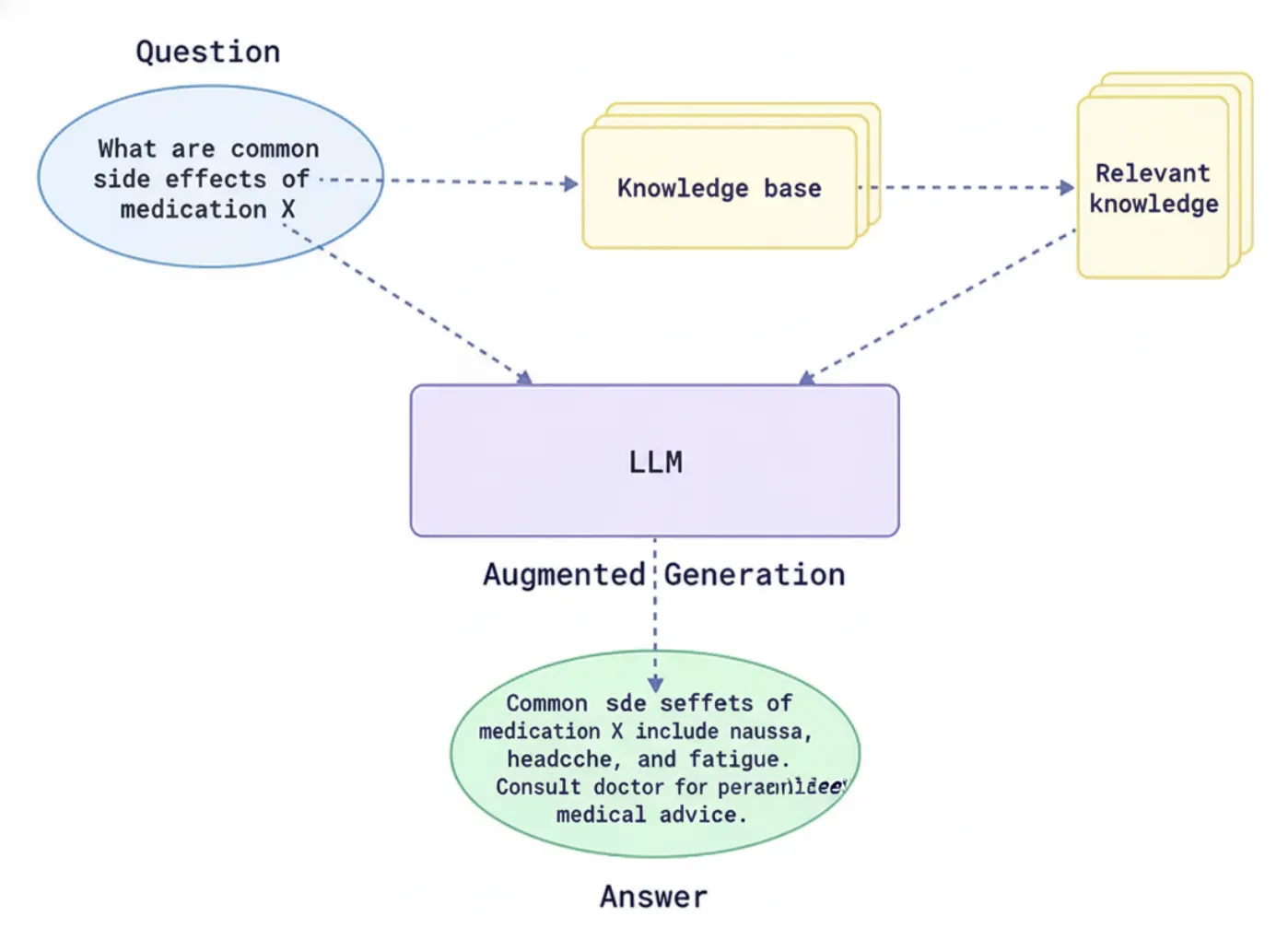
This allows the mannequin to course of questions and develop solutions which are additionally appropriate, date-sensitive, or related to context. In the meantime, they will additionally mitigate points associated to information cut-off and hallucination, or incorrect responses to prompts. By connecting to each basic and domain-specific information sources, RAG permits an AI system to offer accountable, reliable responses.
You’ll be able to learn all about RAG programs right here.
Purposes of this are throughout use instances, like buyer help, search, compliance, knowledge analytics, and extra. RAG programs additionally get rid of the necessity to steadily retrain the mannequin or try to serve particular person person responses via the mannequin being skilled.
High Repositories to Grasp the RAG Techniques
Now that we all know how RAG programs assist, allow us to discover the highest GitHub repositories with detailed tutorials, code, and assets for mastering RAG programs. These GitHub repositories will enable you grasp the instruments, expertise, frameworks, and theories needed for working with RAG programs.
1. LangChain
LangChain is an entire LLM toolkit that allows builders to create refined functions with options equivalent to prompts, reminiscences, brokers, and knowledge connectors. From loading paperwork to splitting textual content, embedding and retrieval, and producing outputs, LangChain offers modules for every step of a RAG pipeline.
LangChain (know all about it right here) boasts a wealthy ecosystem of integrations with suppliers equivalent to OpenAI, Hugging Face, Azure, and plenty of others. It additionally helps a number of languages, together with Python, JavaScript, and TypeScript. LangChain includes a step-by-step process design, permitting you to combine and match instruments, construct agent workflows, and use built-in chains.
- LangChain’s core characteristic set features a instrument chaining system, wealthy immediate templates, and first-class help for brokers and reminiscence.
- LangChain is open-source (MIT license) with an enormous neighborhood (70K+ GitHub stars)
- Parts: Immediate templates, LLM wrappers, vectorstore connectors, brokers (instruments + reasoning), reminiscences, and so on.
- Integrations: LangChain helps many LLM suppliers (OpenAI, Azure, native LLMs), embedding fashions, and vector shops (FAISS, Pinecone, Chroma, and so on.).
- Use Instances: Customized chatbots, doc QA, multi-step workflows, RAG & agentic duties.
Utilization Instance
LangChain’s high-level APIs make easy RAG pipelines concise. For instance, right here we use LangChain to reply a query utilizing a small set of paperwork with OpenAI’s embeddings and LLM:
from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import FAISS from langchain.llms import OpenAI from langchain.chains import RetrievalQA # Pattern paperwork to index docs = ["RAG stands for retrieval-augmented generation.", "It combines search and LLMs for better answers."] # 1. Create embeddings and vector retailer vectorstore = FAISS.from_texts(docs, OpenAIEmbeddings()) # 2. Construct a QA chain (LLM + retriever) qa = RetrievalQA.from_chain_type( llm=OpenAI(model_name="text-davinci-003"), retriever=vectorstore.as_retriever() ) # 3. Run the question outcome = qa({"question": "What does RAG imply?"}) print(outcome["result"])This code takes the docs and hundreds them right into a FAISS vector retailer utilizing OpenAI embeds. It then makes use of RetrievalQA to seize the related context and generate a solution. LangChain abstracts away the retrieval and LLM name. (For added directions, please check with the LangChain APIs and Tutorials.)
For extra, verify the Langchain’s GitHub repository right here.
2. Haystack by deepset-ai
Haystack, by deepset, is an RAG framework designed for an enterprise that’s constructed round composable pipelines. The principle thought is to have a graph-like pipeline. The one by which you wire collectively nodes (i.e, parts), equivalent to retrievers, readers, and mills, right into a directed graph. Haystack is designed for deployment in prod and affords many decisions of backends Elasticsearch, OpenSearch, Milvus, Qdrant, and plenty of extra, for doc storage and retrieval.
- It affords each keyword-based (BM25) and dense retrieval and makes it straightforward to plug in open-source readers (Transformers QA fashions) or generative reply mills.
- It’s open-source (Apache 2.0) and really mature (10K+ stars).
- Structure: Pipeline-centric and modular. Nodes could be plugged in and swapped precisely.
- Parts embody: Doc shops (Elasticsearch, In-Reminiscence, and so on.), retrievers (BM25, Dense), readers (e.g., Hugging Face QA fashions), and mills (OpenAI, native LLMs).
- Ease of Scaling: Distributed setup (Elasticsearch clusters), GPU help, REST APIs, and Docker.
- Attainable Use Instances embody: RAG for search, doc QA, recap functions, and monitoring person queries.
Utilization Instance
Beneath is a simplified instance utilizing Haystack’s trendy API (v2) to create a small RAG pipeline:
from haystack.document_stores import InMemoryDocumentStore from haystack.nodes import BM25Retriever, OpenAIAnswerGenerator from haystack.pipelines import Pipeline # 1. Put together a doc retailer doc_store = InMemoryDocumentStore() paperwork = [{"content": "RAG stands for retrieval-augmented generation."}] doc_store.write_documents(paperwork) # 2. Arrange retriever and generator retriever = BM25Retriever(document_store=doc_store) generator = OpenAIAnswerGenerator(model_name="text-davinci-003") # 3. Construct the pipeline pipe = Pipeline() pipe.add_node(element=retriever, title="Retriever", inputs=[]) pipe.add_node(element=generator, title="Generator", inputs=["Retriever"]) # 4. Run the RAG question outcome = pipe.run(question="What does RAG imply?") print(outcome["answers"][0].reply)This code writes one doc into an in-memory retailer, makes use of BM25 to search out related textual content, then asks the OpenAI mannequin to reply. Haystack’s Pipeline orchestrates the stream. For extra, verify deepset repository right here.
Additionally, take a look at the best way to buildan Agentic QA RAG system utilizing Haystack right here.
3. LlamaIndex
LlamaIndex, previously often called GPT Index, is a data-centric RAG framework targeted on indexing and querying your knowledge for LLM use. Think about LlamaIndex as a set of instruments used to construct customized indexes over paperwork (vectors, key phrase indexes, graphs) after which question them. LlamaIndex is a robust technique to join completely different knowledge sources like textual content recordsdata, APIs, and SQL to LLMs utilizing index constructions.
For instance, you possibly can create a vector index of all your recordsdata, after which use a built-in question engine to reply any questions you might have, all utilizing LlamaIndex. LlamaIndex provides high-level APIs and low-level modules to have the ability to customise each a part of the RAG course of.
- LlamaIndex is open supply (MIT License) with a rising neighborhood (45K+ stars)
- Information connectors: (For PDFs, docs, internet content material), a number of index sorts (vector retailer, tree, graph), and a question engine that lets you navigate effectively.
- Merely plug it into LangChain or different frameworks. LlamaIndex works with any LLM/embedding (OpenAI, Hugging Face, native LLMs).
- LlamaIndex permits you to construct your RAG brokers extra simply by mechanically creating the index after which fetching the context from the index.
Utilization Instance
LlamaIndex makes it very straightforward to create a searchable index from paperwork. For example, utilizing the core API:
from llama_index import VectorStoreIndex, SimpleDirectoryReader # 1. Load paperwork (all recordsdata within the 'knowledge' listing) paperwork = SimpleDirectoryReader("./knowledge").load_data() # 2. Construct a vector retailer index from the docs index = VectorStoreIndex.from_documents(paperwork) # 3. Create a question engine from the index query_engine = index.as_query_engine() # 4. Run a question towards the index response = query_engine.question("What does RAG imply?") print(response)This code will learn recordsdata within the ./knowledge listing, index them in reminiscence, after which question the index. LlamaIndex returns the reply as a string. For extra, verify the Llamindex repository right here.
Or, construct a RAG pipeline utilizing LlamaIndex. Right here is how.
4. RAGFlow
RAGFlow is an RAG engine designed for enterprises from InfiniFlow to accommodate complicated and large-scale knowledge. It refers back to the objective of “deep doc understanding” so as to parse completely different codecs equivalent to PDFs, scanned paperwork, photos, or tables, and summarize them into organized chunks.
RAGFlow options an built-in retrieval mannequin with agent templates and visible tooling for debugging. Key parts are the superior template-based chunking for the paperwork and the notion of grounded citations. It helps with lowering hallucinations as a result of you possibly can know which supply texts help which reply.
- RAGFlow is open-source (Apache-2.0) with a robust neighborhood (65K stars).
- Highlights: parsing of deep paperwork (i.e., breaking down tables, photos, and multi-policy paperwork), doc chunking with template guidelines (customized guidelines for managing paperwork), and citations to point out the best way to doc provenance to reply questions.
- Workflow: RAGFlow is used as a service, which implies you begin a server (utilizing Docker), after which index your paperwork, both via a UI or API. RAGFlow additionally has CLI instruments and Python/REST APIs for constructing chatbots.
- Use Instances: Massive enterprises coping with heavy paperwork and helpful use instances the place code-based traceability and accuracy are a requisite.
Utilization Instance
import requests api_url = "http://localhost:8000/api/v1/chats_openai/default/chat/completions" api_key = "YOUR_RAGFLOW_API_KEY" headers = {"Authorization": f"Bearer {api_key}"} knowledge = { "mannequin": "gpt-4o-mini", "messages": [{"role": "user", "content": "What is RAG?"}], "stream": False } response = requests.publish(api_url, headers=headers, json=knowledge) print(response.json()["choices"][0]["message"]["content"])This instance illustrates the chat completion API of RAGFlow, which is appropriate with OpenAI. It sends a chat message to the “default” assistant, and the assistant will use the listed paperwork as a context. For extra, verify the repository.
5. txtai
txtai is an all-in-one AI framework that gives semantic search, embeddings, and RAG pipelines. It comes with an embeddable vector-searchable database, stemming from SQLite+FAISS, and utilities that will let you orchestrate LLM calls. With txtai, after you have created an Embedding index utilizing your textual content knowledge, it’s best to both be a part of it to an LLM manually within the code or use the built-in RAG helper.
What I actually like about txtai is its simplicity: it will probably run 100% regionally (no cloud), it has a template in-built for a RAG pipeline, and it even offers autogenerated FastAPI providers. It’s also open supply (Apache 2.0), straightforward to prototype and deploy.
- Open-source (Apache-2.0, 7K+ stars) Python bundle.
- Capabilities: Semantic search index (vector DB), RAG pipeline, and FastAPI service era.
- RAG help: txtai has a RAG class, taking in an Embeddings occasion and an LLM, which mechanically glues the retrieved context into LLM prompts for you.
- LLM flexibility: Use OpenAI, Hugging Face transformers, llama.cpp, or any mannequin you need with your individual LLM interface.
You’ll be able to learn extra about txtai right here.
Utilization Instance
Right here’s how easy it’s to run a RAG question in txtai utilizing the built-in pipeline:
from txtai import Embeddings, LLM, RAG # 1. Initialize txtai parts embeddings = Embeddings() # makes use of a neighborhood FAISS+SQLite by default embeddings.index([{"id": "doc1", "text": "RAG stands for retrieval-augmented generation."}]) llm = LLM("text-davinci-003") # or any mannequin # 2. Create a RAG pipeline immediate = "Reply the query utilizing solely the context under.nnQuestion: {query}nContext: {context}" rag = RAG(embeddings, llm, template=immediate) # 3. Run the RAG question outcome = rag("What does RAG imply?", maxlength=512) print(outcome["answer"])This code snippet takes a single doc and runs a RAG pipeline. The RAG helper manages the retrieval for related passages from the vector index and fill {context} within the immediate template. It can will let you wrap your RAG pipeline code in layer of construction with APIs and no-code UI. Cognita does use LangChain/LlamaIndex modules underneath the hood, however organizes them with construction: knowledge loaders, parsers, embedders, retrievers, and metric modules. For extra, verify the repository right here.
6. LLMWare
LLMWare is an entire RAG framework that has a robust deviation in direction of “smaller” specialised mannequin inference that’s safe and sooner. Most frameworks use a big cloud LLM. LLMWare runs desktop RAG pipelines with the required computing energy on a desktop or native server. It limits the chance of knowledge publicity whereas nonetheless using safe LLMs for large-scale pilot research and numerous functions.
LLMWare has no-code wizards and templates for the standard RAG performance, together with the performance of doc parsing and indexing. It additionally has tooling for numerous doc codecs (Workplace and PDF) which are helpful first steps for the cognitive AI performance to doc evaluation.
- Open supply product (Apache-2.0, 14K+ stars) for enterprise RAG
- An strategy that focuses on “smaller” LLMs (Ex: Llama 7B variants) and inference runs on a tool whereas providing RAG functionalities even on ARM units
- Tooling: providing CLI and REST APIs, interactive UIs, and pipeline templates
- Distinctive Traits: preconfigured pipelines, built-in capabilities for fact-checking, and plugin options for vector search and Q&As.
- Examples: enterprises pursuing RAG however can’t ship knowledge to the cloud, e.g. monetary providers, healthcare, or builders of cell/edge AI functions.
Utilization Instance
LLMWare’s API is designed to be straightforward. Right here’s a fundamental instance primarily based on their docs:
from llmware.prompts import Immediate from llmware.fashions import ModelCatalog # 1. Load a mannequin for prompting prompter = Immediate().load_model("llmware/bling-tiny-llama-v0") # 2. (Optionally) index a doc to make use of as context prompter.add_source_document("./knowledge", "doc.pdf", question="What's RAG?") # 3. Run the question with context response = prompter.prompt_with_source("What's RAG?") print(response)This code makes use of an LLMWare Immediate object. We first specify a mannequin (for instance, a small Llama mannequin from Hugging Face). We then add a folder that incorporates supply paperwork. LLMWare parses “doc.pdf” into chunks and filters primarily based on relevance to the person’s query. The prompt_with_source perform then makes a request, passing the related context from the supply. This returns a textual content reply and metadata response. For extra, verify the repository right here.
7. Cognita
Cognita by TrueFoundary is a production-ready RAG framework constructed for scalability and collaboration. It’s primarily about making it straightforward to go from a pocket book or experiment to deployment/service. It helps incremental indexing and has an internet UI for non-developers to strive importing paperwork, choosing fashions, and querying them in actual time.
- That is open supply (Apache-2.0)
- Structure: Totally API-based and containerized, it will probably run absolutely regionally via Docker Compose (together with the UI).
- Parts: Reusable libraries for parsers, loaders, embedders, retrievers, and extra. Every thing could be personalized and scaled.
- UI – Extensibility: An internet frontend is offered for experimentation and a “mannequin gateway” to handle the LLM/embedder configurations. This helps when each the developer and the analyst work collectively to construct out RAG pipeline parts.
Utilization Instance
Cognita is primarily accessed via its command-line interface and inside API, however it is a conceptual pseudo snipped utilizing its Python API:
from cognita.pipeline import Pipeline from cognita.schema import Doc # Initialize a brand new RAG pipeline pipeline = Pipeline.create("rag") # Add paperwork (with textual content content material) docs = [Document(id="1", text="RAG stands for retrieval-augmented generation.")] pipeline.index_documents(docs) # Question the pipeline outcome = pipeline.question("What does RAG imply?") print(outcome['answer'])In an actual implementation, you’ll use YAML to configure Cognita or use its CLI as an alternative to load the info and kick off a service. The earlier snippet describes the stream: you create a pipeline, index your knowledge, then ask questions. Cognita documentation has extra particulars. For extra, verify the whole documentation right here. This returns a textual content reply and metadata response. For extra, verify the repository right here.
Conclusion
These open-source GitHub repositories for RAG programs provide in depth toolkits for builders, researchers, and hobbyists.
- LangChain and LlamaIndex provide versatile APIs for establishing personalized pipelines and indexing options.
- Haystack affords NLP pipelines which are examined in manufacturing with respect to the scalability of knowledge ingestion.
- RAGFlow and LLMWare handle enterprise wants, with LLMWare considerably restricted to on-device fashions and safety.
- In distinction, txtai affords a light-weight, easy, all-in-one native RAG resolution, whereas Cognita takes care of all the pieces with a simple, modular, UI pushed platform.
All the GitHub repositories meant for RAG programs above are maintained and include examples that can assist you run simply. They collectively exhibit that RAG is now not on the innovative of educational analysis, however is now out there to everybody who needs to construct an AI utility. In observe, the “most suitable choice” depends upon your wants and priorities.
Hi there! I am Vipin, a passionate knowledge science and machine studying fanatic with a robust basis in knowledge evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy knowledge, and fixing real-world issues. My objective is to use data-driven insights to create sensible options that drive outcomes. I am wanting to contribute my expertise in a collaborative setting whereas persevering with to study and develop within the fields of Information Science, Machine Studying, and NLP.
Login to proceed studying and revel in expert-curated content material.